Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao
Linjun Yang, Daxin Jiang, Rangan Majumder, Furu Wei
Microsoft Corporation
https://github.com/microsoft/unilm
Abstract
This paper presents E5 [^1], a family of state-of-the-art text embeddings that transfer well to a wide range of tasks. The model is trained in a contrastive manner with weak supervision signals from our curated large-scale text pair dataset (called CCPairs). E5 can be readily used as a general-purpose embedding model for any tasks requiring a single-vector representation of texts such as retrieval, clustering, and classification, achieving strong performance in both zero-shot and fine-tuned settings. We conduct extensive evaluations on $56$ datasets from the BEIR and MTEB benchmarks. For zero-shot settings, E5 is the first model that outperforms the strong BM25 baseline on the BEIR retrieval benchmark without using any labeled data. When fine-tuned, E5 obtains the best results on the MTEB benchmark, beating existing embedding models with $40\times$ more parameters.
[^1]: E5: EmbEddings from bidirEctional Encoder rEpresentations
Executive Summary: ### Context and Problem
In today's data-driven world, organizations handle massive amounts of text, from web pages and social media to scientific papers and customer queries. A key challenge is converting this text into compact vector representations, known as text embeddings, that capture meaning for tasks like search, clustering similar documents, or classifying content. Traditional methods, such as the keyword-based BM25 algorithm, work well but struggle with semantic nuances, like understanding synonyms or context. Recent advances in language models offer denser embeddings, yet they often require vast labeled data for training or produce suboptimal results without it, limiting their use in real-world applications where data labeling is costly or scarce. With exploding text volumes and demands for efficient AI tools, there is an urgent need for versatile, high-quality embeddings that perform strongly without heavy customization, enabling faster and more accurate information retrieval and analysis.
Objective
This work introduces E5, a new family of text embedding models designed to generate effective vector representations for any text-based task. The goal is to demonstrate that E5 can excel in zero-shot scenarios—where no task-specific training occurs—and when lightly fine-tuned, outperforming existing models across diverse benchmarks.
Approach
The researchers created CCPairs, a large dataset of about 270 million text pairs drawn from web sources like Reddit posts and comments, Stack Exchange questions and answers, Wikipedia sections, scientific abstracts, and Common Crawl web pages. They filtered this data aggressively using a consistency check: after initial training on noisy pairs, they retained only those that the model ranked highly against random alternatives, ensuring quality without human labels. E5 models, in small, base, and large sizes (initialized from pre-trained transformers like BERT), were then trained via contrastive learning. This method pulls related text pairs closer in vector space while pushing unrelated ones apart, using simple in-batch negatives from large training batches of up to 32,000 examples. An optional fine-tuning step used small labeled datasets for tasks like question answering and natural language inference, covering about 1 million examples over three epochs. Credibility stems from evaluations on established benchmarks: BEIR, with 15 retrieval datasets, and MTEB, spanning 56 English datasets across classification, clustering, similarity, and more, tested over recent years without data leakage.
Key Findings
The most significant result is that the base E5 model, without any labeled data (zero-shot), outperforms the BM25 baseline on the BEIR retrieval benchmark by 1.2 points in average normalized discounted cumulative gain (nDCG@10), marking the first time an unsupervised embedding model has achieved this across 15 diverse datasets. Scaling to the large E5 version boosts this to 44.2 points, a 1.3-point gain over the base. After fine-tuning on limited labeled data, the base E5 reaches 48.7 on BEIR, surpassing larger rivals like GTR-large. On the broader MTEB benchmark, fine-tuned base E5 scores 60.4 overall, competitive with top models like GTR-xxl and Sentence-T5-xxl that have 40 times more parameters (4.8 billion versus 110 million). Pre-training on CCPairs alone yields strong zero-shot results, such as 55.6 on MTEB, while fine-tuning adds up to 4.8 points, especially in retrieval (from 42.9 to 50.3) and similarity tasks.
Implications and Interpretation
These findings show that high-quality text embeddings can be built with mostly unlabeled web data, reducing dependence on expensive annotations and massive models, which cuts training costs and speeds deployment. E5 addresses lexical gaps in traditional search by better capturing semantic meaning, improving accuracy in applications like web search engines or recommendation systems by 1-5 points over baselines, potentially lowering risks of missing relevant information. Unlike prior unsupervised methods that fell short of BM25, E5 exceeds expectations here due to curated data diversity, offering reliable performance across tasks without domain-specific tweaks. However, it underperforms in niche areas like fact verification or long-document retrieval, where exact keyword matching still dominates, highlighting that dense embeddings complement rather than fully replace sparse methods.
Recommendations and Next Steps
Leaders should integrate E5 into systems for text retrieval, similarity scoring, or zero/few-shot classification, starting with the base model for its balance of performance and efficiency—deploy via the open-source GitHub repository for quick testing. For high-stakes uses like legal search, fine-tune on domain-specific data using the provided recipe, combining natural language inference and retrieval datasets for balanced gains. If options arise, prioritize the large model for superior results at higher compute cost, or stick to pre-trained versions to avoid fine-tuning overhead. Further work is essential: pilot E5 in production pipelines to validate real-world gains, then scale to multilingual data or hybrid BM25-E5 setups for long-tail domains. Additional analysis on non-English datasets would strengthen generalizability.
Limitations and Confidence
While robust, E5 relies on English-centric web data, limiting transfer to other languages, and assumes texts fit within 512 tokens, potentially truncating long documents. Filtering reduced noise but may overlook rare edge cases, and results depend on benchmark assumptions like no data contamination. Confidence is high for general retrieval and similarity tasks, backed by consistent wins on 71 datasets, but exercise caution in specialized fields like science or exact-match scenarios, where BM25 remains safer until hybrid improvements emerge.
1. Introduction
Section Summary: Text embeddings are compact numerical representations of text that help computers understand and search through large amounts of information more effectively than older methods like TF-IDF, which struggle with matching words that mean the same thing but are phrased differently. While advanced language models like BERT and GPT provide useful text representations, they often require tweaks for tasks needing a single, efficient vector per text, and existing training approaches either rely on limited real data or low-quality artificial pairs that don't always outperform simple search tools. This paper introduces E5, a versatile embedding model trained on a massive, high-quality dataset of text pairs gathered from websites, question-answer forums, and research papers, using a straightforward contrastive learning technique; it beats traditional search baselines in zero-shot scenarios and rivals much larger models when fine-tuned, as shown in extensive tests across benchmarks.
Text embeddings are low-dimensional vector representations for arbitrary-length texts and play key roles in many NLP tasks such as large-scale retrieval. Compared to the high-dimensional and sparse representations like TF-IDF, text embeddings have the potential to overcome the lexical mismatch issue and facilitate efficient retrieval and matching between texts. It also offers a versatile interface easily consumable by downstream applications.
While pre-trained language models such as BERT ([1]) and GPT ([2]) can produce transferrable text representations, they are not ideal for tasks such as retrieval and text matching where a single-vector embedding of texts is more desired due to its efficiency and versatility. To obtain better text embeddings, contrastive learning is often the go-to framework to enhance the sequence-level representations from text pairs. Along this line of research, some works are geared towards learning task-specific embeddings. For example, GTR ([3]) and Sentence-T5 ([4]) fine-tune pre-trained models with supervised datasets to learn embeddings customized for passage retrieval and semantic textual similarity, respectively. Other works learn unsupervised embeddings from automatically constructed text pairs. Typical methods to construct text pairs include Inverse Close Task (ICT) ([5]), random cropping ([6]) and neighboring text spans ([7]), etc. While such synthetic data are of unlimited quantity, they are often poor in quality and the resulted embeddings fail to match the performance of the classic BM25 baseline without further fine-tuning ([8]).
In this work, we learn a high-quality general-purpose text embedding termed E5, EmbEddings from bidirEctional Encoder rEpresentations. E5 aims to provide strong off-the-shelf text embeddings suitable for any tasks requiring single-vector representations in both zero-shot or fine-tuned settings. To achieve this goal, instead of relying on limited labeled data or low-quality synthetic text pairs, we contrastively train E5 embeddings from CCPairs, a curated web-scale text pair dataset containing heterogeneous training signals. We construct the CCPairs dataset by combining various semi-structured data sources such as CommunityQA, Common Crawl and Scientific papers, and perform aggressive filtering with a consistency-based filter ([9]) to improve data quality. We choose a simple contrastive learning recipe using in-batch negatives with a large batch-size to train our model. Extensive experiments on both BEIR and MTEB benchmarks demonstrate the effectiveness of the proposed method. On the BEIR zero-shot retrieval benchmark ([10]), E5 is the first model to outperform the strong BM25 baseline without using any labeled data. When fine-tuned on labeled datasets, the performance can be further improved. Results on $56$ datasets from the recently introduced MTEB benchmark ([8]) show that our E5 $\text{base}$ is competitive against GTR $\text{xxl}$ and Sentence-T5 $_\text{xxl}$, which have $40\times$ more parameters.
2. Related Work
Section Summary: Researchers have long explored ways to convert text into compact numerical representations, starting with techniques like Latent Semantic Indexing and Latent Dirichlet Allocation that analyze word patterns in documents, and evolving to advanced pre-trained language models fine-tuned for sentence embeddings, such as Sentence-BERT and SimCSE, which excel especially for short texts using contrastive learning. For longer documents and tasks like retrieval, self-supervised methods like inverse cloze tasks generate training data automatically, though they often fall short without high-quality labeled examples, and evaluations on benchmarks like BEIR and MTEB reveal no single model dominates all scenarios. This work builds on community efforts like sentence-transformers by showing that purely self-supervised pre-training can produce strong embeddings, outperforming others when fine-tuned on minimal labeled data.
There have been long-lasting interests in transforming texts into low-dimensional dense embeddings. Early works include Latent Semantic Indexing (LSA) ([11]) and Latent Dirichlet Allocation (LDA) ([12]). LSA utilizes the decomposition of a word-document co-occurrence matrix to generate document embeddings, while LDA adopts probabilistic graphical models to learn topic distributions. [13] show that a simple weighted average of word vectors ([14]) can be a strong baseline for sentence embeddings.
With the development of pre-trained language models ([1, 15, 16]) and large-scale labeled datasets such as SNLI ([17]) and MS-MARCO ([18]), methods like Sentence-BERT ([19]), SimCSE ([20]), Sentence-T5 ([4]) and SGPT ([21]) directly fine-tune language models to output continuous embeddings. Most research focuses on short texts and thus uses the term "sentence embeddings". For long documents, it remains an open research question whether fixed-length embeddings can encode all the information. Contrastive loss popularized by SimCLR ([22]) turns out to be more effective than classification-based losses ([19, 23]) for embeddings. LaBSE ([24]), LASER ([25]) and CLIP ([26]) further extend to multilingual and multi-modal scenarios using parallel sentences and image-text pairs.
Another direction is to design self-supervised pre-training tasks for text matching and retrieval. ([5]) proposes the well-known inverse cloze task (ICT), where a random sentence within a passage is chosen as a pseudo-query and the rest is treated as a positive sample. However, Contriever ([6]) shows that random cropping with data augmentation is more effective than ICT on a range of zero-shot information retrieval tasks. OpenAI text embeddings ([7]) use neighboring texts as positives and scale up the model size to $175$ B. [27] performs domain-matched pre-training to improve in-domain results. SPAR ([28]) trains a dense retriever by treating BM25 as a teacher model. Although the aforementioned approaches can easily obtain abundant supervision signals, such synthetic data tend to be of low quality. Results on the BEIR benchmark ([10]) show they struggle to match the performance of BM25 if not further fine-tuned on labeled datasets.
Evaluation and interpretation of text embeddings are also non-trivial. Most benchmarks measure the embedding quality through downstream task performances. For example, SentEval ([29]) uses linear probing and a collection of semantic textual similarity (STS) datasets, while the BEIR benchmark ([10]) focuses on zero-shot information retrieval scenarios. The recently introduced MTEB benchmark ([8]) combines $56$ datasets spanning across $8$ tasks and $112$ languages. Experiments show no model can achieve state-of-the-art results on all embedding tasks yet. In this paper, we do not use the SentEval toolkit since its linear probing setup depends on the optimization hyperparameters.
Most closely related to our work is a series of community efforts by sentence-transformers ^2 to train embeddings with a collection of labeled and automatically collected datasets. In this paper, we show that it is possible to train high-quality embeddings using self-supervised pre-training only. In terms of benchmark results, our model can achieve superior performance when fine-tuned on less labeled data.
3. CCPairs: A Large Collection of Text Pair Dataset
Section Summary: Researchers have created CCPairs, a massive collection of high-quality text pairs designed to train better text embedding models that understand language effectively across various tasks. They gathered this data from online sources like Reddit comments, Stack Exchange answers, Wikipedia entries, scientific paper abstracts, and web pages from Common Crawl and news sites, starting with about 1.3 billion pairs after basic cleaning rules to remove junk. To refine it further, they trained a model on the initial set and kept only the top-scoring 270 million pairs that showed consistent strong matches, ensuring the data is clean and useful for training.
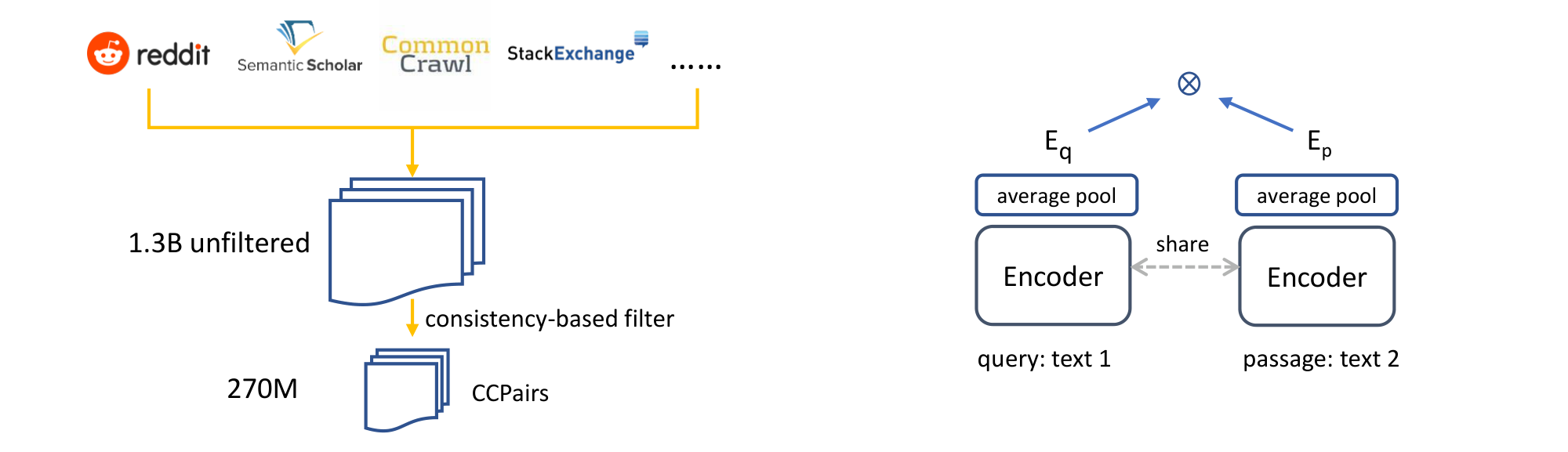
The quality and diversity of the data is crucial for training general-purpose text embeddings. In this work, we mine and assemble CCPairs, a large high-quality text pair dataset from web sources which provide diverse training signals transferring well to a wide range of tasks.
Harvesting semi-structured data sources Large-scale high-quality datasets like C4 ([16]) and CCMatrix ([30]) are vital for the success of language model pre-training and machine translation. For learning text embeddings, existing works either utilize small-scale human-annotated data such as NLI ([20]) and MS-MARCO ([18]) or adopt heuristics such as random cropping ([6]) to obtain large-scale but very noisy supervision signals.
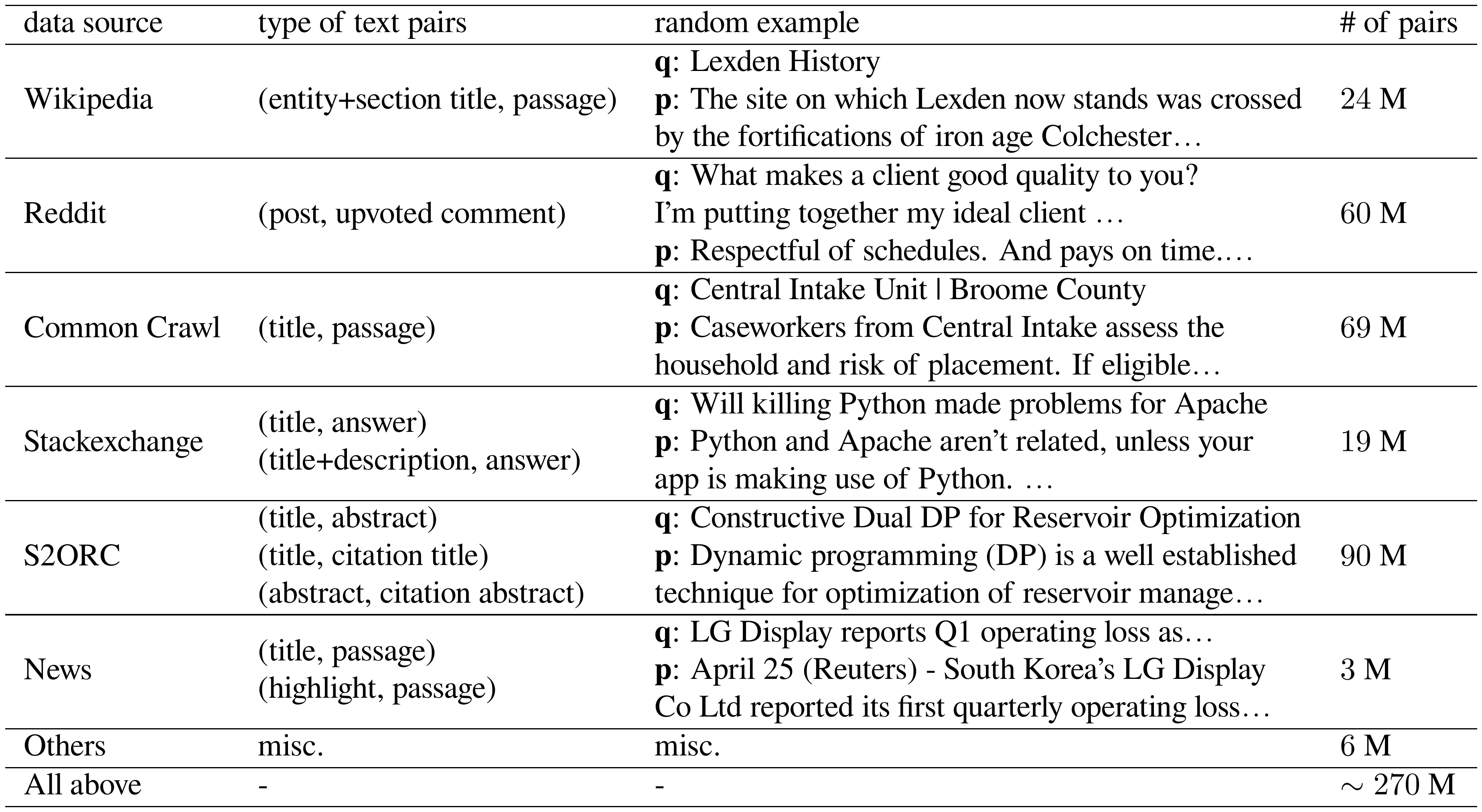
Instead, we curate a text pair dataset CCPairs (Colossal Clean text Pairs) by harvesting heterogeneous semi-structured data sources. Let ($q$, $p$) denote a text pair consisting of a query $q$ and a passage $p$. Here we use "passage" to denote word sequences of arbitrary length, which can be a short sentence, a paragraph, or a long document. Our dataset includes (post, comment) pairs from Reddit ^3, (question, upvoted answer) pairs from Stackexchange ^4, (entity name + section title, passage) pairs from English Wikipedia, (title, abstract) and citation pairs from Scientific papers ([31]), and (title, passage) pairs from Common Crawl ^5 web pages and various News sources.
We only include data sources that can be automatically mined, and some subsets are directly reused from existing datasets. Simple heuristic rules are applied to filter data from Reddit and Common Crawl. For example, we remove Reddit comments that are either too long (
gt; 4096$ characters) or receive score less than $1$, and remove passages from web pages with high perplexity ([32]). After preliminary filtering, we end up with $\sim1.3$ billion text pairs, most of which come from Reddit and Common Crawl. For more details and examples, please refer to Appendix A.Consistency-based filter To further improve data quality and make training costs manageable, we propose a consistency-based data filtering technique: a model is first trained on the $1.3$ B noisy text pairs, and then used to rank each pair against a pool of $1$ million random passages. A text pair is kept only if it falls in the top- $k$ ranked lists. In other words, the model's prediction should be consistent with the training labels. Here we set $k = 2$ based on manual inspection of data quality. After this step, we end up with $\sim270$ M text pairs for contrastive pre-training.
The intuition for this technique comes from the memorization behaviors of neural networks ([33]): when trained on noisy datasets, neural networks tend to memorize the clean labels first and then gradually overfit the noisy labels. Similar techniques ([34, 9, 35]) have been widely used for removing dataset noises. It is also possible to apply this filter iteratively, we will leave it for future work.
4. Method
Section Summary: The method trains text embeddings using unlabeled pairs from a dataset called CCPairs through a contrastive pre-training process, which helps the model learn to distinguish relevant text matches from irrelevant ones by comparing similarities within batches. This is followed by an optional fine-tuning step on small labeled datasets from tasks like natural language inference and question answering, incorporating techniques such as hard negative examples and guidance from a more advanced teacher model to enhance accuracy. The resulting embeddings can then be applied directly to tasks like searching documents, classifying text with few or no examples, measuring similarity between sentences, or grouping related texts without further adjustments.
Our embeddings can be trained with only unlabeled text pairs from CCPairs with contrastive pre-training. A second-stage fine-tuning on small, high-quality labeled datasets can be performed to further boost the quality of the resulted embeddings. See Figure 1 for an overview.
4.1 Contrastive Pre-training with Unlabeled Data
Contrastive pre-training aims to distinguish the relevant text pairs from other irrelevant or negative pairs. Given a collection of text pairs ${(q_i, p_i)}{i=1}^n$, we assign a list of negative passages ${p{ij}^-}_{j=1}^m$ for the $i$-th example. Then the InfoNCE contrastive loss ([22]) is as follows:
$ \min\ \ L_\text{cont} = -\frac{1}{n} \sum_i \log \frac{\text{e}^{s_{\boldsymbol \theta} (q_i, p_i)}}{\text{e}^{s_{\boldsymbol \theta} (q_i, p_i)}+\sum_j \text{e}^{s_{\boldsymbol \theta} (q_i, p_{ij}^-)} }\tag{1} $
where $s_{\boldsymbol \theta}(q, p)$ is a scoring function between query $q$ and passage $p$ parameterized by $\boldsymbol \theta$. Following the popular biencoder architecture, we use a pre-trained Transformer encoder and average pooling over the output layer to get fixed-size text embeddings $\mathbf{E}_q$ and $\mathbf{E}_p$. The score is the cosine similarity scaled by a temperature hyperparameter $\tau$:
$ s_{\boldsymbol \theta}(p, q) = \text{cos(}\mathbf{E}_q\text{, } \mathbf{E}_p\text{)}\ /\ \tau $
Where $\tau$ is set to $0.01$ in our experiments by default. We use a shared encoder for all input texts and break the symmetry by adding two prefix identifiers "query:" and "passage:" to $q$ and $d$ respectively. For some data sources such as citation pairs, it is not obvious which side should be the query, we randomly choose one for simplicity. Such an asymmetric design turns out to be important for some retrieval tasks where there exist paraphrases of the query in the target corpus.
Another critical issue for contrastive training is how to select the negative samples. Here we choose to use the in-batch negatives ([22]), where the passages from other pairs in a batch serve as negative samples. We find that this simple strategy enables more stable training and outperforms methods such as MoCo ([36]) when the batch size is sufficiently large.
4.2 Fine-tuning with Labeled Data
While contrastive pre-training on the CCPairs provides a solid foundation for general-purpose embeddings, further training on labeled data can inject human knowledge into the model to boost the performance. Although these datasets are small, existing works ([3, 4]) have shown that supervised fine-tuning leads to consistent performance gains. In this paper, we choose to further train with a combination of 3 datasets: NLI [^6] (Natural Language Inference), MS-MARCO passage ranking dataset ([18]), and NQ (Natural Questions) dataset ([37, 38]). Empirically, tasks like STS (Semantic Textual Similarity) and linear probing benefit from NLI data, while MS-MARCO and NQ datasets transfer well to retrieval tasks.
[^6]: The version released by SimCSE.
Building on the practices of training state-of-the-art dense retrievers ([39, 40]), we use mined hard negatives and knowledge distillation from a cross-encoder (CE) teacher model for the MS-MARCO and NQ datasets. For the NLI dataset, contradiction sentences are regarded as hard negatives. The loss function is a linear interpolation between contrastive loss $L_\text{cont}$ for hard labels and KL divergence $D_\text{KL}$ for distilling soft labels from the teacher model.
$ \min\ \ D_{\text{KL}}(p_\text{ce}, p_\text{stu}) + \alpha L_\text{cont} $
Where $p_\text{ce}$ and $p_\text{stu}$ are the probabilities from the cross-encoder teacher model and our student model. $\alpha$ is a hyperparameter to balance the two loss functions. $L_\text{cont}$ is the same as in Equation 1.
4.3 Applications to Text Embedding Tasks
After the above two steps, we obtain high-quality text embeddings transferring well to a wide range of tasks without fine-tuning the model parameters. Combined with techniques like approximate nearest neighbor search, embeddings provide a scalable and efficient solution for applications like web search. Here we briefly illustrate several use cases of our text embeddings.
Zero-shot Retrieval First, the passage embeddings for the target corpus are computed and indexed offline. Then for each query, we compute its query embedding and return the top- $k$ ranked lists from the corpus based on cosine similarity.
Few-shot Text Classification A linear classifier is trained on top of the frozen embeddings with a few labeled examples. Different tasks only need to train and save the parameters of the classification heads. It can be seen as a particular form of parameter-efficient learning ([41]).
Zero-shot Text Classification The input and label texts are converted to sentences based on manually written prompt templates. The predicted label is the one closest to the input text in the embedding space. Take the sentiment classification of movie reviews as an example, with the original input "I enjoy watching it", the label text is "it is an example of terrible/great movie review" and the input text becomes "movie review: I enjoy watching it".
Semantic Textual Similarity Given two text embeddings, we use the cosine function to measure their semantic similarity. Since the absolute similarity scores do not enable an easy interpretation, the evaluation is usually based on rank correlation coefficients.
Text Clustering Standard clustering algorithms such as k-means can be applied straightforwardly. Texts belonging to the same category are expected to be close in the embedding space.
For tasks other than zero-shot text classification and retrieval, we use the query embeddings by default.
5. Experiments
Section Summary: The experiments involve pre-training and fine-tuning E5 models of varying sizes on custom text pair datasets and a mix of retrieval tasks, then evaluating them on the BEIR benchmark for information retrieval and the MTEB benchmark for broader text embedding tasks like classification and clustering. On BEIR, the unsupervised E5 base model outperforms the traditional BM25 search algorithm for the first time, while the supervised version achieves strong zero-shot results across diverse datasets, surpassing larger rivals. On MTEB, the E5 large model excels over similarly sized competitors and rivals much bigger models despite being over ten times smaller.
5.1 Pre-training and Fine-tuning Configurations
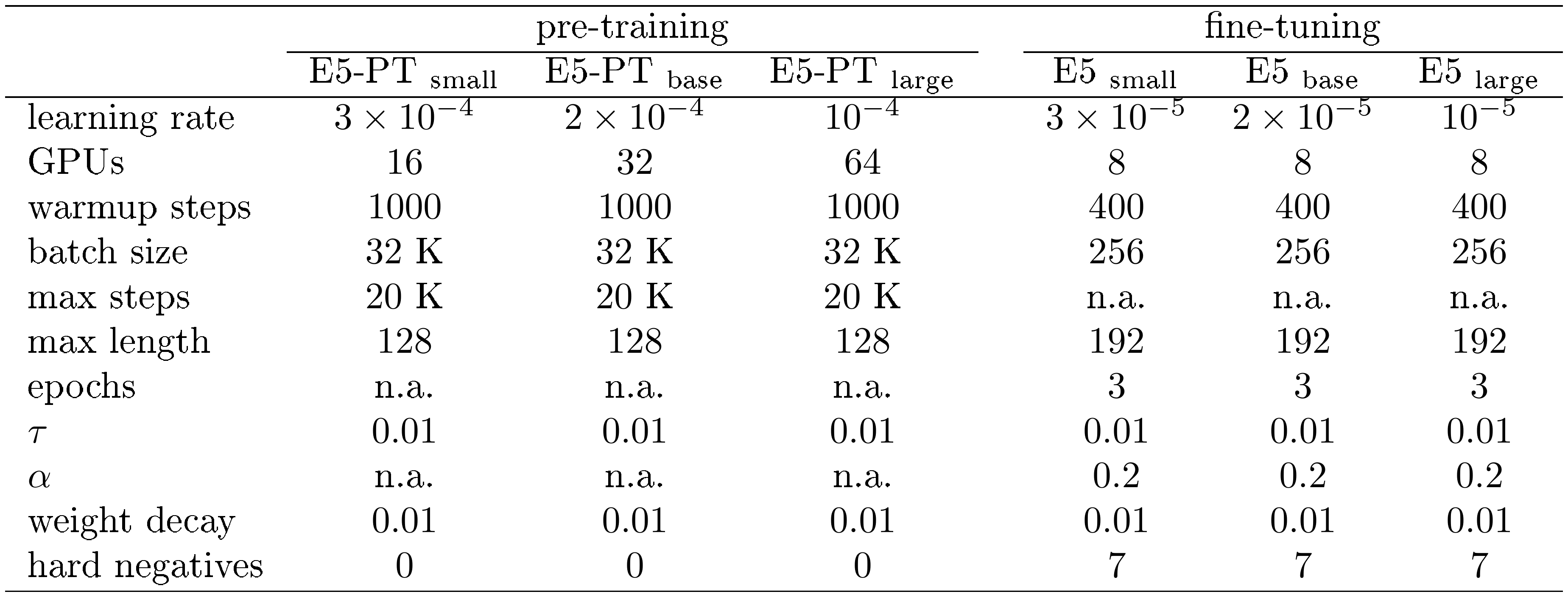
Pre-training We pre-train on our proposed text pair dataset for three model sizes: E5 $\text{small}$, E5 $\text{base}$ and E5 $_\text{large}$ initialized from MiniLM ([42]), bert-base-uncased, and bert-large-uncased-whole-word-masking respectively. The batch size is set to a large value of $32, 768$ to increase the number of negatives. The learning rate is $3, 2, 1$ $\times10^{-4}$ for the small, base, large models, with linear decay and the first $1, 000$ steps for warmup. We pre-train for $20k$ steps in total with AdamW optimizer, which is approximately $2.5$ epochs over the dataset. It takes $16, 32, 64$ V100 GPUs and $1, 1, 2$ days for the small, base, large models. To improve training efficiency and reduce GPU memory usage, we adopt mixed precision training and gradient checkpointing.
Fine-tuning is performed on the concatenation of $3$ datasets: MS-MARCO passage ranking ([18]), NQ ([38, 37]), and NLI ([20]) datasets. We reuse the mined hard negatives and re-ranker scores from SimLM ([40]) for the first two datasets. Models are fine-tuned for $3$ epochs with batch size $256$ on $8$ GPUs. Learning rate is $3, 2, 1$ $\times10^{-5}$ for the small, base, large models with $400$ steps warmup. For each example, we use $7$ hard negatives. Since the NLI dataset only has $1$ hard negative for each example, $6$ sentences are randomly sampled from the entire corpus.
We use E5-PT to denote models with contrastive pre-training only. More implementation details can be found in Appendix B.
5.2 Evaluation Datasets
BEIR Benchmark ([10]) is a collection of $19$ information retrieval datasets, ranging across ad-hoc web search, question answering, fact verification and duplicate question retrieval, etc. We evaluate the $15$ datasets that provide public downloads. The main metric is nDCG@ $10$.
MTEB Benchmark ([8]) is recently proposed for benchmarking massive text embedding tasks. Though MTEB is multilingual due to the inclusion of bitext mining datasets, most datasets are still only available in English. In this paper, we evaluate the English subsets, which have $56$ datasets spanning across $6$ categories: Classification (Class.), Clustering (Clust.), Pair Classification (PairClass.), Rerank, Retrieval (Retr.), STS, and Summarization (Summ.). The evaluation metrics are accuracy, v-measure, average precision, MAP, nDCG@10, and Spearman coefficients, respectively. Please refer to the MTEB paper for details.
5.3 Results on BEIR benchmark
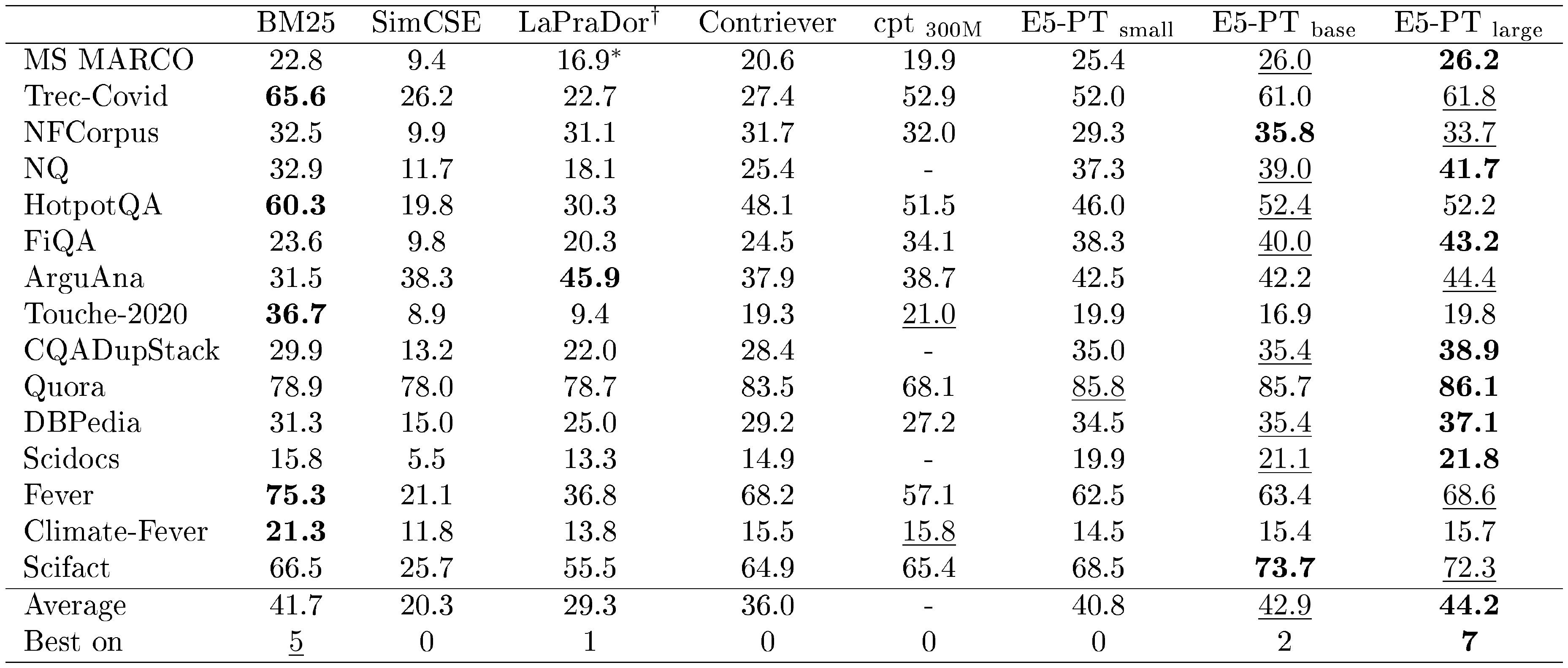
::: {caption="Table 1: Unsupervised methods on the BEIR benchmark (nDCG@ $10$). For SimCSE, we report results with BERT $\text{base}$. cpt ${\text{300M}}$ ([7]) is only available through paid API and evaluation results on some datasets are missing in the original paper. The highest number for each dataset is in bold, and the second highest is underlined. $\dagger$ : we report the LaPraDor ([43]) results without ensembling with BM25. $*$ : reproduction with the released checkpoint."}
:::
Results with Unsupervised Methods In Table 1, we show model results that do not use any labeled data. When averaged over all $15$ datasets, E5-PT $\text{base}$ outperforms the classic BM25 algorithm by $1.2$ points. To the best of our knowledge, this is the first reported result that an unsupervised model can beat BM25 on the BEIR benchmark. When scaling up to E5-PT ${\text{large}}$, we see further benefits from $42.9$ to $44.2$.
In terms of pre-training tasks, Contriever adopts random cropping, while LaPraDor combines ICT and dropout-as-positive-instance from SimCSE. The methods can easily obtain large-scale training data, while our approach requires more effort in dataset curation. Such efforts pay off with better results. Recent studies ([44, 32, 45]) also show that improving data quality is a vital step for training large language models.
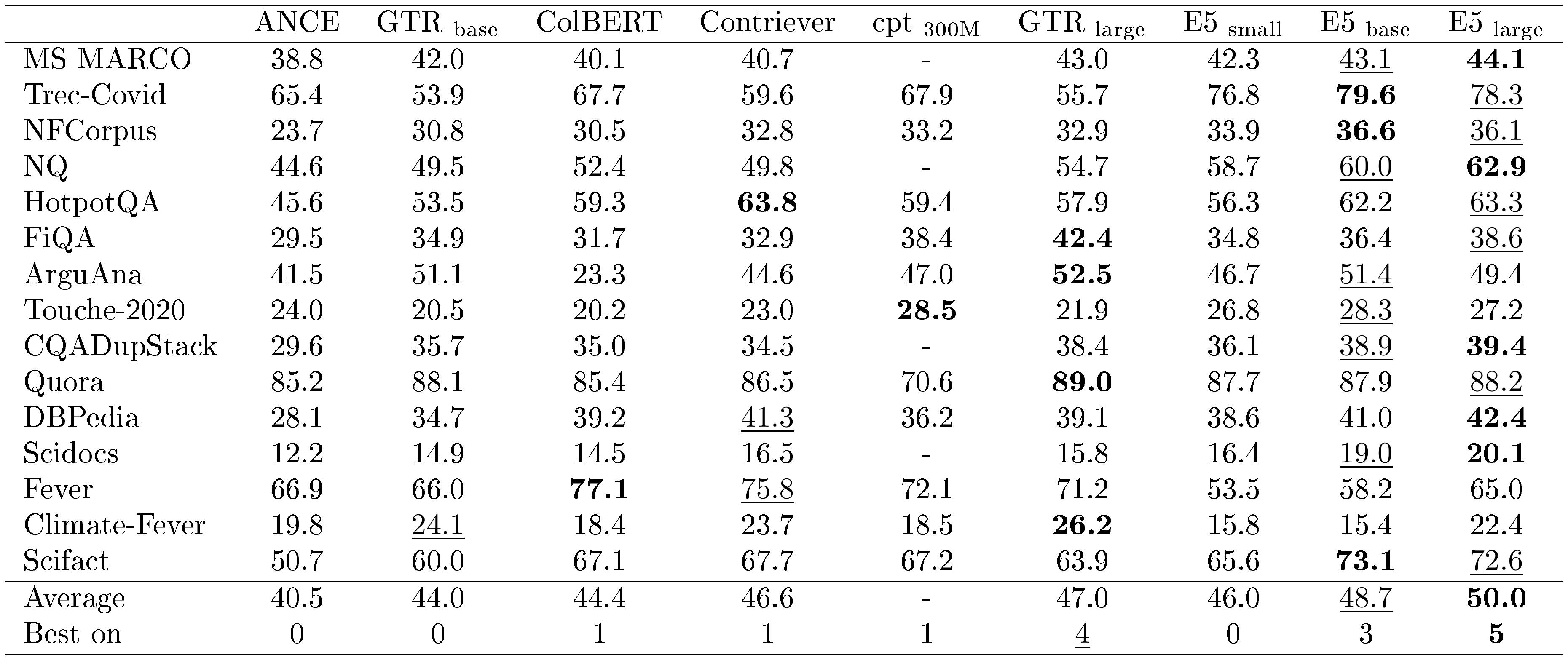
::: {caption="Table 2: Supervised fine-tuning results on the BEIR benchmark. Results for ANCE ([46]), ColBERT ([47]) and Contriever come from [6]. The best result is in bold, and the second best is underlined."}
:::
Results with Supervised Fine-tuning In Table 2, we fine-tune our models on supervised datasets and then transfer them to the BEIR benchmark. Since our fine-tuning datasets include MS-MARCO and NQ, the corresponding numbers are in-domain results. For other datasets, these are zero-shot transfer results. Our E5 $\text{base}$ model achieves an average nDCG@ $10$ of $48.7$, already surpassing existing methods with more parameters such as GTR $\text{large}$ ([3]). Most datasets benefit from supervised fine-tuning, but there are also a few exceptions such as FiQA, Scidocs, and Fever, etc. This is likely due to the lack of enough domain diversity for the fine-tuning datasets.
5.4 Results on MTEB benchmark
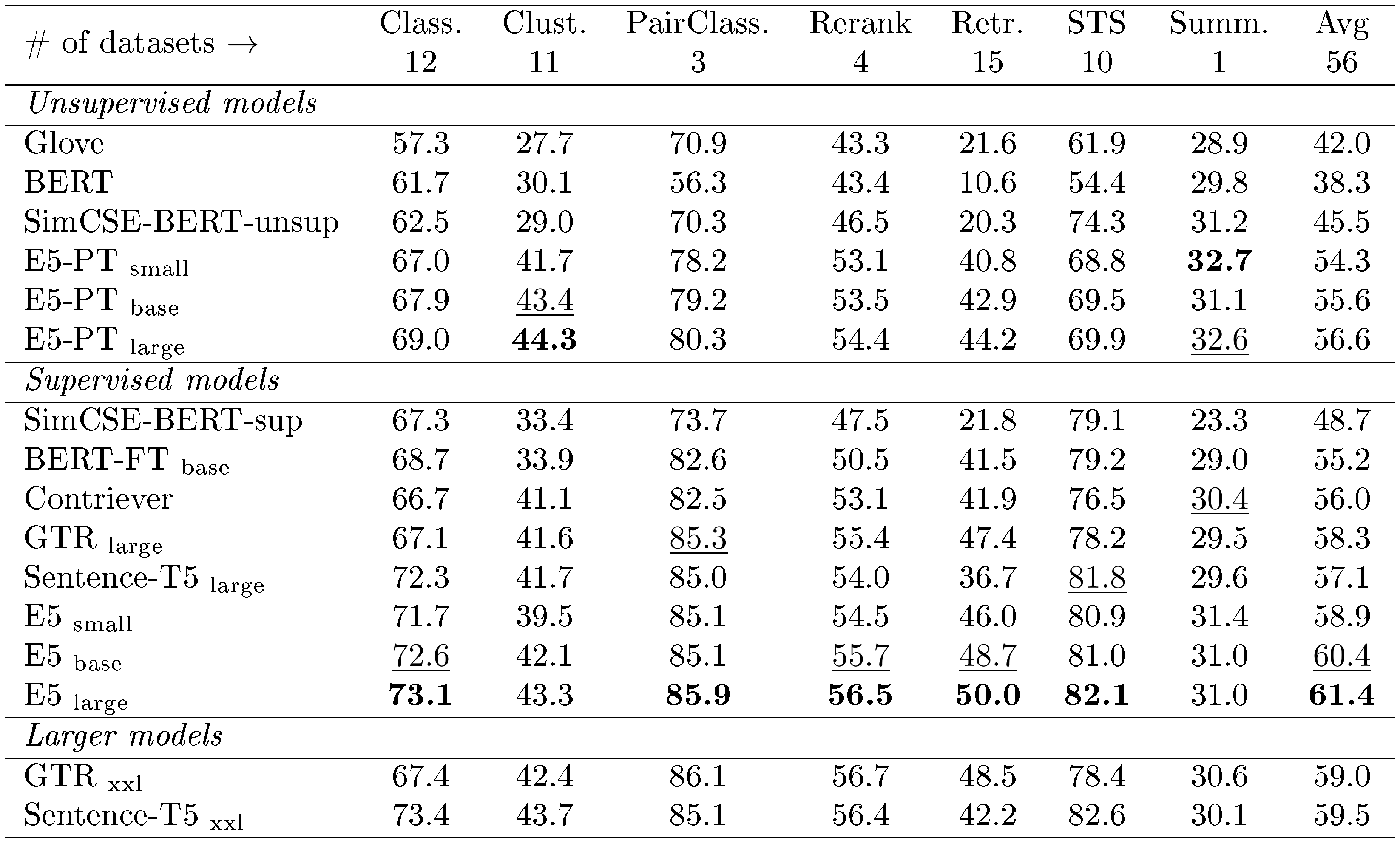
::: {caption="Table 3: Results on the MTEB benchmark ([8]) (56 datasets in English subset). Here we only report averaged numbers on each task category for space reasons, please check out Appendix B for a detailed version. BERT-FT $\text{base}$ uses the same fine-tuning data as E5 but initializes from BERT $\text{base}$."}
:::
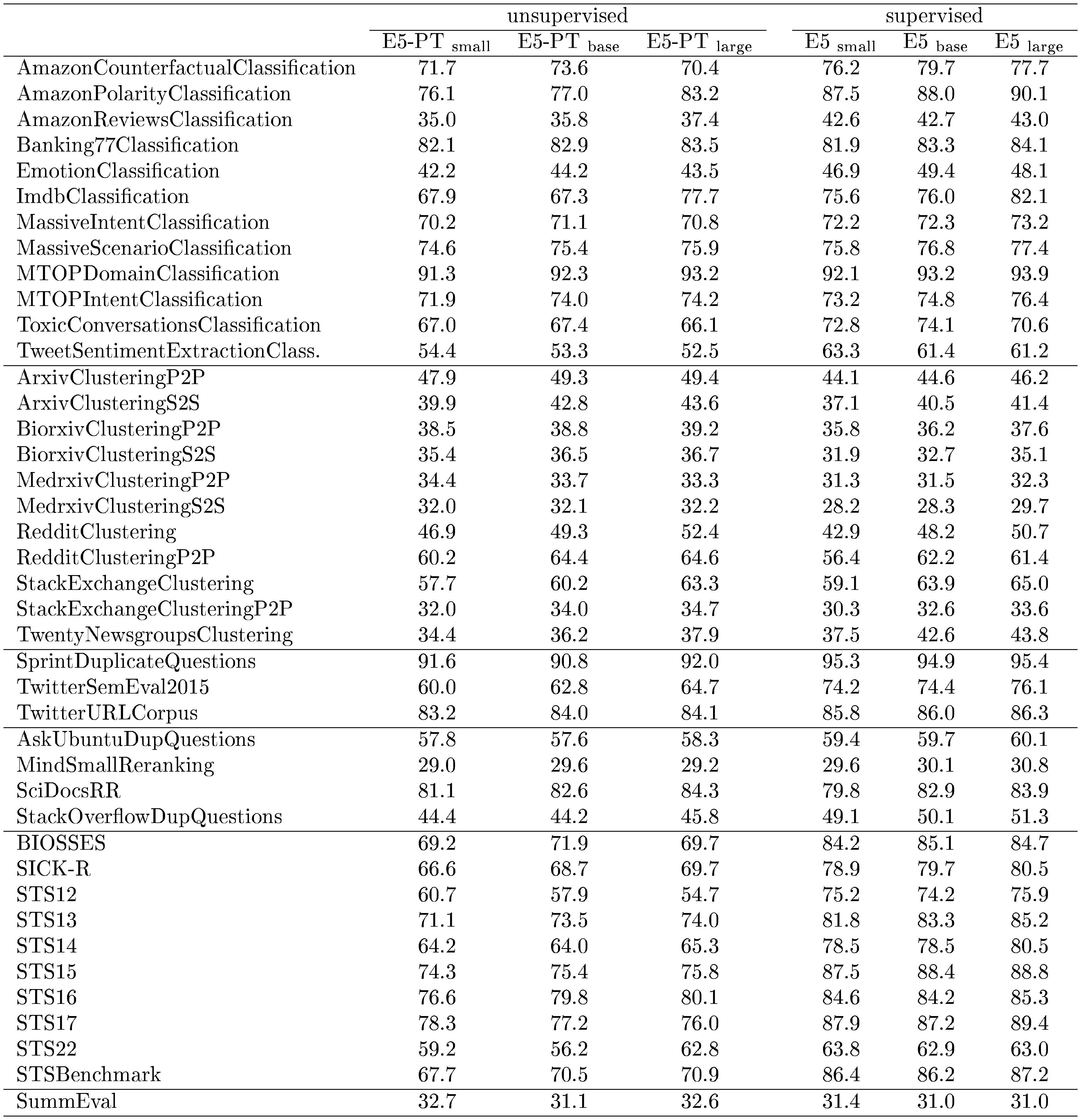
In Table 3, E5 models not only substantially outperform existing ones with similar sizes, but also match the results of much larger models. The top- $2$ models on MTEB leaderboard [^7] GTR $\text{xxl}$ and Sentence-T5 $\text{xxl}$ have $4.8$ B parameters, while our E5 $_\text{large}$ model is more than $10\times$ smaller with $300$ M parameters. We expect that our model will benefit from continual scaling up.
[^7]: https://huggingface.co/spaces/mteb/leaderboard, as of November 22, 2022
Since the difference between BERT-FT $\text{base}$ and E5 $\text{base}$ is that BERT-FT $_\text{base}$ only has fine-tuning stage, their performance gap demonstrates the usefulness of contrastive pre-training on our proposed CCPairs dataset. For most task categories except Clustering, performance improves after supervised fine-tuning. Consistent with prior works ([3, 4]), this once again demonstrates the importance of incorporating human knowledge for learning better text embeddings. It remains an open question whether state-of-the-art embeddings can be obtained in a purely self-supervised manner.
::: {caption="Table 4: Zero-shot text classification results. "Majority" always predicts the majority class label. Zero-shot BERT $_\text{base}$ uses the average pooling of the last layer as text embeddings."}

:::
Table 4 shows the zero-shot text classification results on the dev set of the SST-2 dataset ([48]). By formulating text classification as embedding matching between input and label texts, our model can be much better than the "majority" baseline in a zero-shot setting. We use the prompt template from Section 4.3.
5.5 Analysis
In this section, we conduct a series of analyses to examine various design choices. All the numbers in this section are from base-size models. For the BEIR benchmark, we choose $6$ datasets with more stable results across different runs. Some negative results are also listed in Appendix C.
: Table 5: Impacts of different batch sizes for contrastive pre-training.
| batch size | NFCorpus | NQ | FiQA | Quora | DBPedia | Scifact | Avg |
|---|---|---|---|---|---|---|---|
| 32k | 35.8 | 39.0 | 40.0 | 85.7 | 35.4 | 73.7 | 51.6 |
| 8k | 33.3 | 38.5 | 37.6 | 85.7 | 34.0 | 71.8 | 50.2 |
| 1k | 28.2 | 33.1 | 30.4 | 84.0 | 30.1 | 69.1 | 45.8 |
Impacts of Batch Size Since we use in-batch negatives for contrastive pre-training, larger batch size will provide more negatives and therefore improve the quality of the learned text embeddings. In Table 5, increasing batch size from $1$ K to $32$ K leads to consistent gains across all $6$ datasets. It is also possible to train with smaller batch sizes by adding hard negatives ([39]). However, the engineering efforts of mining hard negatives for large datasets (> $100$ M) are non-trivial.
: Table 6: Fine-tuning with different combinations of labeled data.
| Fine-tuned on | Retrieval | STS | Classification | Summ. | MTEB Avg |
|---|---|---|---|---|---|
| No fine-tuning | 42.9 | 69.5 | 67.9 | 31.1 | 55.6 |
| MS-MARCO + NQ | 50.3 | 78.3 | 68.3 | 30.6 | 59.0 |
| NLI | 38.3 | 81.1 | 72.6 | 31.6 | 57.3 |
| All above | 48.7 | 81.0 | 73.1 | 31.0 | 60.4 |
Fine-tuning Datasets GTR models are fine-tuned with "MS-MARCO + NQ", while Sentence-T5 models use NLI instead. In Table 6, we can see that the "MS-MARCO + NQ" setting performs best on retrieval tasks, and the NLI data is beneficial for STS and linear probing classification. Similar observations are also made by [8]. Combining all of them leads to the best overall scores on the MTEB benchmark. This also illustrates the importance of dataset diversity for learning text embeddings.
::: {caption="Table 7: Data filtering. For the top $2$ rows, we train with $1$ M random text pairs."}

:::
Data Filtering One crucial step in our dataset curation pipeline is filtering out low-quality text pairs. In Table 7, when training with $1$ M pairs, using filtered data has a nearly $6$ points advantage. When all the text pairs are used, the "w/o filter" setting has about $4\times$ more data but is still behind by $1.6$ points. Though recent studies ([49, 26]) show that deep learning models are quite robust to dataset noises, data filtering still has benefits in improving training efficiency and model quality.
: Table 8: Comparison of different negative sampling strategies.
| # negatives | NFCorpus | NQ | FiQA | Quora | DBPedia | Scifact | Avg | |
|---|---|---|---|---|---|---|---|---|
| In batch | 32k | 35.8 | 39.0 | 40.0 | 85.7 | 35.4 | 73.7 | 51.6 |
| + pre-batch | 64k | 29.4 | 27.2 | 29.4 | 84.6 | 25.0 | 64.3 | 43.3 |
| MoCo | 130k | 29.7 | 36.1 | 32.0 | 81.6 | 29.9 | 63.6 | 45.5 |
Negative Sampling We explore two alternative methods to enlarge the number of negatives: Pre-batch negatives ([50]) reuse embeddings from previous batches as additional negatives, while MoCo ([36]) introduces a momentum encoder and uses a FIFO queue to store negatives. For both approaches, the negative size can be easily scaled up without incurring much GPU memory overhead. The downside is that most negatives are produced by an older version of model parameters. In Table 8, in-batch negatives still perform favorably. Empirically, we find that MoCo is more sensitive to certain hyperparameters such as temperature, better results are possible with more tuning.
BM25 vs Dense Retrieval With the rapid development of dense retrieval models, can we replace the long-standing BM25 algorithm from now on? The answer is likely "not yet". BM25 still holds obvious advantages in terms of simplicity, efficiency, and interpretability. For long-tail domains such as Trec-Covid ([51]) and retrieval tasks that involve long documents (Touche-2020) ([52]) or rely heavily on exact lexical match (Fever) ([53]), further research efforts are still necessary to improve current dense retrievers.
6. Conclusion
Section Summary: Researchers developed a versatile text embedding model called E5 by training it on weak supervision from a vast collection of text pairs gathered from diverse online sources, using a straightforward contrastive method with negatives from within batches. This model delivers strong results right out of the box for tasks like searching information, comparing text meanings, and matching content that rely on single-vector representations. When tailored further for specific uses, E5 surpasses much larger existing models, achieving better performance on a comprehensive benchmark covering 56 tasks.
In this work, we train a general-purpose text embedding model E5 from weak supervision signals. We adopt a simple contrastive training framework with in-batch negatives and learn from a large-scale text pair dataset we harvest from heterogeneous data sources across the web. E5 offers strong off-the-shelf performance for a wide range of tasks requiring single-vector text representations such as retrieval, semantic textual similarity, and text matching. When further customized for downstream tasks, E5 achieves superior fine-tuned performance compared to existing embedding models with $40\times$ more parameters on the large, 56-task MTEB benchmark datasets.
Appendix
Section Summary: The appendix provides details on the datasets used for training, including processed web data from Common Crawl and MS-MARCO, Wikipedia articles, Reddit posts from 2018 to 2022, and scientific texts from S2ORC, with careful filtering to remove duplicates and avoid overlap with test data, plus a list of benchmarks like BEIR for evaluation. It also covers practical implementation choices, such as model hyperparameters, text length limits, special prefixes for queries and passages, and in-domain performance results on tasks like passage ranking. Finally, it discusses unsuccessful experiments, like adding search-based negatives or using alternative model initializations, and includes a full list of references.
A. Dataset Details
For Common Crawl, we download the 2022-33 snapshot and cc_net ^8 is used for preprocessing including language identification, de-duplication, language model filtering, etc. Web pages from the MS-MARCO document ranking corpus are also included. For the data filtering step, we examine each pair of passages within a web page instead of just using the title as a query. For Wikipedia, we use the version released by [54]. To avoid possible data contamination, we remove text pairs that occur in the evaluation datasets based on exact string match.
Reddit data is collected from the year 2018 to August 2022. For the S2ORC data, we use a sample weight of $0.3$ during training to avoid over-fitting the scientific domains.
::: {caption="Table 9: Details for each data source after filtering. The "Others" category includes "SimpleWiki", "GooAQ", "WikiHow", "Yahoo Answers" from https://huggingface.co/datasets/sentence-transformers/embedding-training-data."}
:::
For the BEIR benchmark, we use the 15 datasets that provide public downloads: MS MARCO ([18]), Trec-Covid ([51]), NFCorpus ([55]), NQ ([38]), HotpotQA ([56]), FiQA ([57]), ArguAna ([58]), Touche-2020 ([52]), CQADupStack ([59]), Quora, DBPedia ([60]), Scidocs ([61]), Fever ([53]), Climate-Fever ([62]), and Scifact ([63]).
B. Implementation Details
We list the hyperparameters in Table 11. Since some evaluation datasets have long texts, we freeze the position embeddings during both pre-training and fine-tuning and set the maximum text length to $512$ for evaluation.
For the Quora duplicate retrieval task in the BEIR benchmark, we add prefix "query:" to all the questions. For other retrieval tasks, we use "query:" and "passage:" prefixes correspondingly.
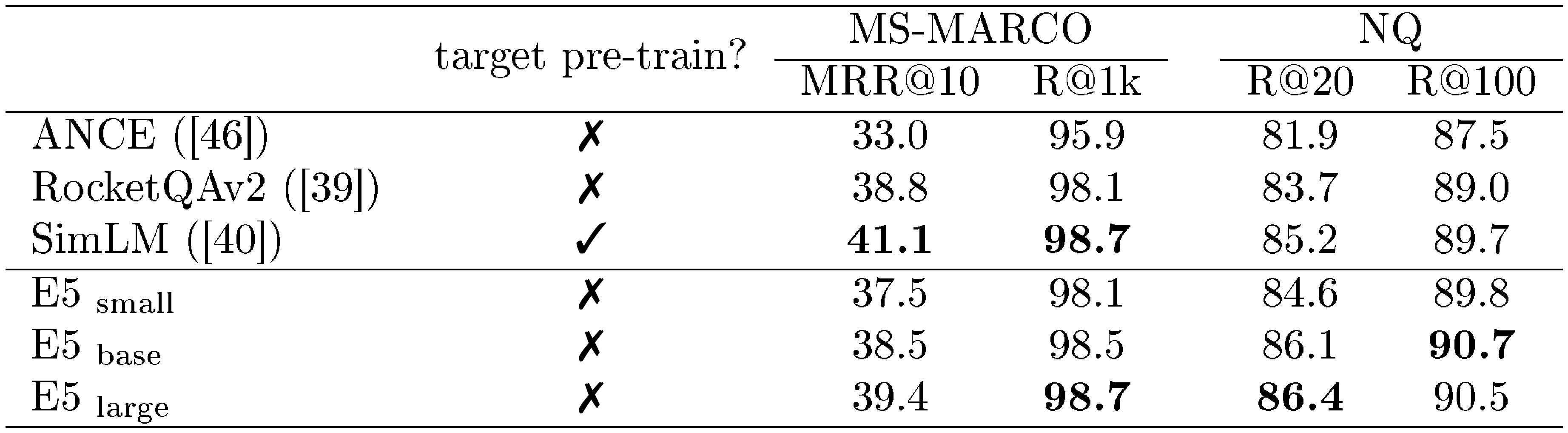
The MS-MARCO results in Table 12 use document titles provided by RocketQA ([39]). This evaluation setup is consistent with most state-of-the-art dense retrievers. However, the MS-MARCO data from the BEIR benchmark does not have titles, so the results are expected to be lower.
::: {caption="Table 10: Model configurations."}

:::
::: {caption="Table 11: Hyperparameters for contrastive pre-training and fine-tuning."}
:::
In-domain Evaluation We report results for in-domain datasets in Table 12. These results can help illustrate the benefits brought by contrastive pre-training when abundant in-domain labeled data are available. For MS-MARCO passage ranking, MRR@10 and Recall@1k are reported. For the NQ dataset, Recall@20 and Recall@100 are the main metrics.
::: {caption="Table 12: In-domain results. "target pre-train" refers to intermediate pre-training on the target corpus before supervised fine-tuning. For NQ, we use the passage retrieval setting from DPR ([37])."}
:::
C. Negative Results
Here are some attempts that we eventually give up on:
Adding BM25 hard negatives Similar to DPR ([37]), we add one BM25 hard negative for each positive pair during training. When using $15$ M data, this strategy improves the overall results by $\sim 0.5$ points on the BEIR benchmark. However, running the BM25 algorithm over a $250$ M+ dataset is too time-consuming even with multi-node and multi-process parallelism.
Using RoBERTa instead of BERT for initialization Though RoBERTa shows consistent gains on many NLP tasks, we empirically find that RoBERTa performs worse than BERT initialization on most of the BEIR benchmark datasets.
Auxiliary MLM objective We add a masked language modeling loss for $25$ % of the training text pairs. The numbers are on par with removing this auxiliary objective, but the training cost goes up.
::: {caption="Table 13: Results for each dataset in the MTEB benchmark ([8]). The numbers for the Retrieval category are not included here since the datasets are the same as the BEIR benchmark."}
:::
References
[1] Devlin et al. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). pp. 4171–4186. doi:10.18653/v1/N19-1423. https://aclanthology.org/N19-1423.
[2] Tom B. Brown et al. (2020). Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual. https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
[3] Jianmo Ni et al. (2021). Large Dual Encoders Are Generalizable Retrievers. ArXiv. abs/2112.07899.
[4] Ni et al. (2022). Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models. In Findings of the Association for Computational Linguistics: ACL 2022. pp. 1864–1874.
[5] Wei-Cheng Chang et al. (2020). Pre-training Tasks for Embedding-based Large-scale Retrieval. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. https://openreview.net/forum?id=rkg-mA4FDr.
[6] Gautier Izacard et al. (2021). Towards Unsupervised Dense Information Retrieval with Contrastive Learning. ArXiv. abs/2112.09118.
[7] Arvind Neelakantan et al. (2022). Text and Code Embeddings by Contrastive Pre-Training. ArXiv. abs/2201.10005.
[8] Niklas Muennighoff et al. (2022). MTEB: Massive Text Embedding Benchmark. ArXiv. abs/2210.07316.
[9] Zhuyun Dai et al. (2022). Promptagator: Few-shot Dense Retrieval From 8 Examples. ArXiv. abs/2209.11755.
[10] Thakur et al. (2021). BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2).
[11] Deerwester et al. (1990). Indexing by latent semantic analysis. Journal of the American society for information science. 41(6). pp. 391–407.
[12] David M. Blei et al. (2001). Latent Dirichlet Allocation. In Advances in Neural Information Processing Systems 14 [Neural Information Processing Systems: Natural and Synthetic, NIPS 2001, December 3-8, 2001, Vancouver, British Columbia, Canada]. pp. 601–608. https://proceedings.neurips.cc/paper/2001/hash/296472c9542ad4d4788d543508116cbc-Abstract.html.
[13] Sanjeev Arora et al. (2017). A Simple but Tough-to-Beat Baseline for Sentence Embeddings. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. https://openreview.net/forum?id=SyK00v5xx.
[14] Tomas Mikolov et al. (2013). Efficient Estimation of Word Representations in Vector Space. In ICLR.
[15] Yinhan Liu et al. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. ArXiv. abs/1907.11692.
[16] Raffel et al. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research. 21. pp. 1–67.
[17] Bowman et al. (2015). A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. pp. 632–642. doi:10.18653/v1/D15-1075. https://aclanthology.org/D15-1075.
[18] Daniel Fernando Campos et al. (2016). MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. ArXiv. abs/1611.09268.
[19] Reimers, Nils and Gurevych, Iryna (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). pp. 3982–3992. doi:10.18653/v1/D19-1410. https://aclanthology.org/D19-1410.
[20] Gao et al. (2021). SimCSE: Simple Contrastive Learning of Sentence Embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. pp. 6894–6910. doi:10.18653/v1/2021.emnlp-main.552. https://aclanthology.org/2021.emnlp-main.552.
[21] Niklas Muennighoff (2022). SGPT: GPT Sentence Embeddings for Semantic Search. ArXiv. abs/2202.08904.
[22] Ting Chen et al. (2020). A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event. pp. 1597–1607. http://proceedings.mlr.press/v119/chen20j.html.
[23] Conneau et al. (2017). Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. pp. 670–680. doi:10.18653/v1/D17-1070. https://aclanthology.org/D17-1070.
[24] Feng et al. (2022). Language-agnostic BERT Sentence Embedding. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 878–891.
[25] Artetxe, Mikel and Schwenk, Holger (2019). Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond. Transactions of the Association for Computational Linguistics. 7. pp. 597–610. doi:10.1162/tacl_a_00288. https://aclanthology.org/Q19-1038.
[26] Alec Radford et al. (2021). Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event. pp. 8748–8763. http://proceedings.mlr.press/v139/radford21a.html.
[27] Barlas Oguz et al. (2022). Domain-matched Pre-training Tasks for Dense Retrieval. In Findings of the Association for Computational Linguistics: NAACL 2022, Seattle, WA, United States, July 10-15, 2022. pp. 1524–1534. doi:10.18653/v1/2022.findings-naacl.114. https://doi.org/10.18653/v1/2022.findings-naacl.114.
[28] Chen et al. (2021). Salient Phrase Aware Dense Retrieval: Can a Dense Retriever Imitate a Sparse One?. arXiv preprint arXiv:2110.06918.
[29] Conneau, Alexis and Kiela, Douwe (2018). SentEval: An Evaluation Toolkit for Universal Sentence Representations. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). https://aclanthology.org/L18-1269.
[30] Schwenk et al. (2021). CCMatrix: Mining Billions of High-Quality Parallel Sentences on the Web. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). pp. 6490–6500. doi:10.18653/v1/2021.acl-long.507. https://aclanthology.org/2021.acl-long.507.
[31] Lo et al. (2020). S2ORC: The Semantic Scholar Open Research Corpus. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 4969–4983. doi:10.18653/v1/2020.acl-main.447. https://aclanthology.org/2020.acl-main.447.
[32] Wenzek et al. (2020). CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data. In Proceedings of the 12th Language Resources and Evaluation Conference. pp. 4003–4012. https://aclanthology.org/2020.lrec-1.494.
[33] Vitaly Feldman and Chiyuan Zhang (2020). What Neural Networks Memorize and Why: Discovering the Long Tail via Influence Estimation. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual. https://proceedings.neurips.cc/paper/2020/hash/1e14bfe2714193e7af5abc64ecbd6b46-Abstract.html.
[34] Duc Tam Nguyen et al. (2020). SELF: Learning to Filter Noisy Labels with Self-Ensembling. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. https://openreview.net/forum?id=HkgsPhNYPS.
[35] Bo Han et al. (2018). Co-teaching: Robust training of deep neural networks with extremely noisy labels. In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada. pp. 8536–8546. https://proceedings.neurips.cc/paper/2018/hash/a19744e268754fb0148b017647355b7b-Abstract.html.
[36] Kaiming He et al. (2020). Momentum Contrast for Unsupervised Visual Representation Learning. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. pp. 9726–9735. doi:10.1109/CVPR42600.2020.00975. https://doi.org/10.1109/CVPR42600.2020.00975.
[37] Karpukhin et al. (2020). Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 6769–6781. doi:10.18653/v1/2020.emnlp-main.550. https://aclanthology.org/2020.emnlp-main.550.
[38] Kwiatkowski et al. (2019). Natural Questions: A Benchmark for Question Answering Research. Transactions of the Association for Computational Linguistics. 7. pp. 452–466. doi:10.1162/tacl_a_00276. https://aclanthology.org/Q19-1026.
[39] Ren et al. (2021). RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. pp. 2825–2835. doi:10.18653/v1/2021.emnlp-main.224. https://aclanthology.org/2021.emnlp-main.224.
[40] Liang Wang et al. (2022). SimLM: Pre-training with Representation Bottleneck for Dense Passage Retrieval. ArXiv. abs/2207.02578.
[41] Neil Houlsby et al. (2019). Parameter-Efficient Transfer Learning for NLP. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA. pp. 2790–2799. http://proceedings.mlr.press/v97/houlsby19a.html.
[42] Wang et al. (2021). MiniLMv2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. pp. 2140–2151.
[43] Xu et al. (2022). LaPraDoR: Unsupervised Pretrained Dense Retriever for Zero-Shot Text Retrieval. In Findings of the Association for Computational Linguistics: ACL 2022. pp. 3557–3569.
[44] Katherine Lee et al. (2022). Deduplicating Training Data Makes Language Models Better. In ACL.
[45] Leo Gao et al. (2021). The Pile: An 800GB Dataset of Diverse Text for Language Modeling. ArXiv. abs/2101.00027.
[46] Lee Xiong et al. (2021). Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. https://openreview.net/forum?id=zeFrfgyZln.
[47] Omar Khattab and Matei Zaharia (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020. pp. 39–48. doi:10.1145/3397271.3401075. https://doi.org/10.1145/3397271.3401075.
[48] Richard Socher et al. (2013). Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Conference on Empirical Methods in Natural Language Processing.
[49] Chao Jia et al. (2021). Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event. pp. 4904–4916. http://proceedings.mlr.press/v139/jia21b.html.
[50] Lee et al. (2021). Learning Dense Representations of Phrases at Scale. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). pp. 6634–6647. doi:10.18653/v1/2021.acl-long.518. https://aclanthology.org/2021.acl-long.518.
[51] Voorhees et al. (2021). TREC-COVID: constructing a pandemic information retrieval test collection. In ACM SIGIR Forum. pp. 1–12.
[52] Bondarenko et al. (2022). Overview of touché 2022: argument retrieval. In International Conference of the Cross-Language Evaluation Forum for European Languages. pp. 311–336.
[53] Thorne et al. (2018). FEVER: a Large-scale Dataset for Fact Extraction and VERification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). pp. 809–819. doi:10.18653/v1/N18-1074. https://aclanthology.org/N18-1074.
[54] Fabio Petroni et al. (2020). KILT: a Benchmark for Knowledge Intensive Language Tasks. In North American Chapter of the Association for Computational Linguistics.
[55] Boteva et al. (2016). A full-text learning to rank dataset for medical information retrieval. In European Conference on Information Retrieval. pp. 716–722.
[56] Yang et al. (2018). HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 2369–2380.
[57] Maia et al. (2018). Www'18 open challenge: financial opinion mining and question answering. In Companion proceedings of the the web conference 2018. pp. 1941–1942.
[58] Wachsmuth et al. (2018). Retrieval of the best counterargument without prior topic knowledge. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 241–251.
[59] Hoogeveen et al. (2015). CQADupStack: A benchmark data set for community question-answering research. In Proceedings of the 20th Australasian document computing symposium. pp. 1–8.
[60] Hasibi et al. (2017). DBpedia-entity v2: a test collection for entity search. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 1265–1268.
[61] Cohan et al. (2020). SPECTER: Document-level Representation Learning using Citation-informed Transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 2270–2282.
[62] Diggelmann et al. (2020). Climate-fever: A dataset for verification of real-world climate claims. arXiv preprint arXiv:2012.00614.
[63] Wadden et al. (2020). Fact or Fiction: Verifying Scientific Claims. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 7534–7550.