Plenoxels: Radiance Fields without Neural Networks
Alex Yu$^*$ Sara Fridovich-Keil$^*$ Matthew Tancik Qinhong Chen
Benjamin Recht Angjoo Kanazawa
UC Berkeley
$^{*}$ Authors contributed equally to this work.
Abstract
We introduce Plenoxels (plenoptic voxels), a system for photorealistic view synthesis. Plenoxels represent a scene as a sparse 3D grid with spherical harmonics. This representation can be optimized from calibrated images via gradient methods and regularization without any neural components. On standard, benchmark tasks, Plenoxels are optimized two orders of magnitude faster than Neural Radiance Fields with no loss in visual quality. For video and code, please see https://alexyu.net/plenoxels.
Executive Summary: Creating photorealistic 3D models from a set of 2D images has become crucial for applications like virtual reality, film production, and autonomous systems, where users need to generate new viewpoints of scenes or objects. However, current leading methods, such as Neural Radiance Fields (NeRF), rely on complex neural networks that demand extensive computing resources—often days of training on a single graphics processing unit (GPU) and up to 30 seconds per rendered frame. This high cost hinders widespread adoption, especially for real-time or large-scale uses, prompting the need for simpler, faster alternatives that preserve visual quality.
This document introduces Plenoxels, a new system designed to reconstruct 3D scenes and synthesize novel views from calibrated photos without using neural networks. The goal is to achieve NeRF-level photorealism while slashing training time by two orders of magnitude, making the process practical for everyday computing setups.
The approach centers on representing the scene as a sparse 3D grid of voxels—small volume elements—that store opacity (how much light they block) and spherical harmonics (a mathematical basis for modeling how color changes with viewing angle). Starting from a set of input images with known camera positions, the team optimized this grid directly through gradient-based methods, comparing rendered outputs to the originals and applying a total variation regularizer to smooth results and prevent artifacts. They used a custom CUDA implementation for efficiency on GPUs. Key elements included a coarse-to-fine strategy, upsampling the grid from low to high resolution (e.g., 256^3 to 512^3 voxels) while pruning empty space to manage memory. Experiments covered synthetic bounded scenes, real forward-facing captures (like handheld phone photos), and full 360-degree real-world environments, drawing from established benchmarks such as NeRF's datasets with 20–100 training images per scene.
The core results show Plenoxels matching or surpassing NeRF's quality across metrics like peak signal-to-noise ratio (PSNR, measuring accuracy), structural similarity (SSIM, capturing perceptual fidelity), and learned perceptual image patch similarity (LPIPS, assessing visual realism). On eight synthetic scenes, Plenoxels scored a PSNR of 31.71 versus NeRF's 31.85, with better SSIM (0.958) and LPIPS (0.049), but trained in just 11 minutes per scene—over 100 times faster than NeRF's 1.45 days. For eight real forward-facing scenes, it achieved PSNR 26.29 (near NeRF's 26.71) in 24 minutes, outperforming older methods like Local Light Field Fusion in smoothness. On four 360-degree real scenes, PSNR hit 20.40 (close to NeRF++'s 20.49) in 27 minutes, again over 100 times quicker than 4 days. Rendering novel views ran at 15 frames per second interactively. Ablations confirmed trilinear interpolation (blending voxel values smoothly) boosted effective resolution by about 50% over nearest-neighbor sampling, and total variation regularization was vital, especially with fewer images, improving PSNR by 5–10% in low-data tests.
These findings mean photorealistic 3D reconstruction no longer requires neural networks; instead, it boils down to a straightforward data structure, differentiable rendering, and basic optimization—revealing NeRF's success stems from its rendering pipeline, not its AI complexity. This cuts costs dramatically: training shifts from expensive, multi-day GPU runs to minutes on consumer hardware, reducing risks of project delays and enabling broader access for industries like gaming or robotics. Unlike neural methods, which can overfit or invent details in unseen areas, Plenoxels produce more predictable outputs, defaulting to neutral fills, though this may limit creativity in some artistic contexts. Results align with expectations but exceed prior non-neural baselines by 20–30% in quality metrics, highlighting untapped potential in classical techniques.
Leaders should prioritize adopting Plenoxels for any pipeline involving view synthesis, starting with bounded or forward-facing scenes to prototype applications like augmented reality previews. For 360-degree setups, integrate the multi-sphere background model. If rendering speed beyond 15 frames per second is needed, convert optimized models to octree structures for further gains. Trade-offs include tuning regularization weights per scene (adding 10–20 minutes of testing) versus using fixed defaults for speed. Further work requires piloting on domain-specific data, such as medical imaging or industrial scans, and exploring extensions like anti-aliasing for multiscale views or tone-mapping for varying lighting.
While robust across benchmarks, limitations include potential artifacts in underdetermined areas (e.g., sparse views causing floaters) and reliance on scene-specific hyperparameters, which could affect 10–20% of edge cases without tuning. Confidence is high for standard photorealistic tasks, with results validated on diverse datasets, but caution is advised for very noisy inputs or non-rigid scenes, where additional regularization analysis would help.
1. Introduction
Section Summary: Recent research has used neural networks, like Neural Radiance Fields (NeRF), to build detailed 3D models from 2D photos, enabling realistic views from new angles, but these methods are slow, often taking days to train and seconds per image to render on a single GPU. In this paper, the authors introduce Plenoxel, a simpler grid-based 3D model without neural networks that achieves similar high-quality results while training over 100 times faster, typically in just minutes on the same hardware. This approach uses basic optimization tools to handle both enclosed and open scenes, showing that the key to photorealistic 3D reconstruction lies in smart rendering techniques rather than complex AI networks.
A recent body of research has capitalized on implicit, coordinate-based neural networks as the 3D representation to optimize 3D volumes from calibrated 2D image supervision. In particular, Neural Radiance Fields (NeRF) [1] demonstrated photorealistic novel viewpoint rendering, capturing scene geometry as well as view-dependent effects. This impressive quality, however, requires extensive computation time for both training and rendering, with training lasting more than a day and rendering requiring 30 seconds per frame, on a single GPU. Multiple subsequent papers [2, 3, 4, 5, 6, 7] reduced this computational cost, particularly for rendering, but single GPU training still requires multiple hours, a bottleneck that limits the practical application of photorealistic volumetric reconstruction.
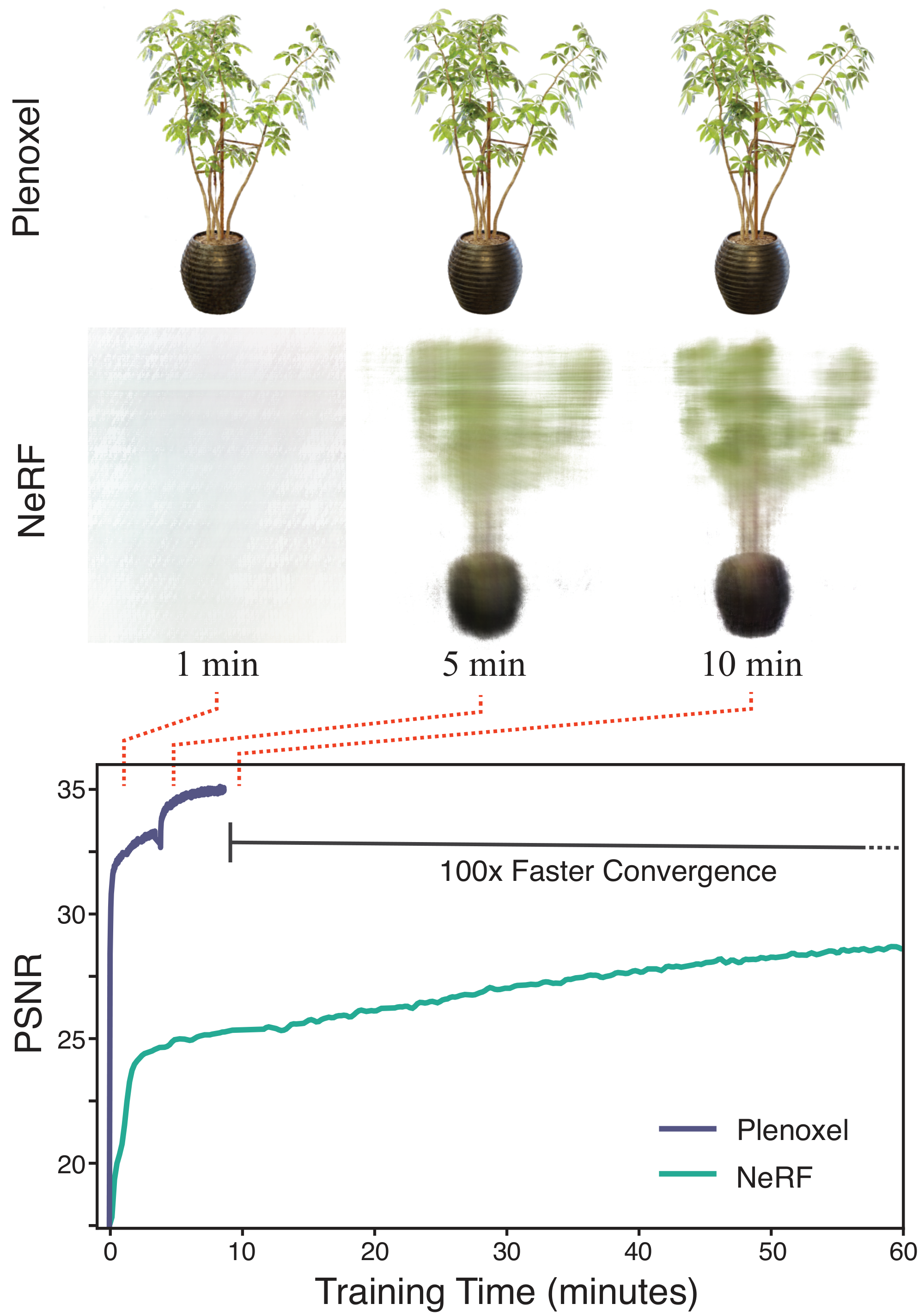
In this paper, we show that we can train a radiance field from scratch, without neural networks, while maintaining NeRF quality and reducing optimization time by two orders of magnitude. We provide a custom CUDA [8] implementation that capitalizes on the model simplicity to achieve substantial speedups. Our typical optimization time on a single Titan RTX GPU is 11 minutes on bounded scenes (compared to roughly 1 day for NeRF, more than a $100\times$ speedup) and 27 minutes on unbounded scenes (compared to roughly 4 days for NeRF++ [9], again more than a $100\times$ speedup). Although our implementation is not optimized for fast rendering, we can render novel viewpoints at interactive rates $15$ fps. If faster rendering is desired, our optimized Plenoxel model can be converted into a PlenOctree [2].
Specifically, we propose an explicit volumetric representation, based on a view-dependent sparse voxel grid without any neural networks. Our model can render photorealistic novel viewpoints and be optimized end-to-end from calibrated 2D photographs, using the differentiable rendering loss on training views as well as a total variation regularizer. We call our model Plenoxel for plenoptic volume elements, as it consists of a sparse voxel grid in which each voxel stores opacity and spherical harmonic coefficients. These coefficients are interpolated to model the full plenoptic function continuously in space. To achieve high resolution on a single GPU, we prune empty voxels and follow a coarse to fine optimization strategy. Although our core model is a bounded voxel grid, we can model unbounded scenes by using normalized device coordinates (for forward-facing scenes) or by surrounding our grid with multisphere images to encode the background (for $360^{\circ}$ scenes).
Our method reveals that photorealistic volumetric reconstruction can be approached using standard tools from inverse problems: a data representation, a forward model, a regularization function, and an optimizer. Our method shows that each of these components can be simple and state of the art results can still be achieved. Our experiments suggest the key element of Neural Radiance Fields is not the neural network but the differentiable volumetric renderer.
2. Related Work
Section Summary: Classical methods for reconstructing 3D volumes from images rely on structures like voxel grids or multi-plane images, which represent scenes efficiently but can struggle with memory at high resolutions; techniques such as sparse arrays and interpolation, combined with volume rendering formulas and spherical harmonics for handling different viewpoints, form the foundation of these approaches. Recent neural methods have advanced this field, with models like NeRF using machine learning to predict colors and opacities from 2D images, though they are computationally slow for training and rendering, leading to extensions that improve efficiency through voxel optimizations or background modeling. To address NeRF's speed issues, various acceleration techniques subdivide spaces, parallelize computations, or convert models into faster structures like sparse voxel grids, which the authors build upon in their Plenoxel approach for quicker, direct optimization without neural networks.
Classical Volume Reconstruction.
We begin with a brief overview of classical methods for volume reconstruction, focusing on those which find application in our work. In particular, the most common classical methods for volume rendering are voxel grids [10, 11, 12, 13, 14, 15, 16] and multi-plane images (MPIs) [17, 18, 19, 20, 21, 22]. Voxel grids are capable of representing arbitrary topologies but can be memory limited at high resolution. One approach for reducing the memory requirement for voxel grids is to encode hierarchical structure, for instance using octrees [23, 24, 25, 26] (see [27] for a survey); we use an even simpler sparse array structure. Using these grid-based representations combined with some form of interpolation produces a continuous representation that can be arbitrarily resized using standard signal processing methods (see [28] for reference). This combination of sparsity and interpolation enables even a simple grid-based model to represent 3D scenes at high resolution without prohibitive memory requirements. We combine this classical sampling and interpolation paradigm with the forward volume rendering formula introduced by Max [29] (based on work from Kajiya and Von Herzen [30] and used in NeRF) to directly optimize a 3D model from indirect 2D observations. We further extend these classical approaches by modeling view dependence, which we accomplish by optimizing spherical harmonic coefficients for each color channel at each voxel. Spherical harmonics are a standard basis for functions over the sphere, and have been used previously to represent view dependence [31, 32, 33, 2].
Neural Volume Reconstruction.
Recently, dramatic improvements in neural volume reconstruction have renewed interest in this direction. Neural implicit representations were first used to model occupancy [34, 35, 36] and signed distance to an object's surface [37, 38], and perform novel view synthesis from 3D point clouds [39, 40, 41, 42]. Several papers extended this idea of neural implicit 3D modeling to model a scene using only calibrated 2D image supervision via a differentiable volume rendering formulation [15, 43, 16, 1].
NeRF [1] in particular uses a differentiable volume rendering formula to train a coordinate-based multilayer perceptron (MLP) to directly predict color and opacity from 3D position and 2D viewing direction. NeRF produces impressive results but requires several days for full training, and about half an minute to render a full image, because every rendered pixel requires evaluating the coordinate-based MLP at hundreds of sample locations along the corresponding ray. Many papers have since extended the capabilities of NeRF, including modeling the background in $360^{\circ}$ views [9] and incorporating anti-aliasing for multiscale rendering [44]. We extend our Plenoxel method to unbounded $360^{\circ}$ scenes using a background model inspired by NeRF++ [9].
Of these methods, Neural Volumes [16] is the most similar to ours in that it uses a voxel grid with interpolation, but optimizes this grid through a convolutional neural network and applies a learned warping function to improve the effective resolution (of a $128^3$ grid). We show that the voxel grid can be optimized directly and high resolution can be achieved by pruning and coarse to fine optimization, without any neural networks or warping functions.
![**Figure 2:** **Overview of our sparse Plenoxel model.** Given a set of images of an object or scene, we reconstruct a (a) sparse voxel ("Plenoxel") grid with density and spherical harmonic coefficients at each voxel. To render a ray, we (b) compute the color and opacity of each sample point via trilinear interpolation of the neighboring voxel coefficients. We integrate the color and opacity of these samples using (c) differentiable volume rendering, following the recent success of NeRF [1]. The voxel coefficients can then be (d) optimized using the standard MSE reconstruction loss relative to the training images, along with a total variation regularizer.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/7cqssx6b/overview.png)
Accelerating NeRF.
In light of the substantial computational requirements of NeRF for both training and rendering, many recent papers have proposed methods to improve efficiency, particularly for rendering. Among these methods are many that achieve speedup by subdividing the 3D volume into regions that can be processed more efficiently [4, 5]. Other speedup approaches have focused on a range of computational and pre- or post-processing methods to remove bottlenecks in the original NeRF formulation. JAXNeRF [45], a JAX [46] reimplementation of NeRF offers a speedup for both training and rendering via parallelization across many GPUs or TPUs. AutoInt [47] restructures the coordinate-based MLP to compute ray integrals exactly, for more than $10\times$ faster rendering with a small loss in quality. Learned Initializations [48] employs meta-learning on many scenes to start from a better MLP initialization, for both
gt;10\times$ faster training and better priors when per-scene data is limited. Other methods [49, 50, 51] achieve speedup by predicting a surface or sampling near the surface, reducing the number of samples necessary for rendering each ray.Another approach is to pretrain a NeRF (or similar model) and then extract it into a different data structure that can support fast inference [6, 7, 3, 2]. In particular, PlenOctrees [2] extracts a NeRF variant into a sparse voxel grid in which each voxel represents view-dependent color using spherical harmonic coefficients. Because the extracted PlenOctree can be further optimized, this method can speed up training by roughly $3\times$, and because it uses an efficient GPU octree implementation without any MLP evaluations, it achieves
gt;3000\times$ rendering speedup. Our method extends PlenOctrees to perform end-to-end optimization of a sparse voxel representation with spherical harmonics, offering much faster training (two orders of magnitude speedup compared to NeRF). Our Plenoxel model is a generalization of PlenOctrees to support sparse plenoptic voxel grids of arbitrary resolution (not necessary powers of two) with the ability to perform trilinear interpolation, which is easier to implement with this sparse voxel structure.3. Method
Section Summary: The method introduces Plenoxel, a sparse 3D grid model where tiny occupied spaces, called voxels, store simple values for how opaque they are and color details using mathematical patterns called spherical harmonics to handle lighting from different angles. To create images, the model blends these values smoothly from nearby voxels along lines of sight, much like a neural radiance field approach, and fine-tunes everything directly by comparing rendered views to actual photos. It improves accuracy with smooth blending instead of abrupt jumps between voxels and builds high-detail results step-by-step, starting coarse and gradually refining by splitting and trimming empty areas.
Our model is a sparse voxel grid in which each occupied voxel corner stores a scalar opacity $\sigma$ and a vector of spherical harmonic (SH) coefficients for each color channel. From here on we refer to this representation as Plenoxel. The opacity and color at an arbitrary position and viewing direction are determined by trilinearly interpolating the values stored at the neighboring voxels and evaluating the spherical harmonics at the appropriate viewing direction. Given a set of calibrated images, we optimize our model directly using the rendering loss on training rays. Our model is illustrated in Figure 2 and described in detail below.
3.1 Volume Rendering
We use the same differentiable model for volume rendering as in NeRF, where the color of a ray is approximated by integrating over samples taken along the ray:
$ \begin{align} \hat C(\textbf{r}) = \sum_{i=1}^N T_i \big(1 - \exp(-\sigma_i \delta_i)\big)\textbf{c}i \ \text{where } \hspace{2em} T_i = \exp \left(-\sum{j=1}^{i-1} \sigma_j \delta_j \right) \end{align}\tag{1} $
$T_i$ represents how much light is transmitted through ray $\textbf{r}$ to sample $i$ (versus contributed by preceding samples), $\left(1 - \exp(-\sigma_i \delta_i)\right)$ denotes how much light is contributed by sample $i$, $\sigma_i$ denotes the opacity of sample $i$, and $\textbf{c}_i$ denotes the color of sample $i$, with distance $\delta_i$ to the next sample. Although this formula is not exact (it assumes single-scattering [30] and constant values between samples [29]), it is differentiable and enables updating the 3D model based on the error of each training ray.
3.2 Voxel Grid with Spherical Harmonics
Similar to PlenOctrees [2], we use a sparse voxel grid for our geometry model. However, for simplicity and ease of implementing trilinear interpolation, we do not use an octree for our data structure. Instead, we store a dense 3D index array with pointers into a separate data array containing values for occupied voxels only. Like PlenOctrees, each occupied voxel stores a scalar opacity $\sigma$ and a vector of spherical harmonic coefficients for each color channel. Spherical harmonics form an orthogonal basis for functions defined over the sphere, with low degree harmonics encoding smooth (more Lambertian) changes in color and higher degree harmonics encoding higher-frequency (more specular) effects. The color of a sample $\textbf{c}_i$ is simply the sum of these harmonic basis functions for each color channel, weighted by the corresponding optimized coefficients and evaluated at the appropriate viewing direction. We use spherical harmonics of degree 2, which requires 9 coefficients per color channel for a total of 27 harmonic coefficients per voxel. We use degree 2 harmonics because PlenOctrees found that higher order harmonics confer only minimal benefit.
Our Plenoxel grid uses trilinear interpolation to define a continuous plenoptic function throughout the volume. This is in contrast to PlenOctrees, which assumes that the opacity and spherical harmonic coefficients remain constant inside each voxel. This difference turns out to be an important factor in successfully optimizing the volume, as we discuss below. All coefficients (for opacity and spherical harmonics) are optimized directly, without any special initialization or pretraining with a neural network.
3.3 Interpolation
The opacity and color at each sample point along each ray are computed by trilinear interpolation of opacity and harmonic coefficients stored at the nearest 8 voxels. We find that trilinear interpolation significantly outperforms a simpler nearest neighbor interpolation; an ablation is presented in Table 1. The benefits of interpolation are twofold: interpolation increases the effective resolution by representing sub-voxel variations in color and opacity, and interpolation produces a continuous function approximation that is critical for successful optimization. Both of these effects are evident in Table 1: doubling the resolution of a nearest-neighbor-interpolating Plenoxel closes much of the gap between nearest neighbor and trilinear interpolation at a fixed resolution, yet some gap remains due to the difficulty of optimizing a discontinuous model. Indeed, we find that trilinear interpolation is more stable with respect to variations in learning rate compared to nearest neighbor interpolation (we tuned the learning rates separately for each interpolation method in Table 1, to provide close to the best number possible for each setup).
\begin{tabular}{@{}lcccc@{}}
\toprule
& & PSNR $\uparrow$ & SSIM $\uparrow$ & LPIPS $\downarrow$ \\ \cmidrule(r){1-1} \cmidrule(l){3-5}
Trilinear, $256^3$ & & 30.57 & 0.950 & 0.065 \\
Trilinear, $128^3$ & & 28.46 & 0.926 & 0.100 \\
Nearest Neighbor, $256^3$ & & 27.17 & 0.914 & 0.119 \\
Nearest Neighbor, $128^3$ & & 23.73 & 0.866 & 0.176 \\
\bottomrule
\end{tabular}
3.4 Coarse to Fine
We achieve high resolution via a coarse-to-fine strategy that begins with a dense grid at lower resolution, optimizes, prunes unnecessary voxels, refines the remaining voxels by subdividing each in half in each dimension, and continues optimizing. For example, in the synthetic case, we begin with $256^3$ resolution and upsample to $512^3$. We use trilinear interpolation to initialize the grid values after each voxel subdivision step. In fact, we can resize between arbitrary resolutions using trilinear interpolation. Voxel pruning is performed using the method from PlenOctrees [2], which applies a threshold to the maximum weight $T_i (1- \exp(-\sigma_i \delta_i))$ of each voxel over all training rays (or, alternatively, to the density value in each voxel). Due to trilinear interpolation, naively pruning can adversely impact the the color and density near surfaces since values at these points interpolate with the voxels in the immediate exterior. To solve this issue, we perform a dilation operation so that a voxel is only pruned if both itself and its neighbors are deemed unoccupied.
3.5 Optimization
We optimize voxel opacities and spherical harmonic coefficients with respect to the mean squared error (MSE) over rendered pixel colors, with total variation (TV) regularization [52]. Specifically, our base loss function is:
$ \mathcal{L} = \mathcal{L}{recon} + \lambda{TV}, \mathcal{L}_{TV}\tag{2} $
Where the MSE reconstruction loss $\mathcal{L}{recon}$ and the total variation regularizer $\mathcal{L}{TV}$ are:
$ \begin{aligned} \mathcal{L}{recon} &= \frac1{|\mathcal{R}|}\sum{\textbf{r} \in \mathcal{R}} |C(\textbf{r}) - \hat C(\textbf{r})|2^2 \ \mathcal{L}{TV} &= \frac{1}{|\mathcal{V}|} \sum_{\substack{\mathbf{v} \in \mathcal{V}\ d \in [D]}} \sqrt{\Delta_x^2(\mathbf{v}, d) + \Delta_y^2(\mathbf{v}, d) + \Delta_z^2(\mathbf{v}, d)} \end{aligned} $
with $\Delta_x^2(\mathbf{v}, d)$ shorthand for the squared difference between the $d$ th value in voxel $\mathbf{v}:=(i, j, k)$ and the $d$ th value in voxel $(i+1, j, k)$ normalized by the resolution, and analogously for $\Delta_y^2(\mathbf{v}, d)$ and $\Delta_z^2(\mathbf{v}, d)$. Note in practice we use different weights for SH coefficients and $\sigma$ values. These weights are fixed for each scene type (bounded, forward-facing, and $360^{\circ}$).
For faster iteration, we use a stochastic sample of the rays $\mathcal{R}$ to evaluate the MSE term and a stochastic sample of the voxels $\mathcal{V}$ to evaluate the TV term in each optimization step. We use the same learning rate schedule as JAXNeRF and Mip-NeRF [45, 44], but tune the initial learning rate separately for opacity and harmonic coefficients. The learning rate is fixed for all scenes in all datasets in the main experiments.
Directly optimizing voxel coefficients is a challenging problem for several reasons: there are many values to optimize (the problem is high-dimensional), the optimization objective is nonconvex due to the rendering formula, and the objective is poorly conditioned. Poor conditioning is typically best resolved by using a second order optimization algorithm (e.g as recommended in [53]), but this is practically challenging to implement for a high-dimensional optimization problem because the Hessian is too large to easily compute and invert in each step. Instead, we use RMSProp [54] to ease the ill-conditioning problem without the full computational complexity of a second-order method.
3.6 Unbounded Scenes
We show that Plenoxels can be optimized for a wide range of settings beyond the synthetic scenes from the original NeRF paper.
With minor modifications, Plenoxels extend to real, unbounded scenes, both forward-facing and $360^{\circ}$. For forward-facing scenes, we use the same sparse voxel grid structure with normalized device coordinates, as defined in the original NeRF paper [1].
Background model.
For $360^{\circ}$ scenes, we augment our sparse voxel grid foreground representation with a multi-sphere image (MSI) background model, which also uses learned voxel colors and opacities with trilinear interpolation within and between spheres. Note that this is effectively the same as our foreground model, except the voxels are warped into spheres using the simple equirectangular projection (voxels index over sphere angles $\theta$ and $\phi$). We place 64 spheres linearly in inverse radius from $1$ to $\infty$ (we pre-scale the inner scene to be approximately contained in the unit sphere). To conserve memory, we store only rgb channels for the colors (only zero-order SH) and store all layers sparsely by using opacity thresholding as in our main model. This is similar to the background model in NeRF++ [9].
3.7 Regularization
We illustrate the importance of TV regularization in Figure 3. In addition to TV regularization, which encourages smoothness and is used on all scenes, for certain types of scenes we also use additional regularizers.

On the real, forward-facing and $360^\circ$ scenes, we use a sparsity prior based on a Cauchy loss following SNeRG [7]:
$ \mathcal{L}s = \lambda_s \sum{i, k}\log \left(1 + 2\sigma(\mathbf{r}_i(t_k))^2 \right) $
where $\sigma(\mathbf{r}_i(t_k))$ denotes the opacity of sample $k$ along training ray $i$. In each minibatch of optimization on forward-facing scenes, we evaluate this loss term at each sample on each active ray. This is also similar to the sparsity loss used in PlenOctrees [2] and encourages voxels to be empty, which helps to save memory and reduce quality loss when upsampling.
On the real, $360^{\circ}$ scenes, we also use a beta distribution regularizer on the accumulated foreground transmittance of each ray in each minibatch. This loss term, following Neural Volumes [16], promotes a clear foreground-background decomposition by encouraging the foreground to be either fully opaque or empty. This beta loss is:
$ \mathcal{L}{\beta} = \lambda{\beta}\sum_{\mathbf{r}}\left(\log(T_{FG}(\mathbf{r})) + \log(1 - T_{FG}(\mathbf{r})) \right) $
where $\mathbf{r}$ are the training rays and $T_{FG}(\mathbf{r})$ is the accumulated foreground transmittance (between 0 and 1) of ray $\mathbf{r}$.
3.8 Implementation
Since sparse voxel volume rendering is not well-supported in modern autodiff libraries, we created a custom PyTorch CUDA [8] extension library to achieve fast differentiable volume rendering; we hope practitioners will find this implementation useful in their applications. We also provide a slower, higher-level JAX [46] implementation. Both implementations will be released to the public.
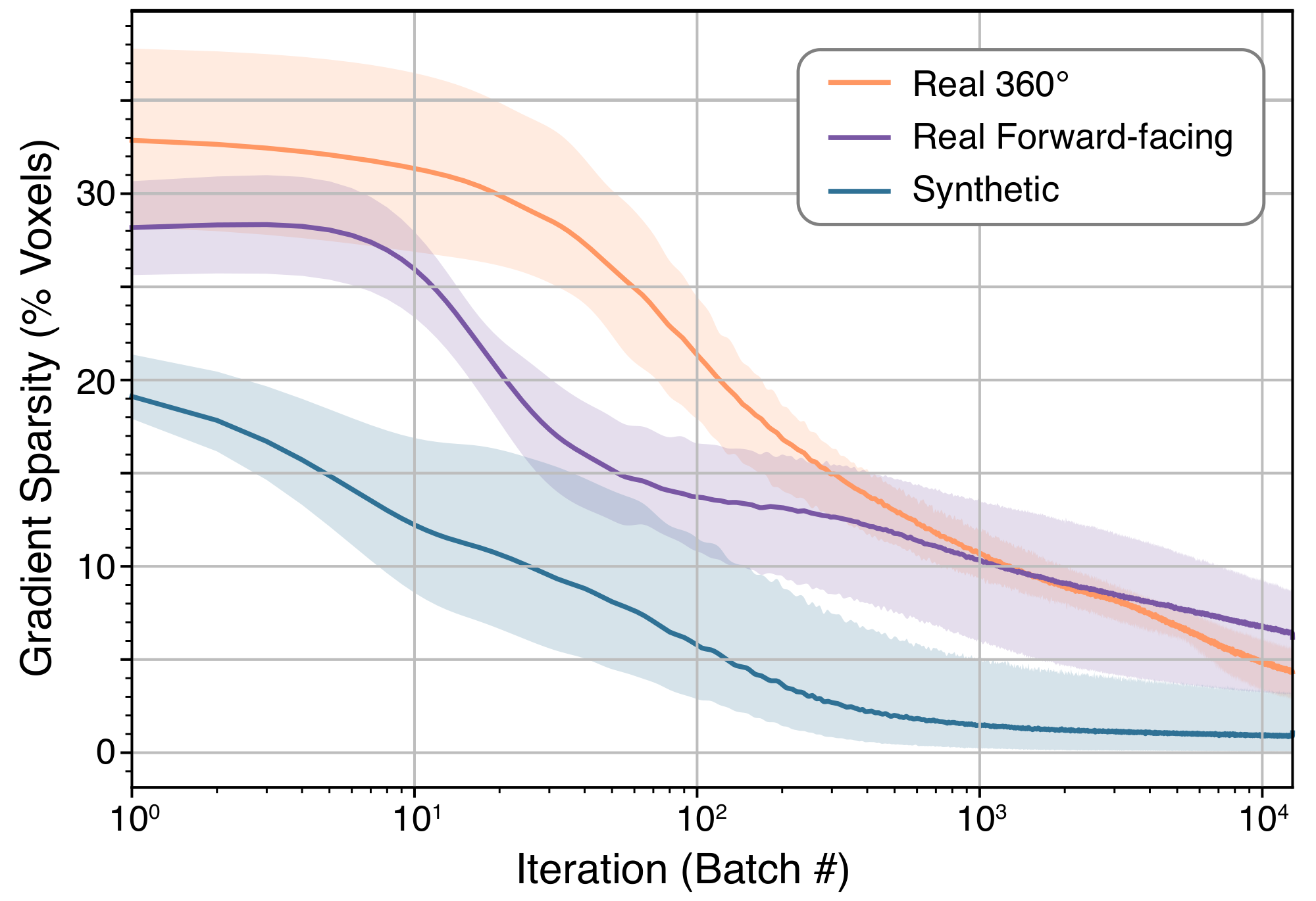
The speed of our implementation is possible in large part because the gradient of our Plenoxel model becomes very sparse very quickly, as shown in Figure 4. Within the first 1-2 minutes of optimization, fewer than 10% of the voxels have nonzero gradients.
4. Results
Section Summary: The study presents results for reconstructing 3D scenes from photos, covering synthetic bounded objects, real forward-facing environments like room corners, and full 360-degree real-world scenes such as vehicles or parks. Compared to earlier methods, the new approach delivers similar or better image quality—measured by clarity and detail scores—while training in just minutes on a single computer chip instead of days, and it allows for real-time viewing of new angles. Early tests after minimal training already produce sharp results, with added tweaks like background models enabling handling of vast outdoor spaces.

We present results on synthetic, bounded scenes; real, unbounded, forward-facing scenes; and real, unbounded, $360^{\circ}$ scenes. We include time trial comparisons with prior work, showing dramatic speedup in training compared to all prior methods (alongside real-time rendering). Quantitative comparisons are presented in Table 2, and visual comparisons are shown in Figure 6, Figure 7, and Figure 8. Our method achieves quality results after even the first epoch of optimization, less than 1.5 minutes, as shown in Figure 5.
We also present the results from various ablation studies of our method. In the main text we present average results (PSNR, SSIM [55], and VGG LPIPS [56]) over all scenes of each type; full results on each scene individually are included in the supplement. We include full experimental details (hyperparameters, etc.) in the supplement.
4.1 Synthetic Scenes
Our synthetic experiments use the 8 scenes from NeRF: chair, drums, ficus, hotdog, lego, materials, mic, and ship. Each scene includes 100 ground truth training views with 800 $\times$ 800 resolution, from known camera positions distributed randomly in the upper hemisphere facing the object, which is set against a plain white background. Each scene is evaluated on 200 test views, also with resolution 800 $\times$ 800 and known inward-facing camera positions in the upper hemisphere. We provide quantitative comparisons in Table 2 and visual comparisons in Figure 6.
\begin{tabular}{@{}llccccc@{}}
\toprule
& & PSNR $\uparrow$ & SSIM $\uparrow$ & LPIPS $\downarrow$ & & Train Time \\ \cmidrule(r){1-1} \cmidrule(l){3-5} \cmidrule(l){7-7}
Ours & & 31.71 & \textbf{0.958} & \textbf{0.049} & & \textbf{11 mins} \\
NV [16] & & 26.05 & 0.893 & 0.160 & & gt;$ 1 day \\
JAXNeRF [1, 45] & & \textbf{31.85} & 0.954 & 0.072 & & 1.45 days \\ \cmidrule(r){1-1} \cmidrule(l){3-5} \cmidrule(l){7-7}
Ours & & 26.29 & \textbf{0.839} & \textbf{0.210} & & \textbf{24 mins} \\
LLFF [21] & & 24.13 & 0.798 & 0.212 & & ---* \\
JAXNeRF [1, 45] & & \textbf{26.71} & 0.820 & 0.235 & & 1.62 days \\ \cmidrule(r){1-1} \cmidrule(l){3-5} \cmidrule(l){7-7}
Ours & & 20.40 & \textbf{0.696} & \textbf{0.420} & & \textbf{27 mins} \\
NeRF++ [9] & & \textbf{20.49} & 0.648 & 0.478 & & $\sim$ 4 days \\
\bottomrule
\end{tabular}
![**Figure 6:** **Synthetic, bounded scenes.** Example results on the lego and ship synthetic scenes from NeRF [1]. Please see the supplementary material for more images.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/7cqssx6b/complex_fig_808be7a5d3a8.png)
We compare our method to Neural Volumes (NV) [16] (as a prior method that predicts a grid for each scene, using a 3D convolutional network), and JAXNeRF [1, 45]. For Neural Volumes we use values reported in [1]; for JAXNeRF we report results from our own rerunning, fixing the centered pixel bug. Our method achieves comparable quality compared to the best baseline, while training in an average of 11 minutes per scene on a single GPU and supporting interactive rendering.
4.2 Real Forward-Facing Scenes
We extend our method to unbounded, forward-facing scenes by using normalized device coordinates (NDC), as derived in NeRF [1]. Our method is otherwise identical to the version we use on bounded, synthetic scenes, except that we use TV regularization (with a stronger weight) throughout the optimization. This change is likely necessary because of the reduced number of training views for these scenes, as described in Section 4.4.
Our forward-facing experiments use the same 8 scenes as in NeRF, 5 of which are originally from LLFF [21]. Each scene consists of 20 to 60 forward-facing images captured by a handheld cell phone with resolution 1008 $\times$ 756, with $\frac{7}{8}$ of the images used for training and the remaining $\frac{1}{8}$ of the images reserved as a test set.
We compare our method to Local Light Field Fusion (LLFF) [21] (a prior method that uses a 3D convolutional network to predict a grid for each input view) and JAXNeRF. We provide quantitative comparisons in Table 2 and visual comparisons in Figure 7.

4.3 Real $360^{\circ}$ Scenes
We extend our method to real, unbounded, $360^{\circ}$ scenes by surrounding our sparse voxel grid with an multi-sphere image (MSI, based on multi-plane images introduced by [19]) background model, in which each background sphere is also a simple voxel grid with trilinear interpolation (both within each sphere and between adjacent background sphere layers).
Our $360^{\circ}$ experiments use 4 scenes from the Tanks and Temples dataset [57]: M60, playground, train, and truck. For each scene, we use the same train/test split as [58].
We compare our method to NeRF++ [9], which augments NeRF with a background model to represent unbounded scenes. We present quantitative comparisons in Table 2 and visual comparisons in Figure 8.
::::


Figure 8: Real, $360^\circ$ scenes. Example results on the playground and truck $360^\circ$ scenes from Tanks and Temples [57]. ::::
4.4 Ablation Studies
In this section, we perform extensive ablation studies of our method to understand which features are core to its success, with such a simple model. In Table 1, we show that continuous (in our case, trilinear) interpolation is responsible for dramatic improvement in fidelity compared to nearest neighbor interpolation (i.e constant within each voxel) [2].
In Table 3, we consider how our method handles a dramatic reduction in training data, from 100 views to 25 views, on the 8 synthetic scenes. We compare our method to NeRF and find that, despite its lack of complex neural priors, by increasing TV regularization our method can outperform NeRF even in this limited data regime. This ablation also sheds light on why our model performs better with higher TV regularization on the real forward-facing scenes compared to the synthetic scenes: the real scenes have many fewer training images, and the stronger regularizer helps our optimization extend smoothly to sparsely-supervised regions.
We also ablate over the resolution of our Plenoxel grid in Table 4 and the rendering formula in Table 5. The rendering formula from Max [29] yields a substantial improvement compared to that of Neural Volumes [16], perhaps because it is more physically accurate (as discussed further in the supplement). The supplement also includes ablations over the learning rate schedule and optimizer demonstrating Plenoxel optimization to be robust to these hyperparameters.
\begin{tabular}{@{}llccc@{}}
\toprule
& & PSNR $\uparrow$ & SSIM $\uparrow$ & LPIPS $\downarrow$ \\ \cmidrule(r){1-1} \cmidrule(l){3-5}
Ours: 100 images (low TV) & & 31.71 & 0.958 & 0.050 \\
NeRF: 100 images [1] & & 31.01 & 0.947 & 0.081 \\ \cmidrule(r){1-1} \cmidrule(l){3-5}
Ours: 25 images (low TV) & & 26.88 & 0.911 & 0.099 \\
Ours: 25 images (high TV) & & 28.25 & 0.932 & 0.078 \\
NeRF: 25 images [1] & & 27.78 & 0.925 & 0.108 \\
\bottomrule
\end{tabular}
\begin{tabular}{@{}llccc@{}}
\toprule
Resolution & & PSNR $\uparrow$ & SSIM $\uparrow$ & LPIPS $\downarrow$ \\ \cmidrule(r){1-1} \cmidrule(l){3-5}
$512^3$ & & 31.71 & 0.958 & 0.050 \\
$256^3$ & & 30.57 & 0.950 & 0.065 \\
$128^3$ & & 28.46 & 0.926 & 0.100 \\
$64^3$ & & 26.11 & 0.892 & 0.139 \\
$32^3$ & & 23.49 & 0.859 & 0.174 \\
\bottomrule
\end{tabular}
\begin{tabular}{@{}llccc@{}}
\toprule
Rendering Formula & & PSNR $\uparrow$ & SSIM $\uparrow$ & LPIPS $\downarrow$ \\ \cmidrule(r){1-1} \cmidrule(l){3-5}
Max [29], used in NeRF [1] & & 30.57 & 0.950 & 0.065 \\
Neural Volumes [16] & & 27.54 & 0.906 & 0.201 \\
\bottomrule
\end{tabular}
5. Discussion
Section Summary: This method creates highly realistic 3D scene models and new viewpoint images that match top existing techniques in quality but train hundreds of times faster, using simple core ideas like a workable math model for rendering, smooth data representation, and built-in error controls. While it can produce visual glitches similar to other approaches for incomplete data problems, these differ in type and don't hurt overall scores much, and tweaking settings per scene could improve results given the quick training. Looking ahead, it could add features like better smoothing for sharp edges, color adjustments, faster data handling, and open doors to advanced uses such as complex lighting simulations or building large 3D libraries from photos.
We present a method for photorealistic scene modeling and novel viewpoint rendering that produces results with comparable fidelity to the state-of-the-art, while taking orders of magnitude less time to train. Our method is also strikingly straightforward, shedding light on the core elements that are necessary for solving 3D inverse problems: a differentiable forward model, a continuous representation (in our case, via trilinear interpolation), and appropriate regularization. We acknowledge that the ingredients for this method have been available for a long time, however nonlinear optimization with tens of millions of variables has only recently become accessible to the computer vision practitioner.
Limitations and Future Work.
As with any underdetermined inverse problem, our method is susceptible to artifacts. Our method exhibits different artifacts than neural methods, as shown in Figure 9, but both methods achieve similar quality in terms of standard metrics (as presented in Section 4). Future work may be able to adjust or mitigate these remaining artifacts by studying different regularization priors and/or more physically accurate differentiable rendering functions.
Although we report all of our results for each dataset with a fixed set of hyperparameters, there is no optimal a priori setting of the TV weight $\lambda_{TV}$. In practice better results may be obtained by tuning this parameter on a scene-by-scene basis, which is possible due to our fast training time. This is expected because the scale, smoothness, and number of training views varies between scenes. We note that NeRF also has hyperparameters to be set such as the length of positional encoding, learning rate, and number of layers, and tuning these may also increase performance on a scene-by-scene basis.

Our method should extend naturally to support multiscale rendering with proper anti-aliasing through voxel cone-tracing, similar to the modifications in Mip-NeRF [44]. Another easy addition is tone-mapping to account for white balance and exposure changes, which we expect would help especially in the real $360^\circ$ scenes. A hierarchical data structure (such as an octree) may provide additional speedup compared to our sparse array implementation, provided that differentiable interpolation is preserved.
Since our method is two orders of magnitude faster than NeRF, we believe that it may enable downstream applications currently bottlenecked by the performance of NeRF–for example, multi-bounce lighting and 3D generative models across large databases of scenes. By combining our method with additional components such as camera optimization and large-scale voxel hashing, it may enable a practical pipeline for end-to-end photorealistic 3D reconstruction.
Acknowledgements
Section Summary: The acknowledgements highlight that researchers Utkarsh Singhal and Sara Fridovich-Keil explored a similar concept using point clouds before this project began, and express gratitude to Ren Ng for his useful suggestions and to Hang Gao for reviewing an early draft of the paper. The work received funding from several sources, including the CONIX Research Center as part of DARPA's JUMP program, a Google research award to Angjoo Kanazawa, and various grants to Benjamin Recht from the Office of Naval Research, the National Science Foundation, and DARPA. Additionally, Sara Fridovich-Keil and Matthew Tancik are supported by National Science Foundation Graduate Research Fellowships.
We note that Utkarsh Singhal and Sara Fridovich-Keil tried a related idea with point clouds some time prior to this project. Additionally, we would like to thank Ren Ng for helpful suggestions and Hang Gao for reviewing a draft of the paper. The project is generously supported in part by the CONIX Research Center, one of six centers in JUMP, a Semiconductor Research Corporation (SRC) program sponsored by DARPA; a Google research award to Angjoo Kanazawa; Benjamin Recht's ONR awards N00014-20-1-2497 and N00014-18-1-2833, NSF CPS award 1931853, and the DARPA Assured Autonomy program (FA8750-18-C-0101). Sara Fridovich-Keil and Matthew Tancik are supported by the NSF GRFP.
Appendix
Section Summary: The appendix provides supplementary details on experiments, including additional results, visualizations, and comparisons with previous methods, while recommending a video for broader scene demonstrations. It describes the implementation using a sparse data structure with a pointer grid and data table for efficient rendering and training, along with specifics like CUDA optimizations, color clipping, thresholding techniques, optimizer settings, and stochastic total variation losses to smooth the model. For synthetic scenes, training starts at low resolution and upsamples after pruning, often disabling regularization later for speed, while forward-facing scenes use progressive upsampling to high resolutions with density-based pruning and sparsity penalties to handle limited viewpoints.
A. Overview
In the supplementary material, we include additional experimental details and present results and visualizations of further ablation studies. We also present full, per-scene quantitative and visual comparisons between our method and prior work. We encourage the reader to see the video for results of our method on a wide range of scenes.
B. Experimental Details
B.1 Implementation Details
As briefly discussed in Section 3.2, we use a simple data structure which consists of a data table in addition to a dense grid, where each cell is either NULL or a pointer into the data table. Each entry in the data table consists of the density value and the SH coefficients for each of the RGB color channels. NULL cells are considered to have all 0 values. This data structure allows for reasonably efficient trilinear interpolation both in the forward and backward passes while maintaining sparsity; due to the relatively large memory requirements to store the SH coefficients, gradients, and RMSProp running averages, the dense pointer grid is usually not dominant in size. Nevertheless, reading the pointers currently appears to take a significant amount of rendering time, and optimizations are likely possible.
Our main CUDA rendering and gradient kernels simultaneously parallelize across rays, colors, and SH coefficients. Each CUDA warp (32 threads) handles one ray, with threads processing one SH coefficient each; since coefficients are stored contiguously, this means access to global memory is highly coalesced. The SH coefficients are combined into colors using warp-level operations from NVIDIA CUB [59]. These features are particularly significant in the case of trilinear interpolation.
Note that in order to correctly perform trilinear color interpolation, instead of using the sigmoid function to ensure that predicted sample colors are always between 0 and 1 as in NeRF [1], we simply clip negative color values to 0 with a ReLU to preserve linearity as much as possible.
We use weight-based thresholding (as in PlenOctrees [2]) for the synthetic and real, $360^\circ$ scenes, and opacity-based thresholding for the forward-facing scenes. The reason for this is that some content (especially at the edges) in the forward-facing scenes is not visible in most of the training views, so weight-based thresholding tends to prune these sparsely-supervised features.
We use a batch size of 5000 rays and optimize with RMSProp [54]. For $\sigma$ we use the same delayed exponential learning rate schedule as Mip-NeRF [44], where the exponential is scaled by a learning rate of 30 (this is where the exponential would start, if not for the delay) and decays to 0.05 at step 250000, with an initial delay period of 15000 steps. For SH we use a pure exponential decay learning rate schedule, with an initial learning rate of 0.01 that decays to $5 \times 10^{-6}$ at step 250000.
The TV losses are evaluated stochastically; they are applied only to 1% of all voxels in the grid in each step. Note that empty voxels can be selected, as their neighbors may not be empty. In practice, for performance reasons, we always apply the TV regularization on random contiguous segments of voxels (in the order that the pointer grid is stored). This is much faster to evaluate on the GPU due to locality. In all cases, the voxel differences in the TV loss defined below Equation 2 is in practice normalized by the voxel resolution in each dimension, relative to 256 (for historical reasons):
$ \Delta_x((i, j, k), d) = \frac{|V_d (i + 1, j, k) - V_d (i, j, k)|}{256 / D_x} $
Where $D_x$ is the grid resolution in the $x$ dimension, and $V_d (i, j, k)$ is the $d$ th value of voxel $(i, j, k)$ (either density or a SH coefficient). We scale $\Delta_y, \Delta_z$ analogously. Note that the same loss is applied in NDC and to the background model, except in the background model, the TV also wraps around the edges of the equirectangular image. For SH, empty grid cells and edges are considered to have the same value as the current cell (instead of 0) for purposes of TV.
B.2 Synthetic experiments
On the synthetic scenes, we found that our method performs nearly identically when TV regularization is present only in the first stage of optimization; turning off the regularization after pruning voxels and increasing resolution reduces our training time modestly. We suspect (see Table 3) this is due to the large number of training views (100) available for these scenes as well as the low level of noise; for the other datasets we retain TV regularization throughout optimization.
We start at resolution $256^3$, prune and upsample to resolution $512^3$ after 38400 steps (the equivalent of 3 epochs), and optimize for a total of 128000 steps (the equivalent of 10 epochs). We prune using a weight threshold of 0.256, and use $\lambda_{TV}$ of $1 \times 10^{-5}$ for $\sigma$ and $1 \times 10^{-3}$ for SH, only during the initial 38400 steps (and then turn off regularization after pruning and upsampling, for faster optimization).
B.3 Forward-facing experiments
For the forward-facing scenes we start at resolution $256\times256\times128$, prune and upsample to resolution $512\times512\times128$ at step 38400, prune and upsample to resolution $1408\times1156\times128$ at step 76800, and optimize for a total of 128000 steps. The final grid resolution is derived from the image resolution of the dataset, with some padding added on each side. We prune using a $\sigma$ threshold of 5, use $\lambda_{TV}$ of $5 \times 10^{-4}$ for $\sigma$ and $5 \times 10^{-3}$ for SH, and use a sparsity penalty $\lambda_s$ of $1 \times 10^{-12}$ to encourage empty voxels.
While these TV parameters work well for the forward-facing NeRF scenes, more generally, we find that sometimes it is preferrable to use $\lambda_{TV}$ $5 \times 10^{-3}$ for density and $5 \times 10^{-2}$ for SH, which reduces artifacts while blurring the scene more. This is used for some of the examples in the video, for example the piano. In general, since scenes differ significantly in content, camera noise, and actual scale, a hyperparameter sweep of the TV weights can be helpful, and using different TV values across the scenes would improve the metrics for the NeRF scenes as well.
B.4 $360^\circ$ experiments
For the $360^\circ$ scenes our foreground Plenoxel grid starts at resolution $128^3$; we prune and upsample to $256^3$, $512^3$, and $640^3$ with 25600 steps in between each upsampling. We optimize for a total of 102400 steps. We prune using a weight threshold of 1.28, and use $\lambda_{TV}$ of $5 \times 10^{-5}$ for $\sigma$ and $5 \times 10^{-3}$ for SH for the inner grid and $\lambda_{TV}$ of $1 \times 10^{-3}$ for both $\sigma$ and SH for the 64 background grid layers of resolution $2048\times1024$. We use $\lambda_s$ of $1 \times 10^{-11}$ and $\lambda_\beta$ of $1 \times 10^{-5}$. For simplicity of implementation, we did not use coarse-to-fine for the background and only use $\sigma$ thresholding. We also do not use the delayed learning rate function for the background, opting instead to use an exponential decay to allow the background to optimize faster than the foreground at the beginning.
While the TV weights were fixed for these scenes, in general, a hyperparameter sweep of the TV weights can be helpful. For more general scenes, it is sometimes useful to use a near-bound on the camera rays (as in NeRF) to prevent floaters very close to the camera, or to only begin optimizing the foreground after, say, 1000 iterations. Further sparsity losses to encourage the weight distribution to be a delta function may also help.
C. Ablation Studies
We visualize ablations on the synthetic lego scene in Figure 10. In addition to comparing nearest neighbor and trilinear interpolation, we also experimented with tricubic interpolation, which produces a function approximation that is both continuous (like trilinear interpolation) and smooth. However, we found tricubic interpolation offered negligible improvements compared to trilinear, in exchange for a substantial increase in computation (this increase in computation is why we do not include a full ablation table for tricubic interpolation).
![**Figure 10:** **Visual results of ablation studies** on the synthetic lego scene. Trilinear interpolation at resolution $256^3$ is quite similar to our full model at resolution $512^3$. Nearest neighbor interpolation shows clear voxel artifacts. Trilinear interpolation at lower resolution appears less detailed. Reducing the number of training views produces visual artifacts that are mostly resolved by increasing the TV regularization. Optimizing and rendering with the Neural Volumes [16] formula produces different visual artifacts.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/7cqssx6b/complex_fig_1de4a1865cef.png)
\begin{tabular}{@{}llccc@{}}
\toprule
LR Schedule & & PSNR $\uparrow$ & SSIM $\uparrow$ & LPIPS $\downarrow$ \\ \cmidrule(r){1-1} \cmidrule(l){3-5}
Exp for SH, Delayed for $\sigma$ [44] & & 30.57 & 0.950 & 0.065 \\
Exp for SH and $\sigma$ & & 30.58 & 0.950 & 0.066 \\
Exp for SH, Constant for $\sigma$ & & 30.37 & 0.948 & 0.068 \\
Constant for SH and $\sigma$ & & 30.13 & 0.945 & 0.075 \\
\bottomrule
\end{tabular}
\begin{tabular}{@{}llccc@{}}
\toprule
Optimizer & & PSNR $\uparrow$ & SSIM $\uparrow$ & LPIPS $\downarrow$ \\ \cmidrule(r){1-1} \cmidrule(l){3-5}
RMSProp [54] for SH and $\sigma$ & & 30.57 & 0.950 & 0.065 \\
RMSProp for SH, SGD for $\sigma$ & & 30.20 & 0.946 & 0.072 \\
SGD for SH, RMSProp for $\sigma$ & & 29.82 & 0.940 & 0.076 \\
SGD for SH and $\sigma$ & & 29.35 & 0.932 & 0.087 \\
\bottomrule
\end{tabular}
\begin{tabular}{@{}llccc@{}}
\toprule
Regularizer & & PSNR $\uparrow$ & SSIM $\uparrow$ & LPIPS $\downarrow$ \\ \cmidrule(r){1-1} \cmidrule(l){3-5}
TV SH, TV $\sigma$, Sparsity & & 26.29 & 0.839 & 0.210 \\
- Sparsity & & 26.31 & 0.839 & 0.210 \\
- TV $\sigma$ & & 25.25 & 0.807 & 0.226 \\
- TV SH & & 25.80 & 0.814 & 0.234 \\
\bottomrule
\end{tabular}
Table 6 and Table 7 show ablations over learning rate schedule and optimizer, respectively. We find that Plenoxel optimization is reasonably robust to both of these hyperparameters, although there is a noticeable improvement from using RMSProp compared to SGD, particularly for the spherical harmonic coefficients. Note that when comparing different learning rate schedules and optimizers, we tune the initial learning rate separately for each row to provide the best results possible for each configuration.
Table 8 shows ablation over regularization, for the forward-facing scenes. We find that TV regularization is important for these scenes, likely due to their low number of training images. Regularization on opacity has a quantitatively larger effect than regularization on spherical harmonics, but both are important for avoiding visual artifacts (see Figure 3).
Table 5 compares the performance of Plenoxels when trained with the rendering formula used in NeRF (originally from Max [29]) and when trained with the rendering formula used in Neural Volumes [16]. The Max formula is defined in Equation 1 and rewritten here in a slightly more convenient format:
$ \begin{align} T_i &= \exp \left(-\sum_{j=1}^{i-1} \sigma_j \delta_j \right) \ \hat C(\textbf{r}) &= \sum_{i=1}^N (T_i - T_{i+1})\textbf{c}_i \end{align} $
The Neural Volumes formula is (up to optimizing in log space):
$ \begin{align} T_i &= \min \left{1, ~ \sum_{j=1}^{i-1} \exp(-\delta_i \sigma_i) \right} \ \hat C(\textbf{r}) &= \sum_{i=1}^N (T_i - T_{i+1})\textbf{c}_i \end{align} $
These formulas only differ in their definition of the transmittance $T_i$. In particular, the Neural Volumes formula treats $\alpha_i$, the fraction of the ray contributed by sample $i$, as a function of the opacity and sampling distance of sample $i$ only. In contrast, the contribution of sample $i$ in the Max formula depends on the opacity of sample $i$ as well as the opacities of all preceding samples along the ray. In essence, opacity in the Neural Volumes formula is absolute and ray-independent (except for clipping the total contribution to 1), whereas opacity in the Max formula denotes the fraction of incoming light that each sample absorbs, a ray-dependent quantity. As we show in Table 5, the Max formula results in substantially better performance; we suspect this difference is due to its more physically-accurate modeling of transmittance.
D. Per-Scene Results
D.1 Synthetic, Bounded Scenes
Full, per-scene results for the 8 synthetic scenes from NeRF are presented in Table 10 and Figure 12. Note that the values for JAXNeRF are from our own rerunning with centered pixels (we ran JAXNeRF in parallel across 4 GPUs and multiplied the times by 4 to account for this parallelization).
D.2 Real, Forward-Facing Scenes
Full, per-scene results for the 8 forward-facing scenes from NeRF are presented in Table 11. Note that the values for JAXNeRF are from our own rerunning with centered pixels (we ran JAXNeRF in parallel across 4 GPUs and multiplied the times by 4 to account for this parallelization).
D.3 Real, $360^{\circ}$ Scenes
Full, per-scene results for the four $360^\circ$ scenes from Tanks and Temples [57] are presented in Table 9. Note that the values for NeRF++ appear slightly different from the paper; we re-evaluated the metrics independently using VGG LPIPS and standard SSIM, from rendered images shared by the original authors.
\begin{tabular}{llcccclc}
\multicolumn{8}{c}{PSNR $\uparrow$} \\
\toprule
& & M60 & Playground & Train & Truck & & Mean \\ \cmidrule(){1-1} \cmidrule(){3-7} \cmidrule(){8-8}
Ours & & 17.93 & 23.03 & 17.97 & 22.67 & & 20.40 \\
NeRF++ [9] & & 18.49 & 22.93 & 17.77 & 22.77 & & 20.49 \\
\bottomrule
& & & & & & & \\
\multicolumn{8}{c}{SSIM $\uparrow$} \\
\toprule
& & M60 & Playground & Train & Truck & & Mean \\ \cmidrule(){1-1} \cmidrule(){3-7} \cmidrule(){8-8}
Ours & & 0.687 & 0.712 & 0.629 & 0.758 & & 0.696 \\
NeRF++ & & 0.650 & 0.672 & 0.558 & 0.712 & & 0.648 \\
\bottomrule
& & & & & & & \\
\multicolumn{8}{c}{LPIPS $\downarrow$} \\
\toprule
& & M60 & Playground & Train & Truck & & Mean \\ \cmidrule(){1-1} \cmidrule(){3-7} \cmidrule(){8-8}
Ours & & 0.439 & 0.435 & 0.443 & 0.364 & & 0.420 \\
NeRF++ & & 0.481 & 0.477 & 0.531 & 0.424 & & 0.478 \\
\bottomrule
& & & & & & & \\
\multicolumn{8}{c}{Optimization Time $\downarrow$} \\
\toprule
& & M60 & Playground & Train & Truck & & Mean \\ \cmidrule(){1-1} \cmidrule(){3-7} \cmidrule(){8-8}
Ours & & 25.5m & 26.3m & 29.5m & 28.0m & & 27.3m \\
\bottomrule
\end{tabular}
\begin{tabular}{llcccccccclc}
\multicolumn{12}{c}{PSNR $\uparrow$} \\
\toprule
& & Chair & Drums & Ficus & Hotdog & Lego & Materials & Mic & Ship & & Mean \\ \cmidrule(){1-1} \cmidrule(){3-10} \cmidrule(){12-12}
Ours & & 33.98 & 25.35 & 31.83 & 36.43 & 34.10 & 29.14 & 33.26 & 29.62 & & 31.71 \\
NV [16] & & 28.33 & 22.58 & 24.79 & 30.71 & 26.08 & 24.22 & 27.78 & 23.93 & & 26.05 \\
JAXNeRF [45, 1] & & 34.20 & 25.27 & 31.15 & 36.81 & 34.02 & 30.30 & 33.72 & 29.33 & & 31.85 \\
\bottomrule
& & & & & & & & & & & \\
\multicolumn{12}{c}{SSIM $\uparrow$} \\
\toprule
& & Chair & Drums & Ficus & Hotdog & Lego & Materials & Mic & Ship & & Mean \\ \cmidrule(){1-1} \cmidrule(){3-10} \cmidrule(){12-12}
Ours & & 0.977 & 0.933 & 0.976 & 0.980 & 0.975 & 0.949 & 0.985 & 0.890 & & 0.958 \\
NV & & 0.916 & 0.873 & 0.910 & 0.944 & 0.880 & 0.888 & 0.946 & 0.784 & &0.893 \\
JAXNeRF & & 0.975 & 0.929 & 0.970 & 0.978 & 0.970 & 0.955 & 0.983 & 0.868 & & 0.954 \\
\bottomrule
& & & & & & & & & & & \\
\multicolumn{12}{c}{LPIPS $\downarrow$} \\
\toprule
& & Chair & Drums & Ficus & Hotdog & Lego & Materials & Mic & Ship & & Mean \\ \cmidrule(){1-1} \cmidrule(){3-10} \cmidrule(){12-12}
Ours & & 0.031 & 0.067 & 0.026 & 0.037 & 0.028 & 0.057 & 0.015 & 0.134 & & 0.049 \\
NV & & 0.109 & 0.214 & 0.162 & 0.109 & 0.175 & 0.130 & 0.107 & 0.276 & & 0.160 \\
JAXNeRF & & 0.036 & 0.085 & 0.037 & 0.074 & 0.068 & 0.057 & 0.023 & 0.192 & & 0.072 \\
\bottomrule
& & & & & & & & & & & \\
\multicolumn{12}{c}{Optimization Time $\downarrow$} \\
\toprule
& & Chair & Drums & Ficus & Hotdog & Lego & Materials & Mic & Ship & & Mean \\ \cmidrule(){1-1} \cmidrule(){3-10} \cmidrule(){12-12}
Ours & & 9.6m & 9.8m & 8.8m & 12.5m & 10.8m & 11.0m & 8.2m & 18.0m & & 11.1m \\
JAXNeRF & & 37.8h & 37.8h & 37.7h & 38.0h & 26.0h & 38.1h & 37.8h & 26.0h & & 34.9h \\
\bottomrule
\end{tabular}
![**Figure 11:** **Synthetic scenes.** We show a random view from each of the synthetic scenes, comparing the ground truth, Neural Volumes [16], JAXNeRF [1, 45], and our Plenoxels.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/7cqssx6b/complex_fig_09830a71fed3.png)
![**Figure 11:** **Synthetic scenes.** We show a random view from each of the synthetic scenes, comparing the ground truth, Neural Volumes [16], JAXNeRF [1, 45], and our Plenoxels.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/7cqssx6b/complex_fig_13a79597be29.png)
\begin{tabular}{llcccccccclc}
\multicolumn{12}{c}{PSNR $\uparrow$} \\
\toprule
& & Fern & Flower & Fortress & Horns & Leaves & Orchids & Room & T-Rex & & Mean \\ \cmidrule(){1-1} \cmidrule(){3-10} \cmidrule(){12-12}
Ours & & 25.46 & 27.83 & 31.09 & 27.58 & 21.41 & 20.24 & 30.22 & 26.48 & & 26.29 \\
LLFF [21] & & 28.42 & 22.85 & 19.52 & 29.40 & 18.52 & 25.46 & 24.15 & 24.70 & & 24.13 \\
JAXNeRF [45, 1] & & 25.20 & 27.80 & 31.57 & 27.70 & 21.10 & 20.37 & 32.81 & 27.12 & & 26.71 \\
\bottomrule
& & & & & & & & & & & \\
\multicolumn{12}{c}{SSIM $\uparrow$} \\
\toprule
& & Fern & Flower & Fortress & Horns & Leaves & Orchids & Room & T-Rex & & Mean \\ \cmidrule(){1-1} \cmidrule(){3-10} \cmidrule(){12-12}
Ours & & 0.832 & 0.862 & 0.885 & 0.857 & 0.760 & 0.687 & 0.937 & 0.890 & & 0.839 \\
LLFF & & 0.932 & 0.753 & 0.697 & 0.872 & 0.588 & 0.844 & 0.857 & 0.840 & & 0.798 \\
JAXNeRF & & 0.798 & 0.840 & 0.890 & 0.840 & 0.703 & 0.649 & 0.952 & 0.890 & & 0.820 \\
\bottomrule
& & & & & & & & & & & \\
\multicolumn{12}{c}{LPIPS $\downarrow$} \\
\toprule
& & Fern & Flower & Fortress & Horns & Leaves & Orchids & Room & T-Rex & & Mean \\ \cmidrule(){1-1} \cmidrule(){3-10} \cmidrule(){12-12}
Ours & & 0.224 & 0.179 & 0.180 & 0.231 & 0.198 & 0.242 & 0.192 & 0.238 & & 0.210 \\
LLFF & & 0.155 & 0.247 & 0.216 & 0.173 & 0.313 & 0.174 & 0.222 & 0.193 & & 0.212 \\
JAXNeRF & & 0.272 & 0.198 & 0.151 & 0.249 & 0.305 & 0.307 & 0.164 & 0.235 & & 0.235 \\
\bottomrule
& & & & & & & & & & & \\
\multicolumn{12}{c}{Optimization Time $\downarrow$} \\
\toprule
& & Fern & Flower & Fortress & Horns & Leaves & Orchids & Room & T-Rex & & Mean \\ \cmidrule(){1-1} \cmidrule(){3-10} \cmidrule(){12-12}
Ours & & 23.7m & 22.0m & 31.2m & 26.3m & 13.3m & 23.4m & 28.8m & 24.8m & & 24.2m \\
JAXNeRF & & 38.9h & 38.8h & 38.6h & 38.7h & 38.8h & 38.7h & 39.1h & 38.6h & & 38.8h \\
\bottomrule
\end{tabular}
![**Figure 12:** **Forward-facing scenes.** We show a random view from each of the forward-facing scenes, comparing the ground truth, JAXNeRF [1, 45], and our Plenoxels.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/7cqssx6b/complex_fig_5f3cd2f482ad.png)
![**Figure 12:** **Forward-facing scenes.** We show a random view from each of the forward-facing scenes, comparing the ground truth, JAXNeRF [1, 45], and our Plenoxels. Note that these two methods have different behaviors in unsupervised regions (*e.g* the bottom right in the orchids view): JAXNeRF fills in plausible textures whereas Plenoxels default to gray.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/7cqssx6b/complex_fig_16520a458fa9.png)
![**Figure 13:** **$360^\circ$ scenes.** We show a random view from each of the Tanks and Temples scenes, comparing the ground truth, NeRF++ [9], and our Plenoxels. We include two random views each for the M60 and train scenes, since the playground and truck scenes were shown in the main text.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/7cqssx6b/complex_fig_a8399f1f70ee.png)
References
Section Summary: This references section is a bibliography citing dozens of academic papers and books that form the foundation of research in computer vision and 3D graphics. It primarily highlights recent innovations in neural radiance fields, a technique for building realistic 3D scenes from 2D images to enable novel view synthesis, along with faster rendering methods and related tools like CUDA software. The list also includes older foundational works on topics such as voxel-based reconstruction, stereo matching, and volume rendering to show the evolution of these ideas.
[1] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In European conference on computer vision, pages 405–421. Springer, 2020.
[2] Alex Yu, Ruilong Li, Matthew Tancik, Hao Li, Ren Ng, and Angjoo Kanazawa. Plenoctrees for real-time rendering of neural radiance fields, 2021.
[3] Christian Reiser, Songyou Peng, Yiyi Liao, and Andreas Geiger. KiloNeRF: Speeding up neural radiance fields with thousands of tiny mlps, 2021.
[4] Daniel Rebain, Wei Jiang, Soroosh Yazdani, Ke Li, Kwang Moo Yi, and Andrea Tagliasacchi. Derf: Decomposed radiance fields, 2020.
[5] Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Chua, and Christian Theobalt. Neural sparse voxel fields, 2021.
[6] Stephan J. Garbin, Marek Kowalski, Matthew Johnson, Jamie Shotton, and Julien Valentin. Fastnerf: High-fidelity neural rendering at 200fps, 2021.
[7] Peter Hedman, Pratul P. Srinivasan, Ben Mildenhall, Jonathan T. Barron, and Paul Debevec. Baking neural radiance fields for real-time view synthesis, 2021.
[8] NVIDIA, Péter Vingelmann, and Frank H.P. Fitzek. Cuda, release: 10.2.89, 2020.
[9] Kai Zhang, Gernot Riegler, Noah Snavely, and Vladlen Koltun. NeRF++: Analyzing and improving neural radiance fields, 2020.
[10] Christopher B. Choy, Danfei Xu, JunYoung Gwak, Kevin Chen, and Silvio Savarese. 3d-r2n2: A unified approach for single and multi-view 3d object reconstruction, 2016.
[11] S.M. Seitz and C.R. Dyer. Photorealistic scene reconstruction by voxel coloring. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages 1067–1073, 1997.
[12] Seitz, Steven, Kutulakos, and Kiriakos. A theory of shape by space carving. 01 2000.
[13] Abhishek Kar, Christian Häne, and Jitendra Malik. Learning a multi-view stereo machine, 2017.
[14] Shubham Tulsiani, Tinghui Zhou, Alexei A. Efros, and Jitendra Malik. Multi-view supervision for single-view reconstruction via differentiable ray consistency, 2017.
[15] Vincent Sitzmann, Justus Thies, Felix Heide, Matthias Nießner, Gordon Wetzstein, and Michael Zollhöfer. Deepvoxels: Learning persistent 3d feature embeddings, 2019.
[16] Stephen Lombardi, Tomas Simon, Jason Saragih, Gabriel Schwartz, Andreas Lehrmann, and Yaser Sheikh. Neural volumes. ACM Transactions on Graphics, 38(4):1–14, Jul 2019.
[17] Richard Szeliski and Polina Golland. Stereo matching with transparency and matting. International Journal of Computer Vision, 32:45–61, 2004.
[18] Eric Penner and Li Zhang. Soft 3d reconstruction for view synthesis. ACM Transactions on Graphics (TOG), 36:1 – 11, 2017.
[19] Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images, 2018.
[20] Pratul P. Srinivasan, Richard Tucker, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng, and Noah Snavely. Pushing the boundaries of view extrapolation with multiplane images, 2019.
[21] Ben Mildenhall, Pratul P. Srinivasan, Rodrigo Ortiz-Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, and Abhishek Kar. Local light field fusion: Practical view synthesis with prescriptive sampling guidelines, 2019.
[22] Suttisak Wizadwongsa, Pakkapon Phongthawee, Jiraphon Yenphraphai, and Supasorn Suwajanakorn. Nex: Real-time view synthesis with neural basis expansion, 2021.
[23] Gernot Riegler, Ali Osman Ulusoy, and Andreas Geiger. Octnet: Learning deep 3d representations at high resolutions, 2017.
[24] Christian Häne, Shubham Tulsiani, and Jitendra Malik. Hierarchical surface prediction for 3d object reconstruction, 2017.
[25] Maxim Tatarchenko, Alexey Dosovitskiy, and Thomas Brox. Octree generating networks: Efficient convolutional architectures for high-resolution 3d outputs, 2017.
[26] Peng-Shuai Wang, Yang Liu, Yu-Xiao Guo, Chun-Yu Sun, and Xin Tong. O-cnn. ACM Transactions on Graphics, 36(4):1–11, Jul 2017.
[27] Aaron Knoll. A survey of octree volume rendering methods, 2006.
[28] Alan V. Oppenheim and Ronald W. Schafer. Discrete-Time Signal Processing. Prentice Hall Press, USA, 3rd edition, 2009.
[29] N. Max. Optical models for direct volume rendering. IEEE Transactions on Visualization and Computer Graphics, 1(2):99–108, 1995.
[30] James T. Kajiya and Brian P Von Herzen. Ray tracing volume densities. In Proceedings of the 11th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH '84, page 165–174, New York, NY, USA, 1984. Association for Computing Machinery.
[31] Ravi Ramamoorthi and Pat Hanrahan. On the relationship between radiance and irradiance: determining the illumination from images of a convex lambertian object. JOSA A, 18(10):2448–2459, 2001.
[32] Peter-Pike Sloan, Jan Kautz, and John Snyder. Precomputed radiance transfer for real-time rendering in dynamic, low-frequency lighting environments. ACM Trans. Graph., 21(3):527–536, July 2002.
[33] R. Basri and D.W. Jacobs. Lambertian reflectance and linear subspaces. IEEE Transactions on Pattern Analysis and Machine Intelligence, 25(2):218–233, 2003.
[34] Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. Occupancy networks: Learning 3d reconstruction in function space, 2019.
[35] Zhiqin Chen and Hao Zhang. Learning implicit fields for generative shape modeling, 2019.
[36] Julien N. P. Martel, David B. Lindell, Connor Z. Lin, Eric R. Chan, Marco Monteiro, and Gordon Wetzstein. Acorn: Adaptive coordinate networks for neural scene representation, 2021.
[37] Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. DeepSDF: Learning continuous signed distance functions for shape representation, 2019.
[38] Towaki Takikawa, Joey Litalien, Kangxue Yin, Karsten Kreis, Charles Loop, Derek Nowrouzezahrai, Alec Jacobson, Morgan McGuire, and Sanja Fidler. Neural geometric level of detail: Real-time rendering with implicit 3d shapes, 2021.
[39] Kara-Ali Aliev, Artem Sevastopolsky, Maria Kolos, Dmitry Ulyanov, and Victor Lempitsky. Neural point-based graphics. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXII 16, pages 696–712. Springer, 2020.
[40] Darius Rückert, Linus Franke, and Marc Stamminger. Adop: Approximate differentiable one-pixel point rendering, 2021.
[41] Olivia Wiles, Georgia Gkioxari, Richard Szeliski, and Justin Johnson. Synsin: End-to-end view synthesis from a single image, 2020.
[42] Christoph Lassner and Michael Zollhöfer. Pulsar: Efficient sphere-based neural rendering. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2021.
[43] Vincent Sitzmann, Michael Zollhöfer, and Gordon Wetzstein. Scene representation networks: Continuous 3d-structure-aware neural scene representations, 2020.
[44] Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P. Srinivasan. Mip-NeRF: A multiscale representation for anti-aliasing neural radiance fields, 2021.
[45] Boyang Deng, Jonathan T. Barron, and Pratul P. Srinivasan. JaxNeRF: an efficient JAX implementation of NeRF, 2020.
[46] James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018.
[47] David B. Lindell, Julien N. P. Martel, and Gordon Wetzstein. Autoint: Automatic integration for fast neural volume rendering, 2021.
[48] Matthew Tancik, Ben Mildenhall, Terrance Wang, Divi Schmidt, Pratul P. Srinivasan, Jonathan T. Barron, and Ren Ng. Learned initializations for optimizing coordinate-based neural representations, 2021.
[49] T. Neff, P. Stadlbauer, M. Parger, A. Kurz, J. H. Mueller, C. R. A. Chaitanya, A. Kaplanyan, and M. Steinberger. Donerf: Towards real‐time rendering of compact neural radiance fields using depth oracle networks. Computer Graphics Forum, 40(4):45–59, Jul 2021.
[50] Martin Piala and Ronald Clark. Terminerf: Ray termination prediction for efficient neural rendering, 2021.
[51] Petr Kellnhofer, Lars Jebe, Andrew Jones, Ryan Spicer, Kari Pulli, and Gordon Wetzstein. Neural lumigraph rendering, 2021.
[52] Leonid I Rudin and Stanley Osher. Total variation based image restoration with free local constraints. In Proceedings of 1st International Conference on Image Processing, volume 1, pages 31–35. IEEE, 1994.
[53] Jorge Nocedal and Stephen J. Wright. Numerical Optimization. Springer, New York, NY, USA, second edition, 2006.
[54] Geoffrey Hinton. RMSProp.
[55] Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4):600–612, 2004.
[56] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018.
[57] Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Trans. Graph., 36(4), July 2017.
[58] Gernot Riegler and Vladlen Koltun. Free view synthesis, 2020.
[59] Duane Merrill and NVIDIA Corporation. CUB: Cooperative primitives for CUDA C++, 2021.