Scalable Diffusion Models with Transformers
William Peebles$^{*}$
UC Berkeley
Saining Xie
New York University
$^{*}$ Work done during an internship at Meta AI, FAIR Team.
Code and project page available here.

Abstract
We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our Diffusion Transformers (DiTs) through the lens of forward pass complexity as measured by Gflops. We find that DiTs with higher Gflops—through increased transformer depth/width or increased number of input tokens—consistently have lower FID. In addition to possessing good scalability properties, our largest DiT-XL/2 models outperform all prior diffusion models on the class-conditional ImageNet 512$\times$512 and 256$\times$256 benchmarks, achieving a state-of-the-art FID of 2.27 on the latter.
Executive Summary: Diffusion models have revolutionized image generation by producing high-quality synthetic images, but their standard architecture relies on convolutional networks called U-Nets, which may limit scalability as models grow larger. Transformers, however, have transformed fields like language processing and vision tasks by scaling efficiently with more compute. This raises a timely question: can transformers replace U-Nets in diffusion models to unlock better performance and efficiency, especially as demand for photorealistic images surges in applications like design, media, and AI-driven content creation?
This document introduces Diffusion Transformers, or DiTs, a new class of diffusion models that swap the U-Net backbone for a transformer operating on image patches in a compressed latent space. The goal was to evaluate whether DiTs can generate class-conditional images on the ImageNet dataset and to assess their scaling behavior compared to traditional approaches.
The researchers trained DiT models using a two-stage process: first, compress images into a latent representation with a pre-trained autoencoder, then apply diffusion to denoise these latents using a transformer backbone. They explored variations in model size (from small to extra-large, spanning 33 million to 675 million parameters), patch sizes (to adjust input tokens from 256 to 4096), and conditioning methods for elements like noise levels and class labels. Training occurred on ImageNet subsets for 256x256 and 512x512 resolution images over hundreds of thousands to millions of steps, using standard optimization without custom tuning. Complexity was measured in gigaflops (Gflops) rather than parameters to better reflect compute demands, with evaluation focused on Fréchet Inception Distance (FID), a key metric for image quality where lower scores indicate more realistic outputs.
The analysis revealed three main findings. First, DiTs scale predictably: models with higher Gflops—achieved by deeper or wider transformers or more input tokens—consistently produced better images, with FID dropping from over 150 for small models to under 10 for the largest ones after sufficient training. A strong negative correlation emerged between Gflops and FID, holding across configurations. Second, the optimal design used adaptive layer normalization with zero initialization (adaLN-Zero blocks), which outperformed alternatives like cross-attention by up to 50% in FID reduction while adding minimal compute overhead. Third, the largest DiT-XL/2 model, at 119 Gflops, set new benchmarks: it achieved an FID of 2.27 on 256x256 ImageNet (beating the prior best of 3.60 by 37%) and 3.04 on 512x512 (improving on 3.85 by 21%), using far less compute than pixel-space U-Net models like ADM (over 1,000 Gflops).
These results mean transformers can elevate diffusion models by enabling efficient scaling without relying on convolutional biases, leading to higher-quality images at lower computational cost. For instance, DiT-XL/2 matched or exceeded U-Net performance using 5-10 times fewer Gflops, reducing training and inference expenses in resource-intensive setups. This breaks from expectations that U-Nets were essential, showing instead that transformers promote architecture unification across AI domains, potentially accelerating progress in generative AI. It also highlights that investing in model complexity yields greater returns than just extending sampling steps during generation, as smaller models couldn't catch up even with 5 times more sampling compute.
Leaders should prioritize adopting DiT backbones in diffusion pipelines, starting with integration into existing systems like Stable Diffusion for text-to-image tasks, which could cut costs by 80% while boosting output quality. Further scaling to billion-parameter DiTs or larger token counts is recommended, alongside pilots on diverse datasets beyond ImageNet to test generalization. Trade-offs include higher initial design effort versus long-term efficiency gains.
While the scaling trends are robust across tested variations, limitations include reliance on a single dataset and pre-trained autoencoders, which might introduce compression artifacts, and untested extensions to unconditional or text-conditioned generation. Confidence is high in DiTs' superiority for class-conditional image synthesis, but caution is advised for non-image domains or real-time applications until broader validations confirm these patterns.
1. Introduction
Section Summary: Machine learning has seen transformers revolutionize areas like language and vision processing, but image generation models, particularly diffusion models, have stuck with older convolutional designs called U-Nets. This paper introduces Diffusion Transformers, or DiTs, which swap out the U-Net for a transformer-based architecture proven effective in other visual tasks, showing that this change doesn't hurt performance and actually allows for better scaling. By training these models in a compressed latent space and increasing their complexity, the authors achieve top results in generating high-quality images from the ImageNet dataset, paving the way for more unified and efficient generative AI tools.
Machine learning is experiencing a renaissance powered by transformers. Over the past five years, neural architectures for natural language processing [1, 2], vision [3] and several other domains have largely been subsumed by transformers [4]. Many classes of image-level generative models remain holdouts to the trend, though—while transformers see widespread use in autoregressive models [5, 6, 7, 8], they have seen less adoption in other generative modeling frameworks. For example, diffusion models have been at the forefront of recent advances in image-level generative models [9, 10]; yet, they all adopt a convolutional U-Net architecture as the de-facto choice of backbone.
The seminal work of Ho et al. [11] first introduced the U-Net backbone for diffusion models. Having initially seen success within pixel-level autoregressive models and conditional GANs [12], the U-Net was inherited from PixelCNN++ [13, 14] with a few changes. The model is convolutional, comprised primarily of ResNet [15] blocks. In contrast to the standard U-Net [16], additional spatial self-attention blocks, which are essential components in transformers, are interspersed at lower resolutions. Dhariwal and Nichol [9] ablated several architecture choices for the U-Net, such as the use of adaptive normalization layers [17] to inject conditional information and channel counts for convolutional layers. However, the high-level design of the U-Net from Ho et al. has largely remained intact.
With this work, we aim to demystify the significance of architectural choices in diffusion models and offer empirical baselines for future generative modeling research. We show that the U-Net inductive bias is not crucial to the performance of diffusion models, and they can be readily replaced with standard designs such as transformers. As a result, diffusion models are well-poised to benefit from the recent trend of architecture unification—e.g., by inheriting best practices and training recipes from other domains, as well as retaining favorable properties like scalability, robustness and efficiency. A standardized architecture would also open up new possibilities for cross-domain research.
In this paper, we focus on a new class of diffusion models based on transformers. We call them Diffusion Transformers, or DiTs for short. DiTs adhere to the best practices of Vision Transformers (ViTs) [3], which have been shown to scale more effectively for visual recognition than traditional convolutional networks (e.g., ResNet [15]).
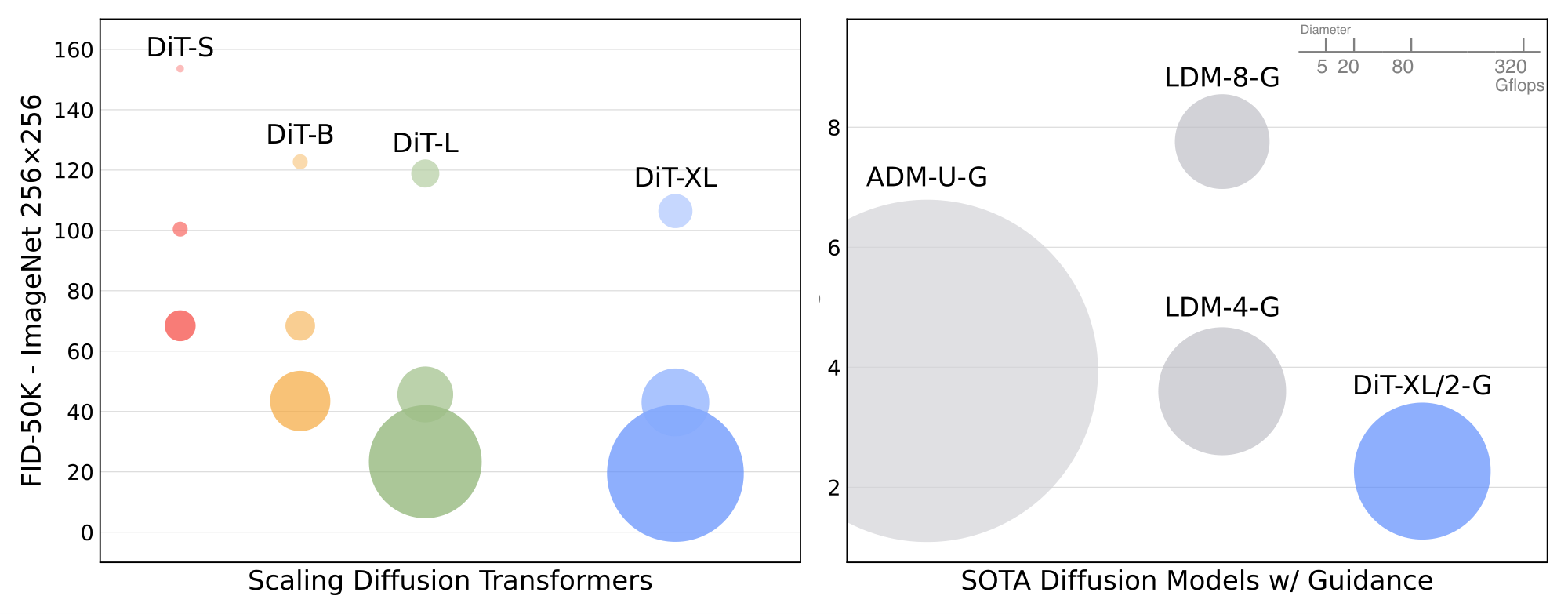
More specifically, we study the scaling behavior of transformers with respect to network complexity \emph{vs} sample quality. We show that by constructing and benchmarking the DiT design space under the Latent Diffusion Models (LDMs) [18] framework, where diffusion models are trained within a VAE's latent space, we can successfully replace the U-Net backbone with a transformer. We further show that DiTs are scalable architectures for diffusion models: there is a strong correlation between the network complexity (measured by Gflops) vs sample quality (measured by FID). By simply scaling-up DiT and training an LDM with a high-capacity backbone (118.6 Gflops), we are able to achieve a state-of-the-art result of 2.27 FID on the class-conditional $256\times 256$ ImageNet generation benchmark.
2. Related Work
Section Summary: Transformers, a type of AI model architecture, have become widely used in fields like language processing, image recognition, and game playing, showing strong performance as models grow larger with more training data and computing power; they've even been adapted to generate images by predicting pixels or using specialized data formats, and in some cases integrated into diffusion models for creating visual content like in the DALL-E system. Denoising diffusion probabilistic models, or DDPMs, have emerged as powerful tools for generating realistic images, often surpassing earlier methods like GANs, thanks to advances in sampling techniques, noise prediction, and multi-stage pipelines, though they typically rely on convolutional networks called U-Nets rather than transformers. To assess model complexity, experts often look beyond simple parameter counts to measures like computational operations (Gflops), and this work builds on prior studies of U-Nets by examining how transformers scale in diffusion-based image generation.
Transformers.
Transformers [4] have replaced domain-specific architectures across language, vision [3], reinforcement learning [19, 20] and meta-learning [21]. They have shown remarkable scaling properties under increasing model size, training compute and data in the language domain [22], as generic autoregressive models [23] and as ViTs [24]. Beyond language, transformers have been trained to autoregressively predict pixels [25, 26, 7]. They have also been trained on discrete codebooks [27] as both autoregressive models [28, 8] and masked generative models [29, 30]; the former has shown excellent scaling behavior up to 20B parameters [31]. Finally, transformers have been explored in DDPMs to synthesize non-spatial data; e.g., to generate CLIP image embeddings in DALL $\cdot$ E 2 [10, 32]. In this paper, we study the scaling properties of transformers when used as the backbone of diffusion models of images.
Denoising diffusion probabilistic models (DDPMs).
Diffusion [33, 11] and score-based generative models [34, 35] have been particularly successful as generative models of images [36, 10, 37, 18], in many cases outperforming generative adversarial networks (GANs) [38] which had previously been state-of-the-art. Improvements in DDPMs over the past two years have largely been driven by improved sampling techniques [11, 39, 40], most notably classifier-free guidance [41], reformulating diffusion models to predict noise instead of pixels [11] and using cascaded DDPM pipelines where low-resolution base diffusion models are trained in parallel with upsamplers [42, 9]. For all the diffusion models listed above, convolutional U-Nets [16] are the de-facto choice of backbone architecture. Concurrent work [43] introduced a novel, efficient architecture based on attention for DDPMs; we explore pure transformers.
Architecture complexity.
When evaluating architecture complexity in the image generation literature, it is fairly common practice to use parameter counts. In general, parameter counts can be poor proxies for the complexity of image models since they do not account for, e.g., image resolution which significantly impacts performance [44, 45]. Instead, much of the model complexity analysis in this paper is through the lens of theoretical Gflops. This brings us in-line with the architecture design literature where Gflops are widely-used to gauge complexity. In practice, the golden complexity metric is still up for debate as it frequently depends on particular application scenarios. Nichol and Dhariwal's seminal work improving diffusion models [46, 9] is most related to us—there, they analyzed the scalability and Gflop properties of the U-Net architecture class. In this paper, we focus on the transformer class.
3. Diffusion Transformers
Section Summary: Diffusion transformers, or DiTs, build on diffusion models that generate images by gradually adding noise to data and then learning to reverse the process to create new images from pure noise. To make this efficient, especially for high-resolution images, the models work in a compressed latent space using pre-trained autoencoders, and they incorporate techniques like classifier-free guidance to steer generation toward specific conditions, such as class labels, without needing extra classifiers. DiTs specifically adapt the vision transformer architecture to handle these diffusion tasks by breaking images into patches and processing them as sequences, aiming for scalable and high-performing image synthesis.
3.1 Preliminaries
Diffusion formulation.
Before introducing our architecture, we briefly review some basic concepts needed to understand diffusion models (DDPMs) [33, 11]. Gaussian diffusion models assume a forward noising process which gradually applies noise to real data $x_0$: $q(x_t|x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t}x_0, (1 - \bar{\alpha}_t)\mathbf{I})$, where constants $\bar{\alpha}_t$ are hyperparameters. By applying the reparameterization trick, we can sample $x_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon_t$, where $\epsilon_t\sim\mathcal{N}(0, \mathbf{I})$.
Diffusion models are trained to learn the reverse process that inverts forward process corruptions: $p_\theta(x_{t-1}|x_t) = \mathcal{N}(\mu_\theta(x_t), \Sigma_\theta(x_t))$, where neural networks are used to predict the statistics of $p_\theta$. The reverse process model is trained with the variational lower bound [47] of the log-likelihood of $x_0$, which reduces to $\mathcal{L}(\theta) = -p(x_0|x_1) + \sum_t \mathcal{D}{KL}(q^*(x{t-1}|x_{t}, x_0)||p_\theta(x_{t-1}|x_t))$, excluding an additional term irrelevant for training. Since both $q^*$ and $p_\theta$ are Gaussian, $\mathcal{D}{KL}$ can be evaluated with the mean and covariance of the two distributions. By reparameterizing $\mu\theta$ as a noise prediction network $\epsilon_\theta$, the model can be trained using simple mean-squared error between the predicted noise $\epsilon_\theta(x_t)$ and the ground truth sampled Gaussian noise $\epsilon_t$: $\mathcal{L}{simple}(\theta) = ||\epsilon\theta(x_t) - \epsilon_t||2^2$. But, in order to train diffusion models with a learned reverse process covariance $\Sigma\theta$, the full $\mathcal{D}{KL}$ term needs to be optimized. We follow Nichol and Dhariwal's approach [46]: train $\epsilon\theta$ with $\mathcal{L}{simple}$, and train $\Sigma\theta$ with the full $\mathcal{L}$. Once $p_\theta$ is trained, new images can be sampled by initializing $x_{t_\text{max}} \sim \mathcal{N}(0, \mathbf{I})$ and sampling $x_{t-1} \sim p_\theta(x_{t-1}|x_t)$ via the reparameterization trick.
Classifier-free guidance.
Conditional diffusion models take extra information as input, such as a class label $c$. In this case, the reverse process becomes $p_\theta(x_{t-1}|x_t, c)$, where $\epsilon_\theta$ and $\Sigma_\theta$ are conditioned on $c$. In this setting, classifier-free guidance can be used to encourage the sampling procedure to find $x$ such that $\log p(c|x)$ is high [41]. By Bayes Rule, $\log p(c|x) \propto \log p(x|c) - \log p(x)$, and hence $\nabla_x \log p(c|x) \propto \nabla_x \log p(x|c) - \nabla_x \log p(x)$. By interpreting the output of diffusion models as the score function, the DDPM sampling procedure can be guided to sample $x$ with high $p(x|c)$ by: $\hat{\epsilon}\theta(x_t, c) = \epsilon\theta(x_t, \emptyset) + s \cdot \nabla_x \log p(x|c) \propto \epsilon_\theta(x_t, \emptyset) + s \cdot (\epsilon_\theta(x_t, c) - \epsilon_\theta(x_t, \emptyset))$, where $s > 1$ indicates the scale of the guidance (note that $s=1$ recovers standard sampling). Evaluating the diffusion model with $c=\emptyset$ is done by randomly dropping out $c$ during training and replacing it with a learned "null" embedding $\emptyset$. Classifier-free guidance is widely-known to yield significantly improved samples over generic sampling techniques [41, 36, 10], and the trend holds for our DiT models.
Latent diffusion models.
Training diffusion models directly in high-resolution pixel space can be computationally prohibitive. Latent diffusion models (LDMs) [18] tackle this issue with a two-stage approach: (1) learn an autoencoder that compresses images into smaller spatial representations with a learned encoder $E$; (2) train a diffusion model of representations $z = E(x)$ instead of a diffusion model of images $x$ ($E$ is frozen). New images can then be generated by sampling a representation $z$ from the diffusion model and subsequently decoding it to an image with the learned decoder $x = D(z)$.
As shown in Figure 2, LDMs achieve good performance while using a fraction of the Gflops of pixel space diffusion models like ADM. Since we are concerned with compute efficiency, this makes them an appealing starting point for architecture exploration. In this paper, we apply DiTs to latent space, although they could be applied to pixel space without modification as well. This makes our image generation pipeline a hybrid-based approach; we use off-the-shelf convolutional VAEs and transformer-based DDPMs.
3.2 Diffusion Transformer Design Space
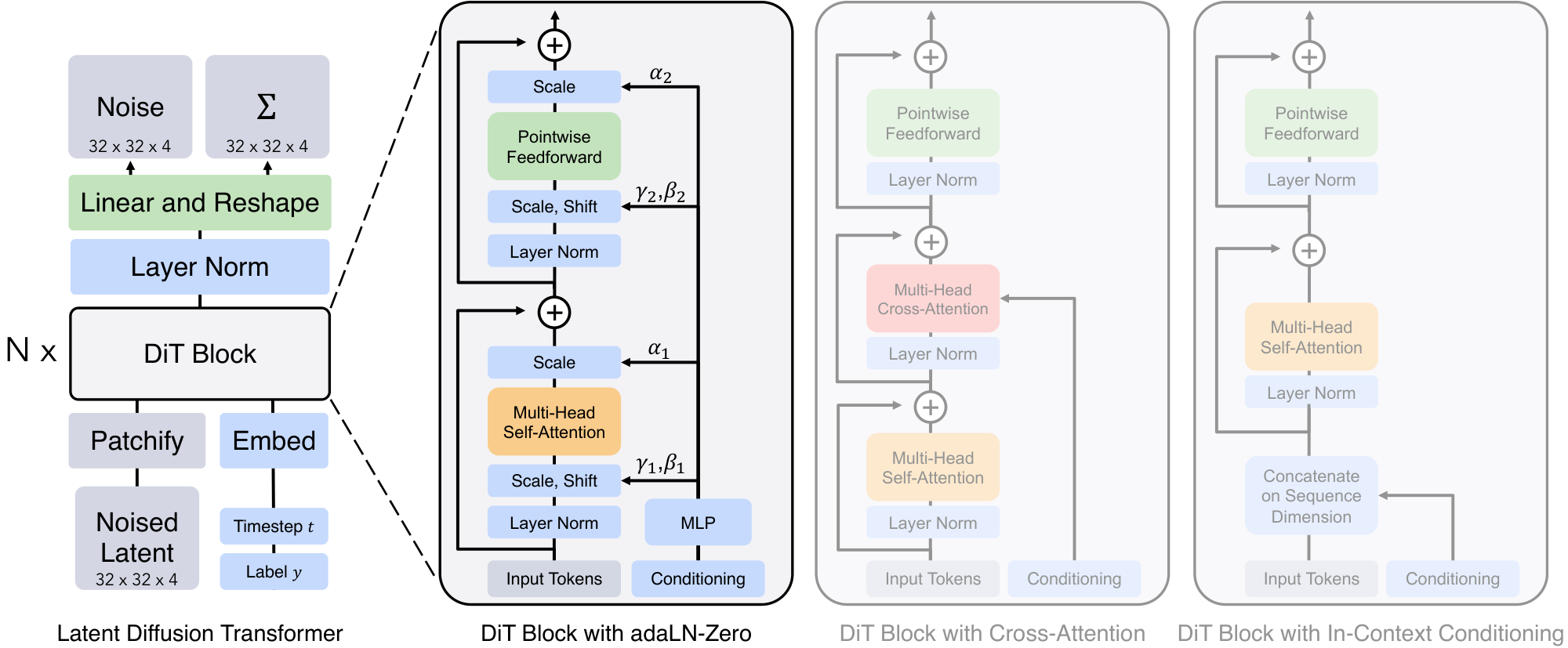
We introduce Diffusion Transformers (DiTs), a new architecture for diffusion models. We aim to be as faithful to the standard transformer architecture as possible to retain its scaling properties. Since our focus is training DDPMs of images (specifically, spatial representations of images), DiT is based on the Vision Transformer (ViT) architecture which operates on sequences of patches [3]. DiT retains many of the best practices of ViTs. Figure 3 shows an overview of the complete DiT architecture. In this section, we describe the forward pass of DiT, as well as the components of the design space of the DiT class.
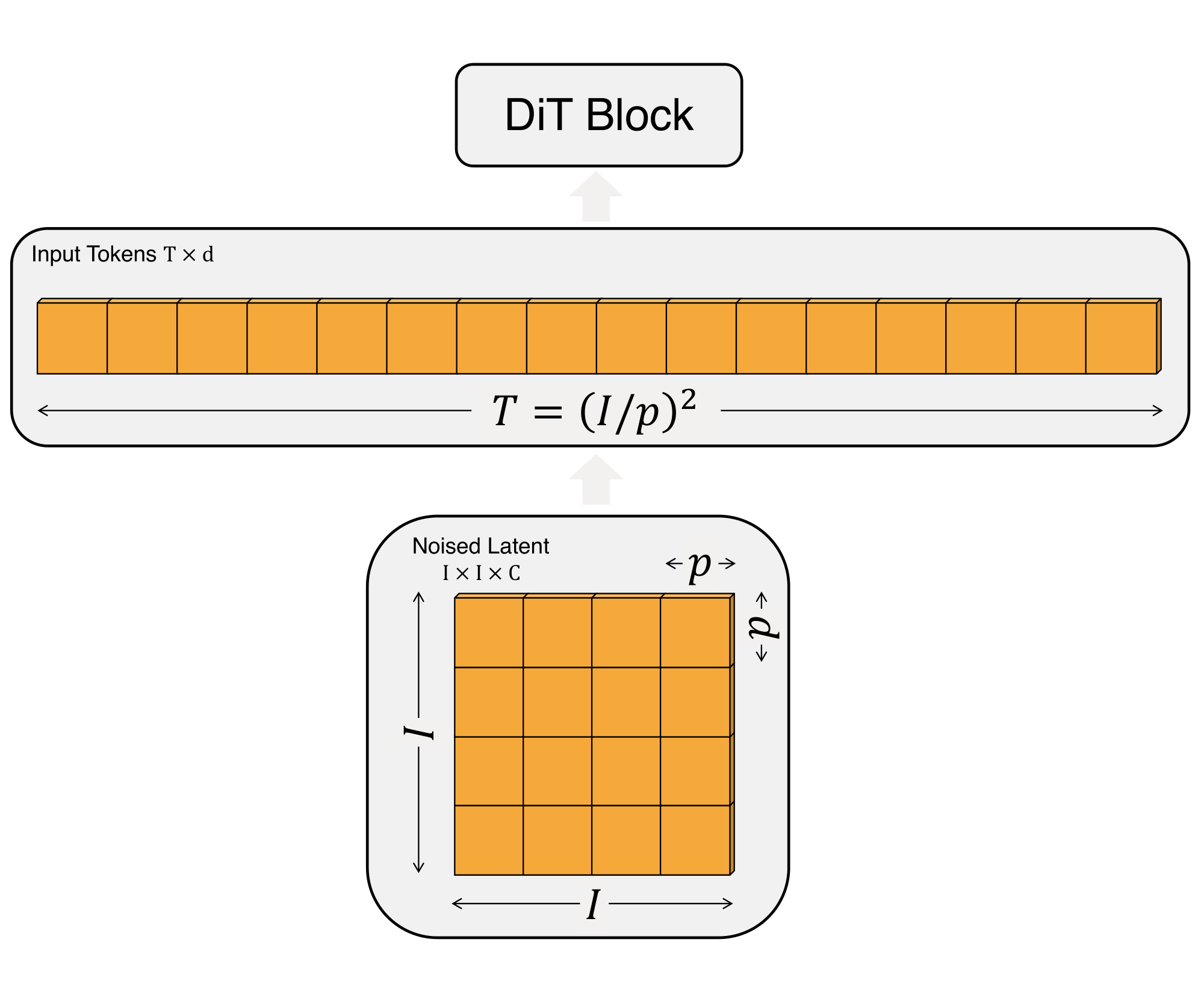
Patchify.
The input to DiT is a spatial representation $z$ (for $256\times256\times3$ images, $z$ has shape $32\times32\times4$). The first layer of DiT is "patchify, " which converts the spatial input into a sequence of $T$ tokens, each of dimension $d$, by linearly embedding each patch in the input. Following patchify, we apply standard ViT frequency-based positional embeddings (the sine-cosine version) to all input tokens. The number of tokens $T$ created by patchify is determined by the patch size hyperparameter $p$. As shown in Figure 4, halving $p$ will quadruple $T$, and thus at least quadruple total transformer Gflops. Although it has a significant impact on Gflops, note that changing $p$ has no meaningful impact on downstream parameter counts.
We add $p=2, 4, 8$ to the DiT design space.
DiT block design.
Following patchify, the input tokens are processed by a sequence of transformer blocks. In addition to noised image inputs, diffusion models sometimes process additional conditional information such as noise timesteps $t$, class labels $c$, natural language, etc. We explore four variants of transformer blocks that process conditional inputs differently. The designs introduce small, but important, modifications to the standard ViT block design. The designs of all blocks are shown in Figure 3.
- In-context conditioning. We simply append the vector embeddings of $t$ and $c$ as two additional tokens in the input sequence, treating them no differently from the image tokens. This is similar to
clstokens in ViTs, and it allows us to use standard ViT blocks without modification. After the final block, we remove the conditioning tokens from the sequence. This approach introduces negligible new Gflops to the model. - Cross-attention block. We concatenate the embeddings of $t$ and $c$ into a length-two sequence, separate from the image token sequence. The transformer block is modified to include an additional multi-head cross-attention layer following the multi-head self-attention block, similar to the original design from Vaswani et al. [4], and also similar to the one used by LDM for conditioning on class labels. Cross-attention adds the most Gflops to the model, roughly a 15% overhead.
- Adaptive layer norm (adaLN) block. Following the widespread usage of adaptive normalization layers [17] in GANs [48, 49] and diffusion models with U-Net backbones [9], we explore replacing standard layer norm layers in transformer blocks with adaptive layer norm (adaLN). Rather than directly learn dimension-wise scale and shift parameters $\gamma$ and $\beta$, we regress them from the sum of the embedding vectors of $t$ and $c$. Of the three block designs we explore, adaLN adds the least Gflops and is thus the most compute-efficient. It is also the only conditioning mechanism that is restricted to apply the same function to all tokens.
- adaLN-Zero block. Prior work on ResNets has found that initializing each residual block as the identity function is beneficial. For example, Goyal et al. found that zero-initializing the final batch norm scale factor $\gamma$ in each block accelerates large-scale training in the supervised learning setting [50]. Diffusion U-Net models use a similar initialization strategy, zero-initializing the final convolutional layer in each block prior to any residual connections. We explore a modification of the adaLN DiT block which does the same. In addition to regressing $\gamma$ and $\beta$, we also regress dimension-wise scaling parameters $\alpha$ that are applied immediately prior to any residual connections within the DiT block. We initialize the MLP to output the zero-vector for all $\alpha$; this initializes the full DiT block as the identity function. As with the vanilla adaLN block, adaLN-Zero adds negligible Gflops to the model.
We include the in-context, cross-attention, adaptive layer norm and adaLN-Zero blocks in the DiT design space.
:Table 1: Details of DiT models. We follow ViT [3] model configurations for the Small (S), Base (B) and Large (L) variants; we also introduce an XLarge (XL) config as our largest model.
| Model | Layers $N$ | Hidden size $d$ | Heads | Gflops ($I$ =32, $p$ =4) |
|---|---|---|---|---|
| DiT-S | 12 | 384 | 6 | 1.4 |
| DiT-B | 12 | 768 | 12 | 5.6 |
| DiT-L | 24 | 1024 | 16 | 19.7 |
| DiT-XL | 28 | 1152 | 16 | 29.1 |
Model size.
We apply a sequence of $N$ DiT blocks, each operating at the hidden dimension size $d$. Following ViT, we use standard transformer configs that jointly scale $N$, $d$ and attention heads [3, 24]. Specifically, we use four configs: DiT-S, DiT-B, DiT-L and DiT-XL. They cover a wide range of model sizes and flop allocations, from 0.3 to 118.6 Gflops, allowing us to gauge scaling performance. Table 1 gives details of the configs.
We add B, S, L and XL configs to the DiT design space.
Transformer decoder.
After the final DiT block, we need to decode our sequence of image tokens into an output noise prediction and an output diagonal covariance prediction. Both of these outputs have shape equal to the original spatial input. We use a standard linear decoder to do this; we apply the final layer norm (adaptive if using adaLN) and linearly decode each token into a $p \times p \times 2C$ tensor, where $C$ is the number of channels in the spatial input to DiT. Finally, we rearrange the decoded tokens into their original spatial layout to get the predicted noise and covariance.
The complete DiT design space we explore is patch size, transformer block architecture and model size.
4. Experimental Setup
Section Summary: The researchers trained class-conditional DiT models, which generate images from latent representations, at resolutions of 256 by 256 and 512 by 512 pixels using the ImageNet dataset, employing a straightforward setup with the AdamW optimizer, a fixed learning rate, and minimal data augmentation like horizontal flips, without needing advanced techniques like learning rate warmups. They incorporated a pre-trained variational autoencoder from Stable Diffusion to handle the latent space for diffusion processes, sticking closely to hyperparameters from prior work called ADM for stability and consistency across model sizes. Performance was evaluated mainly with the Fréchet Inception Distance metric on 50,000 samples using 250 diffusion steps, computed on TPU hardware with models implemented in JAX, ensuring fair comparisons without specialized guidance methods unless specified.
We explore the DiT design space and study the scaling properties of our model class. Our models are named according to their configs and latent patch sizes $p$; for example, DiT-XL/2 refers to the XLarge config and $p=2$.
Training.
We train class-conditional latent DiT models at $256\times256$ and $512\times512$ image resolution on the ImageNet dataset [51], a highly-competitive generative modeling benchmark. We initialize the final linear layer with zeros and otherwise use standard weight initialization techniques from ViT. We train all models with AdamW [52, 53]. We use a constant learning rate of $1 \times 10^{-4}$, no weight decay and a batch size of 256. The only data augmentation we use is horizontal flips. Unlike much prior work with ViTs [54, 55], we did not find learning rate warmup nor regularization necessary to train DiTs to high performance. Even without these techniques, training was highly stable across all model configs and we did not observe any loss spikes commonly seen when training transformers. Following common practice in the generative modeling literature, we maintain an exponential moving average (EMA) of DiT weights over training with a decay of 0.9999. All results reported use the EMA model. We use identical training hyperparameters across all DiT model sizes and patch sizes. Our training hyperparameters are almost entirely retained from ADM. We did not tune learning rates, decay/warm-up schedules, Adam $\beta_1$ / $\beta_2$ or weight decays.
Diffusion.
We use an off-the-shelf pre-trained variational autoencoder (VAE) model [47] from Stable Diffusion [18]. The VAE encoder has a downsample factor of 8—given an RGB image $x$ with shape $256 \times 256 \times 3$, $z = E(x)$ has shape $32 \times 32 \times 4$. Across all experiments in this section, our diffusion models operate in this $\mathcal{Z}$-space. After sampling a new latent from our diffusion model, we decode it to pixels using the VAE decoder $x = D(z)$. We retain diffusion hyperparameters from ADM [9]; specifically, we use a $t_\text{max}=1000$ linear variance schedule ranging from $1 \times 10^{-4}$ to $2 \times 10^{-2}$, ADM's parameterization of the covariance $\Sigma_\theta$ and their method for embedding input timesteps and labels.
Evaluation metrics.
We measure scaling performance with Fréchet Inception Distance (FID) [56], the standard metric for evaluating generative models of images.
We follow convention when comparing against prior works and report FID-50K using 250 DDPM sampling steps. FID is known to be sensitive to small implementation details [57]; to ensure accurate comparisons, all values reported in this paper are obtained by exporting samples and using ADM's TensorFlow evaluation suite [9]. FID numbers reported in this section do not use classifier-free guidance except where otherwise stated. We additionally report Inception Score [58], sFID [59] and Precision/Recall [60] as secondary metrics.
Compute.
We implement all models in JAX [61] and train them using TPU-v3 pods. DiT-XL/2, our most compute-intensive model, trains at roughly 5.7 iterations/second on a TPU v3-256 pod with a global batch size of 256.
5. Experiments
Section Summary: The experiments tested various designs for DiT model blocks and found that the adaLN-Zero version performed best, producing higher-quality images with less computational effort than alternatives like cross-attention or in-context methods. Researchers trained 12 different DiT models by varying their size and input patch sizes, revealing that larger models and smaller patches consistently improved image quality, as measured by FID scores, with computational efficiency (Gflops) proving more important than the number of parameters alone. Extending training on the top model, DiT-XL/2, achieved state-of-the-art results on 256x256 ImageNet images, outperforming previous diffusion models and even non-diffusion generators like StyleGAN-XL in visual fidelity and efficiency.
DiT block design.
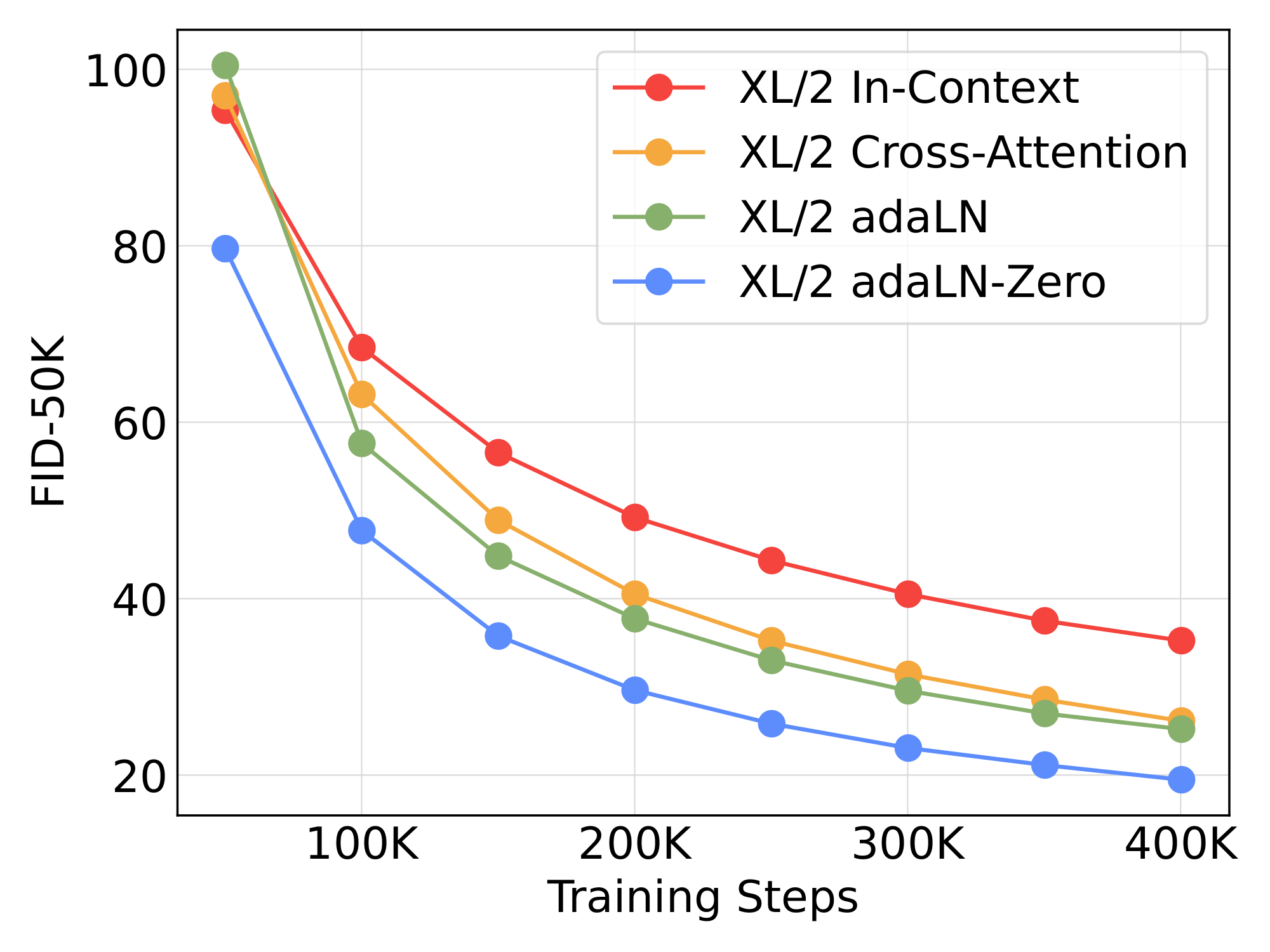
We train four of our highest Gflop DiT-XL/2 models, each using a different block design—in-context (119.4 Gflops), cross-attention (137.6 Gflops), adaptive layer norm (adaLN, 118.6 Gflops) or adaLN-zero (118.6 Gflops). We measure FID over the course of training. Figure 5 shows the results. The adaLN-Zero block yields lower FID than both cross-attention and in-context conditioning while being the most compute-efficient. At 400K training iterations, the FID achieved with the adaLN-Zero model is nearly half that of the in-context model, demonstrating that the conditioning mechanism critically affects model quality. Initialization is also important—adaLN-Zero, which initializes each DiT block as the identity function, significantly outperforms vanilla adaLN. For the rest of the paper, all models will use adaLN-Zero DiT blocks.
Scaling model size and patch size.
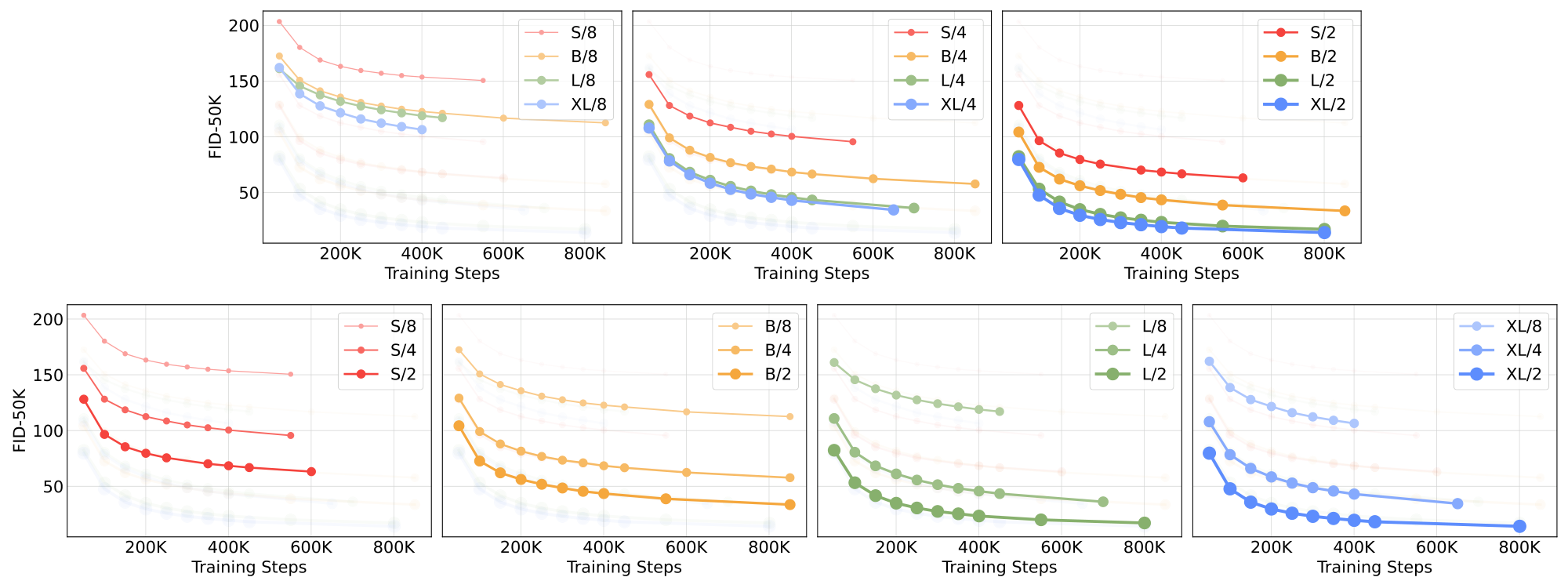
We train 12 DiT models, sweeping over model configs (S, B, L, XL) and patch sizes (8, 4, 2). Note that DiT-L and DiT-XL are significantly closer to each other in terms of relative Gflops than other configs. Figure 2 (left) gives an overview of the Gflops of each model and their FID at 400K training iterations. In all cases, we find that increasing model size and decreasing patch size yields considerably improved diffusion models.
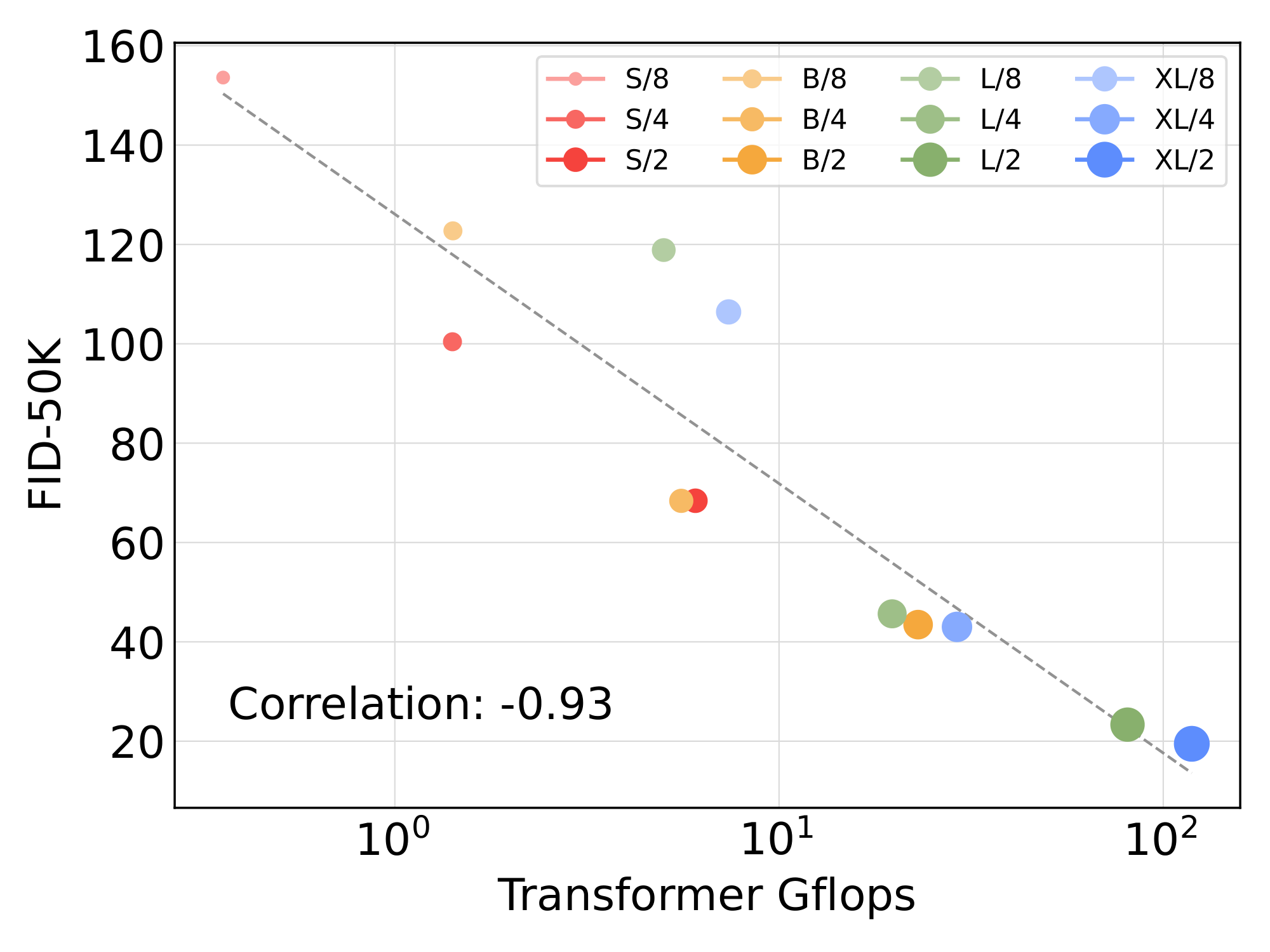
Figure 6 (top) demonstrates how FID changes as model size is increased and patch size is held constant. Across all four configs, significant improvements in FID are obtained over all stages of training by making the transformer deeper and wider. Similarly, Figure 6 (bottom) shows FID as patch size is decreased and model size is held constant. We again observe considerable FID improvements throughout training by simply scaling the number of tokens processed by DiT, holding parameters approximately fixed.
DiT Gflops are critical to improving performance.
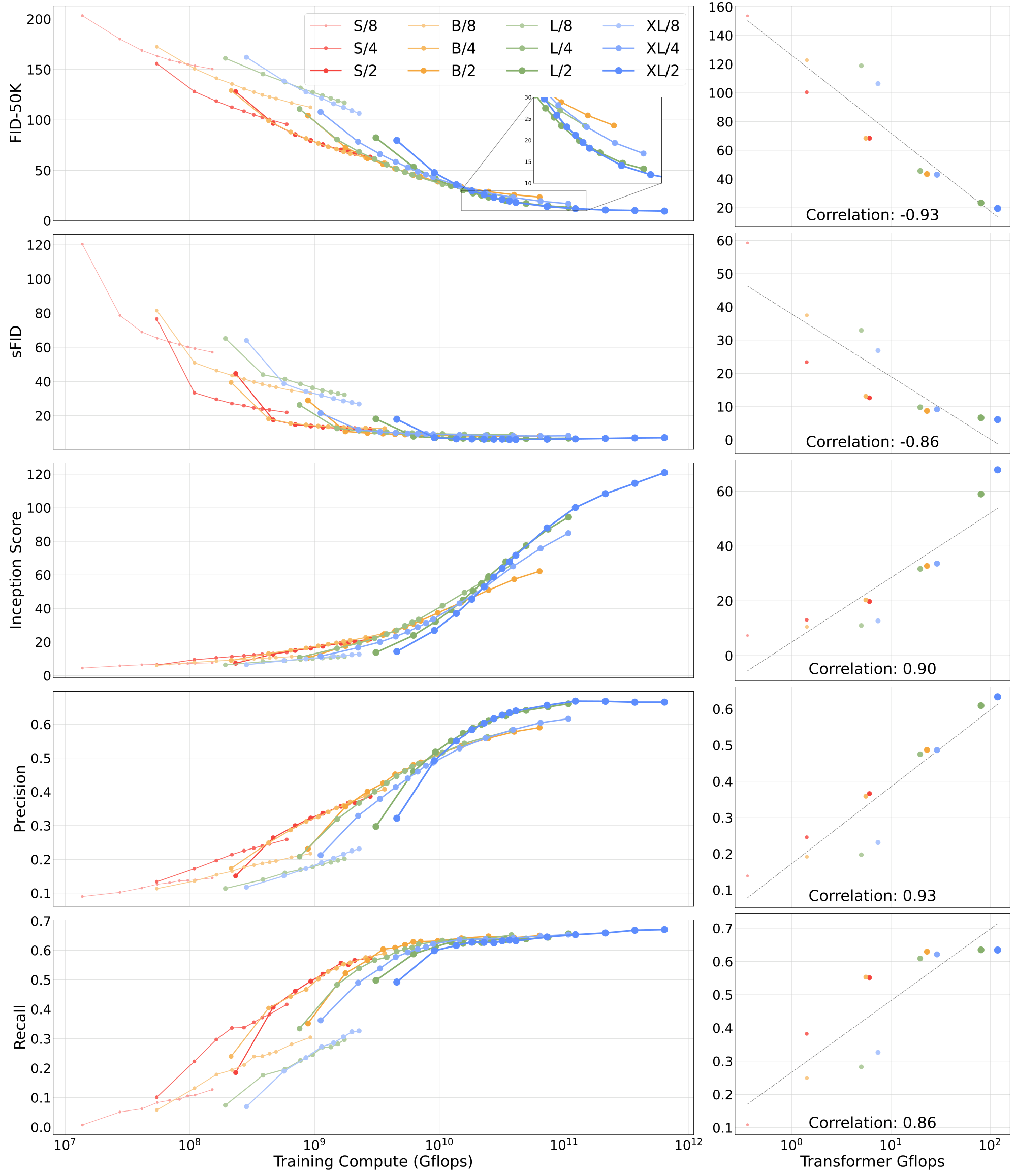
The results of Figure 6 suggest that parameter counts do not uniquely determine the quality of a DiT model. As model size is held constant and patch size is decreased, the transformer's total parameters are effectively unchanged (actually, total parameters slightly decrease), and only Gflops are increased. These results indicate that scaling model Gflops is actually the key to improved performance. To investigate this further, we plot the FID-50K at 400K training steps against model Gflops in Figure 8. The results demonstrate that different DiT configs obtain similar FID values when their total Gflops are similar (e.g., DiT-S/2 and DiT-B/4). We find a strong negative correlation between model Gflops and FID-50K, suggesting that additional model compute is the critical ingredient for improved DiT models. In Figure 12 (appendix), we find that this trend holds for other metrics such as Inception Score.
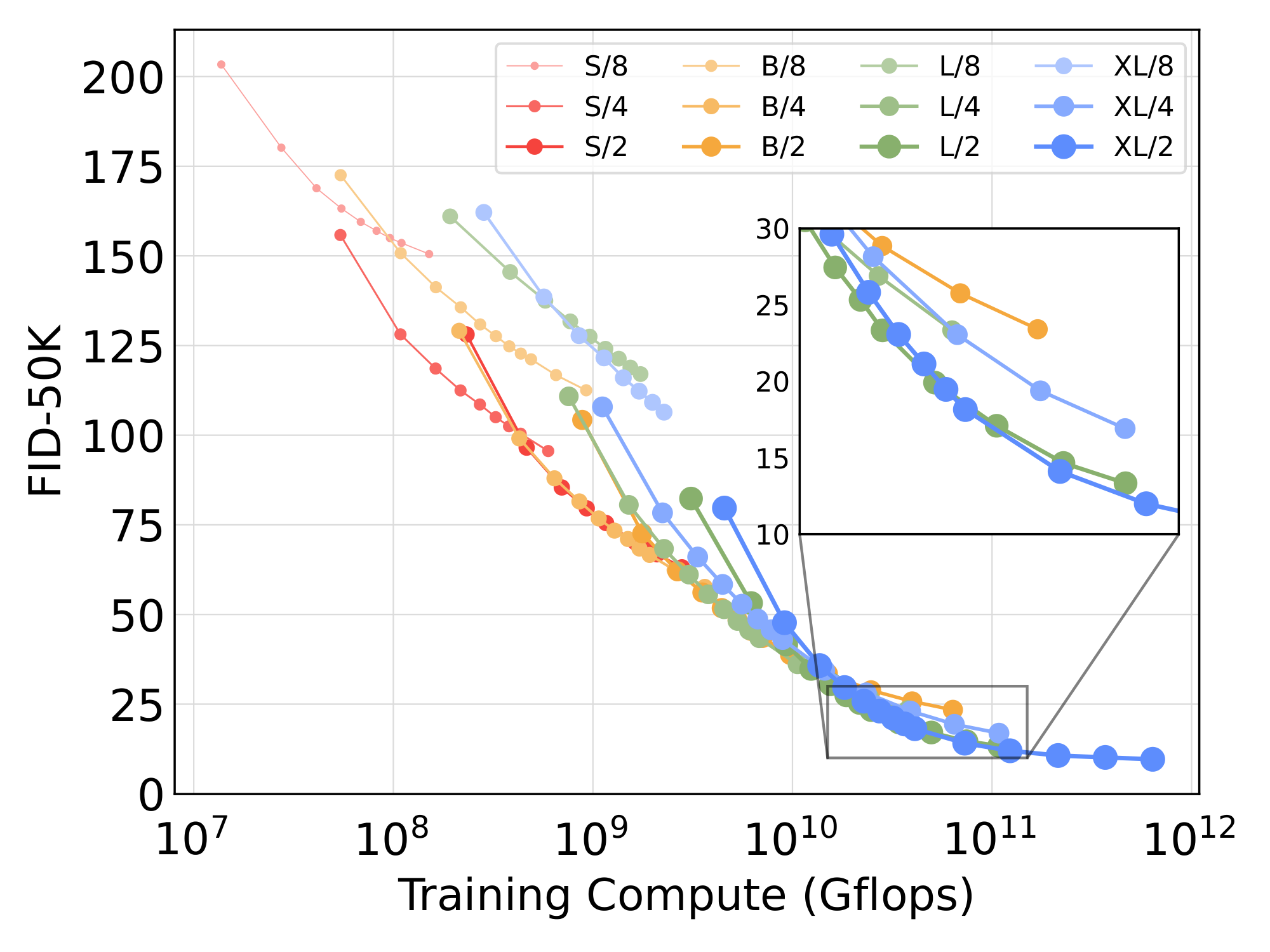
Larger DiT models are more compute-efficient. In Figure 9, we plot FID as a function of total training compute for all DiT models. We estimate training compute as model Gflops $\cdot$ batch size $\cdot$ training steps $\cdot$ 3, where the factor of 3 roughly approximates the backwards pass as being twice as compute-heavy as the forward pass. We find that small DiT models, even when trained longer, eventually become compute-inefficient relative to larger DiT models trained for fewer steps. Similarly, we find that models that are identical except for patch size have different performance profiles even when controlling for training Gflops. For example, XL/4 is outperformed by XL/2 after roughly $10^{10}$ Gflops.
Visualizing scaling.
We visualize the effect of scaling on sample quality in Figure 7. At 400K training steps, we sample an image from each of our 12 DiT models using identical starting noise $x_{t_\text{max}}$, sampling noise and class labels. This lets us visually interpret how scaling affects DiT sample quality. Indeed, scaling both model size and the number of tokens yields notable improvements in visual quality.
5.1 State-of-the-Art Diffusion Models
256 $\times$ 256 ImageNet.
Following our scaling analysis, we continue training our highest Gflop model, DiT-XL/2, for 7M steps. We show samples from the model in Figure 1, and we compare against state-of-the-art class-conditional generative models. We report results in Table 2. When using classifier-free guidance, DiT-XL/2 outperforms all prior diffusion models, decreasing the previous best FID-50K of 3.60 achieved by LDM to 2.27. Figure 2 (right) shows that DiT-XL/2 (118.6 Gflops) is compute-efficient relative to latent space U-Net models like LDM-4 (103.6 Gflops) and substantially more efficient than pixel space U-Net models such as ADM (1120 Gflops) or ADM-U (742 Gflops). Our method achieves the lowest FID of all prior generative models, including the previous state-of-the-art StyleGAN-XL [62]. Finally, we also observe that DiT-XL/2 achieves higher recall values at all tested classifier-free guidance scales compared to LDM-4 and LDM-8. When trained for only 2.35M steps (similar to ADM), XL/2 still outperforms all prior diffusion models with an FID of 2.55.
:::
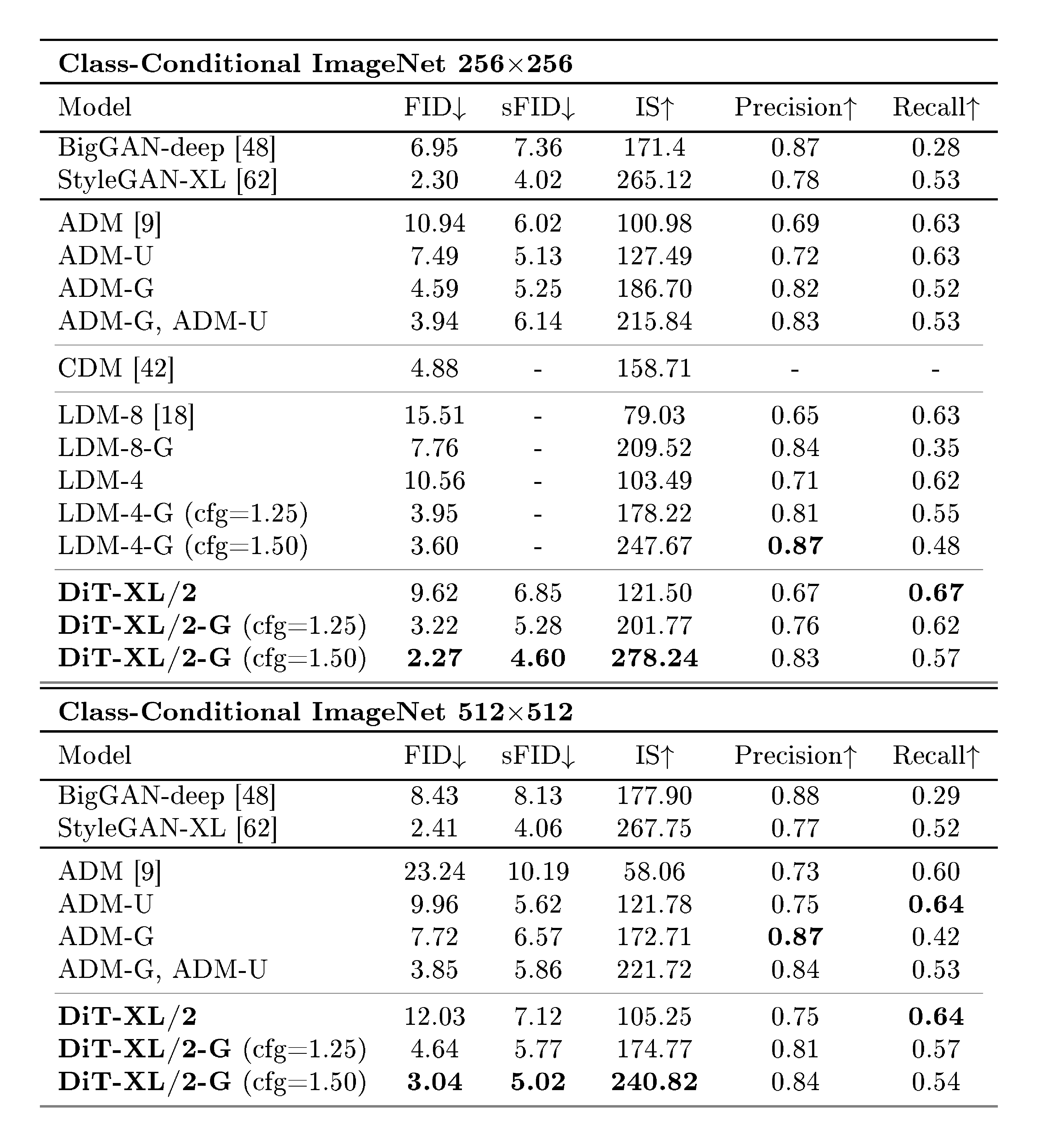
Table 2: Benchmarking class-conditional image generation on ImageNet 256 $\times$ 256. DiT-XL/2 achieves state-of-the-art FID.
:::
![**Figure 10:** **Scaling-up *sampling* compute does not compensate for a lack of *model* compute.** For each of our DiT models trained for 400K iterations, we compute FID-10K using [16, 32, 64, 128, 256, 1000] sampling steps. For each number of steps, we plot the FID as well as the Gflops used to sample each image. Small models cannot close the performance gap with our large models, even if they sample with more test-time Gflops than the large models.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/ftc7w8yw/sample_complexity_new.png)
512 $\times$ 512 ImageNet.
We train a new DiT-XL/2 model on ImageNet at $512\times512$ resolution for 3M iterations with identical hyperparameters as the $256\times256$ model. With a patch size of 2, this XL/2 model processes a total of 1024 tokens after patchifying the $64\times64\times4$ input latent (524.6 Gflops). Table 2 shows comparisons against state-of-the-art methods. XL/2 again outperforms all prior diffusion models at this resolution, improving the previous best FID of 3.85 achieved by ADM to 3.04. Even with the increased number of tokens, XL/2 remains compute-efficient. For example, ADM uses 1983 Gflops and ADM-U uses 2813 Gflops; XL/2 uses 524.6 Gflops. We show samples from the high-resolution XL/2 model in Figure 1 and the appendix.
5.2 Scaling Model vs. Sampling Compute
Diffusion models are unique in that they can use additional compute after training by increasing the number of sampling steps when generating an image. Given the impact of model Gflops on sample quality, in this section we study if smaller-model compute DiTs can outperform larger ones by using more sampling compute. We compute FID for all 12 of our DiT models after 400K training steps, using [16, 32, 64, 128, 256, 1000] sampling steps per-image. The main results are in Figure 10. Consider DiT-L/2 using 1000 sampling steps versus DiT-XL/2 using 128 steps. In this case, L/2 uses $80.7$ Tflops to sample each image; XL/2 uses $5\times$ less compute— $15.2$ Tflops—to sample each image. Nonetheless, XL/2 has the better FID-10K (23.7 vs 25.9). In general, scaling-up sampling compute cannot compensate for a lack of model compute.
6. Conclusion
Section Summary: The paper introduces Diffusion Transformers (DiTs), a straightforward transformer-based foundation for diffusion models that works better than earlier U-Net designs and benefits from the transformer's ability to improve with larger sizes. The encouraging results on scaling suggest researchers should build even bigger DiTs with more data points in upcoming studies. DiTs could also be easily integrated into text-to-image systems like DALL-E 2 or Stable Diffusion to enhance their performance.
We introduce Diffusion Transformers (DiTs), a simple transformer-based backbone for diffusion models that outperforms prior U-Net models and inherits the excellent scaling properties of the transformer model class. Given the promising scaling results in this paper, future work should continue to scale DiTs to larger models and token counts. DiT could also be explored as a drop-in backbone for text-to-image models like DALL $\cdot$ E 2 and Stable Diffusion.
Acknowledgements.
We thank Kaiming He, Ronghang Hu, Alexander Berg, Shoubhik Debnath, Tim Brooks, Ilija Radosavovic and Tete Xiao for helpful discussions. William Peebles is supported by the NSF GRFP.
Appendix
Section Summary: The appendix offers detailed technical information on DiT models, including a comprehensive table listing various model sizes, their computational requirements, training parameters like steps and learning rates, and performance scores measured without guidance. It explains implementation choices, such as how time steps are embedded in the models and a technique for applying guidance only to certain data channels to improve image generation quality. Figures throughout illustrate model samples, training loss trends, and how performance scales with increased computing power, while showcasing uncurated examples of generated images at 256x256 and 512x512 resolutions.

\begin{tabular}{l c c c c c c c c}
\toprule
Model & Image Resolution & Flops (G) & Params (M) & Training Steps (K) & Batch Size & Learning Rate & DiT Block & FID-50K (no guidance) \\
\midrule
DiT-S/8 & $256\times256$ & 0.36 & 33 & 400 & 256 & $1 \times 10^{-4}$ & adaLN-Zero & 153.60 \\
DiT-S/4 & $256\times256$ & 1.41 & 33 & 400 & 256 & $1 \times 10^{-4}$ & adaLN-Zero & 100.41 \\
DiT-S/2 & $256\times256$ & 6.06 & 33 & 400 & 256 & $1 \times 10^{-4}$ & adaLN-Zero & 68.40 \\
\midrule
DiT-B/8 & $256\times256$ & 1.42 & 131 & 400 & 256 & $1 \times 10^{-4}$ & adaLN-Zero & 122.74 \\
DiT-B/4 & $256\times256$ & 5.56 & 130 & 400 & 256 & $1 \times 10^{-4}$ & adaLN-Zero & 68.38 \\
DiT-B/2 & $256\times256$ & 23.01 & 130 & 400 & 256 & $1 \times 10^{-4}$ & adaLN-Zero & 43.47 \\
\midrule
DiT-L/8 & $256\times256$ & 5.01 & 459 & 400 & 256 & $1 \times 10^{-4}$ & adaLN-Zero & 118.87 \\
DiT-L/4 & $256\times256$ & 19.70 & 458 & 400 & 256 & $1 \times 10^{-4}$ & adaLN-Zero & 45.64 \\
DiT-L/2 & $256\times256$ & 80.71 & 458 & 400 & 256 & $1 \times 10^{-4}$ & adaLN-Zero & 23.33 \\
\midrule
DiT-XL/8 & $256\times256$ & 7.39 & 676 & 400 & 256 & $1 \times 10^{-4}$ & adaLN-Zero & 106.41 \\
DiT-XL/4 & $256\times256$ & 29.05 & 675 & 400 & 256 & $1 \times 10^{-4}$ & adaLN-Zero & 43.01 \\
DiT-XL/2 & $256\times256$ & 118.64 & 675 & 400 & 256 & $1 \times 10^{-4}$ & adaLN-Zero & 19.47 \\
DiT-XL/2 & $256\times256$ & 119.37 & 449 & 400 & 256 & $1 \times 10^{-4}$ & in-context & 35.24 \\
DiT-XL/2 & $256\times256$ & 137.62 & 598 & 400 & 256 & $1 \times 10^{-4}$ & cross-attention & 26.14 \\
DiT-XL/2 & $256\times256$ & 118.56 & 600 & 400 & 256 & $1 \times 10^{-4}$ & adaLN & 25.21 \\
DiT-XL/2 & $256\times256$ & 118.64 & 675 & 2352& 256 & $1 \times 10^{-4}$ & adaLN-Zero & 10.67 \\
DiT-XL/2 & $256\times256$ & 118.64 & 675 & 7000& 256 & $1 \times 10^{-4}$ & adaLN-Zero & 9.62 \\
\midrule
DiT-XL/2 & $512\times512$ & 524.60 & 675 & 1301& 256 & $1 \times 10^{-4}$ & adaLN-Zero & 13.78 \\
DiT-XL/2 & $512\times512$ & 524.60 & 675 & 3000& 256 & $1 \times 10^{-4}$ & adaLN-Zero & 11.93 \\
\bottomrule
\end{tabular}
A. Additional Implementation Details
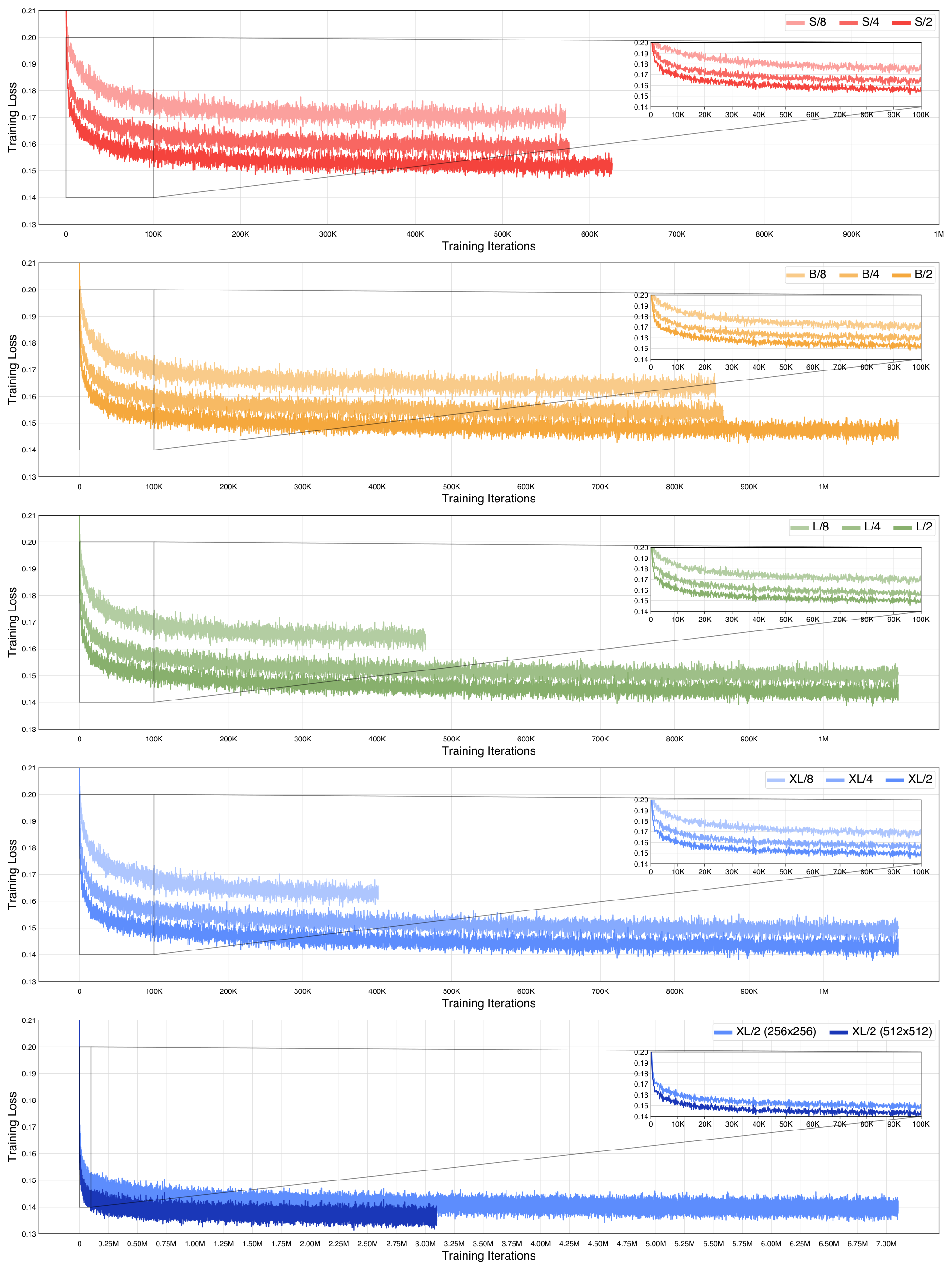
We include detailed information about all of our DiT models in Table 3, including both $256\times256$ and $512\times512$ models. In Figure 13, we report DiT training loss curves. Finally, we also include Gflop counts for DDPM U-Net models from ADM and LDM in Table 5.
DiT model details.
To embed input timesteps, we use a 256-dimensional frequency embedding [9] followed by a two-layer MLP with dimensionality equal to the transformer's hidden size and SiLU activations. Each adaLN layer feeds the sum of the timestep and class embeddings into a SiLU nonlinearity and a linear layer with output neurons equal to either $4\times$ (adaLN) or $6\times$ (adaLN-Zero) the transformer's hidden size. We use GELU nonlinearities (approximated with tanh) in the core transformer [63].
Classifier-free guidance on a subset of channels.
In our experiments using classifier-free guidance, we applied guidance only to the first three channels of the latents instead of all four channels. Upon investigating, we found that three-channel guidance and four-channel guidance give similar results (in terms of FID) when simply adjusting the scale factor. Specifically, three-channel guidance with a scale of $(1 + x)$ appears reasonably well-approximated by four-channel guidance with a scale of $(1 + \frac{3}{4}x)$ (e.g., three-channel guidance with a scale of $1.5$ gives an FID-50K of 2.27, and four-channel guidance with a scale of $1.375$ gives an FID-50K of 2.20). It is somewhat interesting that applying guidance to a subset of elements can still yield good performance, and we leave it to future work to explore this phenomenon further.
B. Model Samples
We show samples from our two DiT-XL/2 models at $512\times512$ and $256\times256$ resolution trained for 3M and 7M steps, respectively. Figure 1 and Figure 11 show selected samples from both models. Figure 14 through Figure 33 show uncurated samples from the two models across a range of classifier-free guidance scales and input class labels (generated with 250 DDPM sampling steps and the ft-EMA VAE decoder). As with prior work using guidance, we observe that larger scales increase visual fidelity and decrease sample diversity.
C. Additional Scaling Results
Impact of scaling on metrics beyond FID.
In Figure 12, we show the effects of DiT scale on a suite of evaluation metrics—FID, sFID, Inception Score, Precision and Recall. We find that our FID-driven analysis in the main paper generalizes to the other metrics—across every metric, scaled-up DiT models are more compute-efficient and model Gflops are highly-correlated with performance. In particular, Inception Score and Precision benefit heavily from increased model scale.
Impact of scaling on training loss.
We also examine the impact of scale on training loss in Figure 13. Increasing DiT model Gflops (via transformer size or number of input tokens) causes the training loss to decrease more rapidly and saturate at a lower value. This phenomenon is consistent with trends observed with language models, where scaled-up transformers demonstrate both improved loss curves as well as improved performance on downstream evaluation suites [22].
D. VAE Decoder Ablations
We used off-the-shelf, pre-trained VAEs across our experiments. The VAE models (ft-MSE and ft-EMA) are fine-tuned versions of the original LDM "f8" model (only the decoder weights are fine-tuned). We monitored metrics for our scaling analysis in Section 5 using the ft-MSE decoder, and we used the ft-EMA decoder for our final metrics reported in Table 2 and Table 2. In this section, we ablate three different choices of the VAE decoder; the original one used by LDM and the two fine-tuned decoders used by Stable Diffusion. Because the encoders are identical across models, the decoders can be swapped-in without retraining the diffusion model. Table 4 shows results; XL/2 continues to outperform all prior diffusion models when using the LDM decoder.
\begin{tabular}{lccccc}
\toprule
\multicolumn{6}{l}{\bf{Class-Conditional ImageNet} 256$\times$256, DiT-XL/2-G (cfg=1.5)} \\
\toprule
Decoder & FID$\downarrow$ & sFID$\downarrow$ & IS$\uparrow$ & Precision$\uparrow$ & Recall$\uparrow$ \\
\toprule
original & 2.46 & 5.18 & 271.56 & 0.82 & 0.57 \\
ft-MSE & 2.30 & 4.73 & 276.09 & 0.83 & 0.57 \\
ft-EMA & 2.27 & 4.60 & 278.24 & 0.83 & 0.57 \\
\bottomrule
\end{tabular}
\begin{tabular}{lccccc}
\toprule
\multicolumn{5}{l}{\textbf{Diffusion U-Net Model Complexities}} \\
\toprule
Model & Image Resolution & Base Flops (G) & Upsampler Flops (G) & Total Flops (G) \\
\toprule
ADM & $128\times128$ & 307 & - & 307 \\
ADM & $256\times256$ & 1120 & - & 1120 \\
ADM & $512\times512$ & 1983 & - & 1983 \\
ADM-U & $256\times256$ & 110 & 632 & 742 \\
ADM-U & $512\times512$ & 307 & 2506 & 2813 \\
\toprule
LDM-4 & $256\times256$ & 104 & - & 104 \\
LDM-8 & $256\times256$ & 57 & - & 57 \\
\bottomrule
\end{tabular}




















References
[1] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018.
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In NAACL-HCT, 2019.
[3] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2020.
[4] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017.
[5] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. 2019.
[6] Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. In NeurIPS, 2020.
[7] Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining from pixels. In ICML, 2020.
[8] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In ICML, 2021.
[9] Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. In NeurIPS, 2021.
[10] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv:2204.06125, 2022.
[11] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020.
[12] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134, 2017.
[13] Tim Salimans, Andrej Karpathy, Xi Chen, and Diederik P Kingma. PixelCNN++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications. arXiv preprint arXiv:1701.05517, 2017.
[14] Aaron Van den Oord, Nal Kalchbrenner, Lasse Espeholt, Oriol Vinyals, Alex Graves, et al. Conditional image generation with pixelcnn decoders. Advances in neural information processing systems, 29, 2016.
[15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
[16] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015.
[17] Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. In AAAI, 2018.
[18] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022.
[19] Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. In NeurIPS, 2021.
[20] Michael Janner, Qiyang Li, and Sergey Levine. Offline reinforcement learning as one big sequence modeling problem. In NeurIPS, 2021.
[21] William Peebles, Ilija Radosavovic, Tim Brooks, Alexei Efros, and Jitendra Malik. Learning to learn with generative models of neural network checkpoints. arXiv preprint arXiv:2209.12892, 2022.
[22] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv:2001.08361, 2020.
[23] Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Heewoo Jun, Tom B Brown, Prafulla Dhariwal, Scott Gray, et al. Scaling laws for autoregressive generative modeling. arXiv preprint arXiv:2010.14701, 2020.
[24] Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transformers. In CVPR, 2022.
[25] Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. Image transformer. In International conference on machine learning, pages 4055–4064. PMLR, 2018.
[26] Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019.
[27] Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. Advances in neural information processing systems, 30, 2017.
[28] Patrick Esser, Robin Rombach, and Björn Ommer. Taming transformers for high-resolution image synthesis, 2020.
[29] Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. In CVPR, pages 11315–11325, 2022.
[30] Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vector quantized diffusion model for text-to-image synthesis. In CVPR, pages 10696–10706, 2022.
[31] Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, et al. Scaling autoregressive models for content-rich text-to-image generation. arXiv:2206.10789, 2022.
[32] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021.
[33] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In ICML, 2015.
[34] Aapo Hyvärinen and Peter Dayan. Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research, 6(4), 2005.
[35] Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. In NeurIPS, 2019.
[36] Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv:2112.10741, 2021.
[37] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. arXiv:2205.11487, 2022.
[38] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In NIPS, 2014.
[39] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv:2010.02502, 2020.
[40] Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. In Proc. NeurIPS, 2022.
[41] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021.
[42] Jonathan Ho, Chitwan Saharia, William Chan, David J Fleet, Mohammad Norouzi, and Tim Salimans. Cascaded diffusion models for high fidelity image generation. arXiv:2106.15282, 2021.
[43] Allan Jabri, David Fleet, and Ting Chen. Scalable adaptive computation for iterative generation. arXiv preprint arXiv:2212.11972, 2022.
[44] Ilija Radosavovic, Justin Johnson, Saining Xie, Wan-Yen Lo, and Piotr Dollár. On network design spaces for visual recognition. In ICCV, 2019.
[45] Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, and Piotr Dollár. Designing network design spaces. In CVPR, 2020.
[46] Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In ICML, 2021.
[47] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
[48] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale GAN training for high fidelity natural image synthesis. In ICLR, 2019.
[49] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In CVPR, 2019.
[50] Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv:1706.02677, 2017.
[51] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In NeurIPS, 2012.
[52] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv:1711.05101, 2017.
[53] Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
[54] Andreas Steiner, Alexander Kolesnikov, Xiaohua Zhai, Ross Wightman, Jakob Uszkoreit, and Lucas Beyer. How to train your ViT? data, augmentation, and regularization in vision transformers. TMLR, 2022.
[55] Tete Xiao, Piotr Dollar, Mannat Singh, Eric Mintun, Trevor Darrell, and Ross Girshick. Early convolutions help transformers see better. In NeurIPS, 2021.
[56] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. 2017.
[57] Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. On aliased resizing and surprising subtleties in gan evaluation. In CVPR, 2022.
[58] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, Xi Chen, and Xi Chen. Improved techniques for training GANs. In NeurIPS, 2016.
[59] Charlie Nash, Jacob Menick, Sander Dieleman, and Peter W Battaglia. Generating images with sparse representations. arXiv preprint arXiv:2103.03841, 2021.
[60] Tuomas Kynkäänniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Improved precision and recall metric for assessing generative models. In NeurIPS, 2019.
[61] James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018.
[62] Axel Sauer, Katja Schwarz, and Andreas Geiger. Stylegan-xl: Scaling stylegan to large diverse datasets. In SIGGRAPH, 2022.
[63] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.