LIMA: Less Is More for Alignment
Chunting Zhou Pengfei Liu$^{\pi*}$ Puxin Xu$^{\mu}$ Srini Iyer$^{\mu}$ Jiao Sun$^{\lambda,\mu*}$
Yuning Mao Xuezhe Ma$^{\lambda}$ Avia Efrat$^{\tau}$ Ping Yu Lili Yu Susan Zhang$^{\mu}$
Gargi Ghosh Mike Lewis Luke Zettlemoyer Omer Levy$^{\mu}$
$^{\mu}$ Meta AI
$^{\pi}$ Carnegie Mellon University
$^{\lambda}$ University of Southern California
$^{\tau}$ Tel Aviv University
Abstract
Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We measure the relative importance of these two stages by training LIMA, a 65B parameter LLaMa language model fine-tuned with the standard supervised loss on only 1, 000 carefully curated prompts and responses, without any reinforcement learning or human preference modeling. LIMA demonstrates remarkably strong performance, learning to follow specific response formats from only a handful of examples in the training data, including complex queries that range from planning trip itineraries to speculating about alternate history. Moreover, the model tends to generalize well to unseen tasks that did not appear in the training data. In a controlled human study, responses from LIMA are either equivalent or strictly preferred to GPT-4 in 43% of cases; this statistic is as high as 58% when compared to Bard and 65% versus DaVinci003, which was trained with human feedback. Taken together, these results strongly suggest that almost all knowledge in large language models is learned during pretraining, and only limited instruction tuning data is necessary to teach models to produce high quality output.
Executive Summary: Large language models, the powerful AI systems behind tools like chatbots and text generators, have transformed how we interact with technology, from drafting emails to answering complex questions. However, aligning these models to produce helpful, user-friendly responses typically demands vast amounts of training data—often millions of examples—and intensive methods like reinforcement learning from human feedback. This process is computationally expensive and time-consuming, limiting access for smaller teams or organizations. With the rapid growth of AI applications, there is urgent need to find more efficient ways to "align" models, making high-quality AI safer, more accessible, and less resource-intensive without sacrificing performance.
This document tests whether a strong pretrained language model can achieve effective alignment through simple, limited fine-tuning, rather than massive datasets or advanced techniques. Specifically, it evaluates if just 1,000 carefully selected examples of user prompts and assistant responses suffice to teach a model to generate useful outputs across diverse tasks.
The researchers created LIMA, a 65-billion-parameter model based on the pretrained LLaMa architecture, by fine-tuning it solely on these 1,000 examples using standard supervised learning—no reinforcement learning or human preference data was involved. They curated the training set from diverse sources: 750 high-quality question-answer pairs from online communities like Stack Exchange (for topics in science, tech, and daily life), wikiHow (for how-to guides), and Reddit (for creative prompts), selected for clarity and helpfulness; plus 250 manually written examples to broaden task variety, such as planning trips or offering advice, all styled as responses from a supportive AI assistant. A separate test set of 300 challenging prompts covered unseen scenarios, including multi-turn conversations and safety tests. Performance was assessed through a controlled human study where annotators compared LIMA's responses to those from leading models like GPT-4, Bard, and others, plus automated scoring and targeted experiments on data factors like diversity.
The key findings highlight LIMA's surprising effectiveness. First, in head-to-head human evaluations, LIMA produced responses equal to or preferred over GPT-4 in 43% of cases, Bard in 58%, and the RLHF-trained DaVinci003 in 65%; it even outperformed a similar model (Alpaca) trained on 52,000 examples. Second, on an absolute scale, 88% of LIMA's outputs met prompt requirements, with 50% rated excellent for clarity and relevance, including on out-of-distribution tasks like generating recipes or speculating on history. Third, ablation tests on a smaller model version showed that prompt diversity (e.g., mixing topics) and response quality boosted performance by about 0.5 points on a 6-point scale, while doubling data quantity alone yielded no gains. Fourth, despite zero dialogue training, LIMA handled multi-turn chats coherently in 85% of turns, improving to 98% excellent responses after adding just 30 dialogue examples. Finally, safety held up reasonably, with safe refusals in 80% of sensitive prompts, though implicit harms sometimes slipped through.
These results imply that pretraining already embeds most of a model's knowledge and reasoning, so alignment mainly involves teaching output style and format—challenging the assumption that bigger datasets or complex methods like RLHF are essential for top performance. This could slash training costs by orders of magnitude (from millions to thousands of examples), speed up development, and reduce risks from over-reliance on human-labeled data, which can introduce biases. Unlike prior work emphasizing scale, LIMA's success with minimal, high-quality input suggests untapped efficiency in current AI pipelines, potentially accelerating safer deployment in areas like education or customer service while easing environmental impacts from compute-heavy training.
Based on these insights, organizations should shift toward curating diverse, high-quality instruction data rather than chasing quantity, starting with small sets of 1,000–2,000 examples tailored to core use cases. For immediate next steps, integrate minimal fine-tuning into existing pretrained models for quick prototyping, and conduct pilots to test generalization in specific domains like healthcare queries. If pursuing production, add 50–100 targeted examples for gaps like enhanced safety or dialogue to boost robustness. Broader options include automating curation via distillation from larger models (with quality checks) versus full manual effort— the former trades some precision for scale but risks propagating errors. Further work is needed, such as larger-scale validations on real user interactions and adversarial testing, before fully replacing resource-intensive alignment.
While the human preference studies and ablations provide strong evidence, limitations include the labor-intensive manual curation, which resists easy scaling, and LIMA's occasional brittleness to tricky prompts or random generation variations. Confidence is high in the core claim for standard tasks, given consistent results across human and AI evaluators, but readers should be cautious about edge cases like high-stakes safety, where more data would strengthen reliability.
1. Introduction
Section Summary: Language models are trained on vast amounts of data to predict words, building broad knowledge that can apply to many tasks, but aligning them to respond helpfully like chatbots usually requires huge datasets and heavy computing power. This paper shows that fine-tuning a powerful 65-billion-parameter model called LIMA on just 1,000 carefully selected examples—mostly real questions and answers from online forums plus some handcrafted ones—can produce surprisingly strong results by teaching the model a simple, user-friendly response style. In tests, LIMA often matched or beat advanced models in human judgments, handling diverse prompts well and even managing conversations, highlighting how pretraining's foundational knowledge matters more than massive extra training.
Language models are pretrained to predict the next token at an incredible scale, allowing them to learn general-purpose representations that can be transferred to nearly any language understanding or generation task. To enable this transfer, various methods for aligning language models have thus been proposed, primarily focusing on instruction tuning ([1, 2, 3]) over large multi-million-example datasets ([4, 5, 6]), and more recently reinforcement learning from human feedback (RLHF) ([7, 8]), collected over millions of interactions with human annotators. Existing alignment methods require significant amounts of compute and specialized data to achieve ChatGPT-level performance. However, we demonstrate that, given a strong pretrained language model, remarkably strong performance can be achieved by simply fine-tuning on 1, 000 carefully curated training examples.
We hypothesize that alignment can be a simple process where the model learns the style or format for interacting with users, to expose the knowledge and capabilities that were already acquired during pretraining. To test this hypothesis, we curate 1, 000 examples that approximate real user prompts and high-quality responses. We select 750 top questions and answers from community forums, such as Stack Exchange and wikiHow, sampling for quality and diversity. In addition, we manually write 250 examples of prompts and responses, while optimizing for task diversity and emphasizing a uniform response style in the spirit of an AI assistant. Finally, we train LIMA, a pretrained 65B-parameter LLaMa model ([9]) fine-tuned on this set of 1, 000 demonstrations.
We compare LIMA to state-of-the-art language models and products across 300 challenging test prompts. In a human preference study, we find that LIMA outperforms RLHF-trained DaVinci003 from OpenAI, which was trained with RLHF, as well as a 65B-parameter reproduction of Alpaca ([10]), which was trained on 52, 000 examples. While humans typically prefer responses from GPT-4, Claude, and Bard over LIMA, this is not always the case; LIMA produces equal or preferrable responses in 43%, 46%, and 58% of the cases, respectively. Repeating the human preference annotations with GPT-4 as the annotator corroborates our findings. Analyzing LIMA responses on an absolute scale reveals that 88% meet the prompt requirements, and 50% are considered excellent.
Ablation experiments reveal vastly diminishing returns when scaling up data quantity without also scaling up prompt diversity, alongside major gains when optimizing data quality. In addition, despite having zero dialogue examples, we find that LIMA can conduct coherent multi-turn dialogue, and that this ability can be dramatically improved by adding only 30 hand-crafted dialogue chains to the training set. Overall, these remarkable findings demonstrate the power of pretraining and its relative importance over large-scale instruction tuning and reinforcement learning approaches.
2. Alignment Data
Section Summary: Researchers propose the Superficial Alignment Hypothesis, which suggests that AI models gain most of their knowledge during initial training, while later alignment mainly teaches them to respond in a helpful, user-friendly style rather than adding new facts. To test this, they gathered a dataset of 1,000 diverse prompts paired with responses mimicking a helpful AI assistant, drawn from online sources like Stack Exchange, wikiHow, and Reddit, plus some manually created examples. They also created separate test and development sets of 300 and 50 prompts, respectively, after filtering for quality, length, and neutral tone to ensure the data suits AI tuning.
We define the Superficial Alignment Hypothesis: A model's knowledge and capabilities are learnt almost entirely during pretraining, while alignment teaches it which subdistribution of formats should be used when interacting with users. If this hypothesis is correct, and alignment is largely about learning style, then a corollary of the Superficial Alignment Hypothesis is that one could sufficiently tune a pretrained language model with a rather small set of examples ([11]).
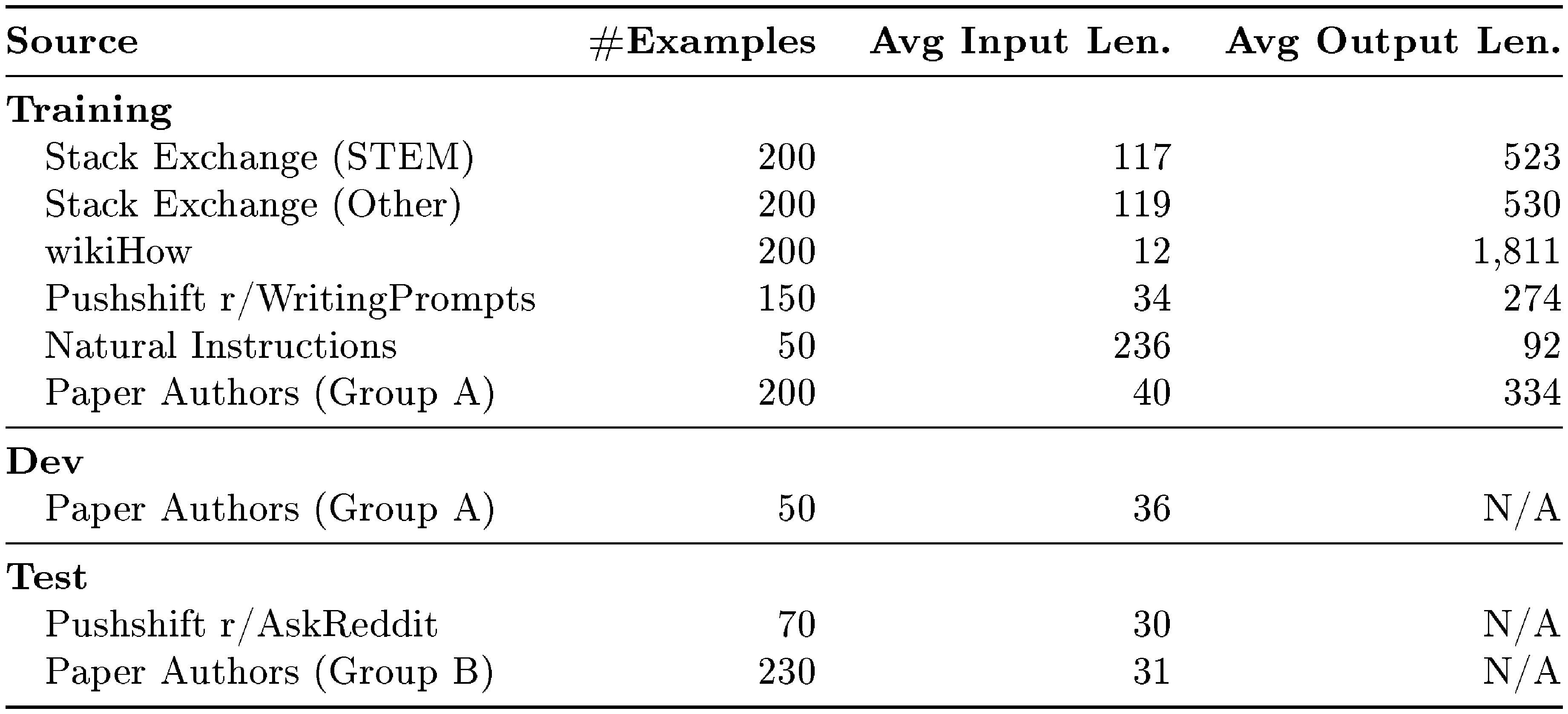
To that end, we collect a dataset of 1, 000 prompts and responses, where the outputs (responses) are stylistically aligned with each other, but the inputs (prompts) are diverse. Specifically, we seek outputs in the style of a helpful AI assistant. We curate such examples from a variety of sources, primarily split into community Q&A forums and manually authored examples. We also collect a test set of 300 prompts and a development set of 50. Table 1 shows an overview of the different data sources and provides some statistics (see Figure 10 for a selection of training examples).
::: {caption="Table 1: Sources of training prompts (inputs) and responses (outputs), and test prompts. The total amount of training data is roughly 750, 000 tokens, split over exactly 1, 000 sequences."}
:::
2.1 Community Questions & Answers
We collect data from three community Q&A websites: Stack Exchange, wikiHow, and the Pushshift Reddit Dataset ([12]). Largely speaking, answers from Stack Exchange and wikiHow are well-aligned with the behavior of a helpful AI agent, and can therefore be mined automatically, whereas highly upvoted Reddit answers tend to be humorous or trolling, requiring a more manual approach to curate responses that follow the appropriate style.
Stack Exchange
Stack Exchange contains 179 online communities (exchanges), each one dedicated to a specific topic, with the most popular one being programming (Stack Overflow). Users can post questions, answers, comments and upvote (or downvote) all of the above. Thanks to active community members and moderators, Stack Exchange has successfully maintained a high bar for content quality.
We apply both quality and diversity controls when sampling from Stack Exchange. First, we divide the exchanges into 75 STEM exchanges (including programming, math, physics, etc.) and 99 other (English, cooking, travel, and more); we discard 5 niche exchanges. We then sample 200 questions and answers from each set using a temperature of $\tau = 3$ to get a more uniform sample of the different domains. Within each exchange, we take the questions with the highest score that are self-contained in the title (no body). We then select the top answer for each question, assuming it had a strong positive score (at least 10). To conform with the style of a helpful AI assistant, we automatically filter answers that are too short (less than 1200 characters), too long (more than 4096 characters), written in the first person ("I", "my"), or reference other answers ("as mentioned", "stack exchange", etc); we also remove links, images, and other HTML tags from the response, retaining only code blocks and lists. Since Stack Exchange questions contain both a title and a description, we randomly select the title as the prompt for some examples, and the description for others.
wikiHow
wikiHow is an online wiki-style publication featuring over 240, 000 how-to articles on a variety of topics. Anyone can contribute to wikiHow, though articles are heavily moderated, resulting in almost universally high-quality content. We sample 200 articles from wikiHow, sampling a category first (out of 19) and then an article within it to ensure diversity. We use the title as the prompt (e.g. "How to cook an omelette?") and the article's body as the response. We replace the typical "This article..." beginning with "The following answer...", and apply a number of preprocessing heuristics to prune links, images, and certain sections of the text.
The Pushshift Reddit Dataset
Reddit is one of the most popular websites in the world, allowing users to share, discuss, and upvote content in user-created subreddits. Due to its immense popularity, Reddit is geared more towards entertaining fellow users rather than helping; it is quite often the case that witty, sarcastic comments will obtain more votes than serious, informative comments to a post. We thus restrict our sample to two subsets, r/AskReddit and r/WritingPrompts, and manually select examples from within the most upvoted posts in each community. From r/AskReddit we find 70 self-contained prompts (title only, no body), which we use for the test set, since the top answers are not necessarily reliable. The WritingPrompts subreddit contains premises of fictional stories, which other users are then encouraged to creatively complete. We find 150 prompts and high-quality responses, encompassing topics such as love poems and short science fiction stories, which we add to the training set. All data instances were mined from the Pushshift Reddit Dataset ([12]).
2.2 Manually Authored Examples
To further diversify our data beyond questions asked by users in online communities, we collect prompts from ourselves (the authors of this work). We designate two sets of authors, Group A and Group B, to create 250 prompts each, inspired by their own interests or those of their friends.[^1] We select 200 prompts from Group A for training and 50 prompts as a held-out development set. After filtering some problematic prompts, the remaining 230 prompts from Group B are used for test.
[^1]: Despite our efforts to prevent leakage, there was significant contact between the groups before the annotation process, which resulted in certain shared priors that can be observed in the data.
We supplement the 200 training prompts with high-quality answers, which we write ourselves. While authoring answers, we try to set a uniform tone that is appropriate for a helpful AI assistant. Specifically, many prompts will be answered with some acknowledgment of the question followed by the answer itself. Preliminary experiments show that this consistent format generally improves model performance; we hypothesize that it assists the model in forming a chain of thought, similar to the "let's think step-by-step" prompt ([13, 14]).
We also include 13 training prompts with some degree of toxicity or malevolence. We carefully write responses that partially or fully reject the command, and explain why the assistant will not comply. There are also 30 prompts with similar issues in the test set, which we analyze in Figure 3.
In addition to our manually authored examples, we sample 50 training examples from Super-Natural Instructions ([15]). Specifically, we select 50 natural language generation tasks such as summarization, paraphrasing, and style transfer, and pick a single random example from each one. We slightly edit some of the examples to conform with the style of our 200 manual examples. While the distribution of potential user prompts is arguably different from the distribution of tasks in Super-Natural Instructions, our intuition is that this small sample adds diversity to the overall mix of training examples, and can potentially increase model robustness.
Manually creating diverse prompts and authoring rich responses in a uniform style is laborious. While some recent works avoid manual labor via distillation and other automatic means ([16, 17, 10, 18, 19]), optimizing for quantity over quality, this work explores the effects of investing in diversity and quality instead.
3. Training LIMA
Section Summary: Researchers trained the LIMA model, which stands for "Less Is More for Alignment," by fine-tuning a large language model called LLaMa 65B on a small set of just 1,000 examples designed to improve helpful and harmless responses. To clearly separate user and assistant turns in conversations, they added a special token at the end of each message, similar to a stop signal but distinct from the model's existing one. The training used standard techniques over 15 rounds, with adjustments like gradually increasing dropout rates in the model's layers and manually picking the best version based on performance tests rather than automated metrics.
We train LIMA (Less Is More for Alignment) using the following protocol. Starting from LLaMa 65B ([9]), we fine-tune on our 1, 000-example alignment training set. To differentiate between each speaker (user and assistant), we introduce a special end-of-turn token (EOT) at the end of each utterance; this token plays the same role as EOS of halting generation, but avoids conflation with any other meaning that the pretrained model may have imbued into the preexisting EOS token.
We follow standard fine-tuning hyperparameters: we fine-tune for 15 epochs using AdamW ([20]) with $\beta_1=0.9, \beta_2=0.95$, and weight decay of $0.1$. Without warmup steps, we set the initial learning rate to $1e-5$ and linearly decaying to $1e-6$ by the end of training. The batch size is set to 32 examples (64 for smaller models), and texts longer than 2048 tokens are trimmed. One notable deviation from the norm is the use of residual dropout; we follow [8] and apply dropout over residual connections, starting at $p_d = 0.0$ at the bottom layer and linearly raising the rate to $p_d = 0.3$ at the last layer ($p_d = 0.2$ for smaller models). We find that perplexity does not correlate with generation quality, and thus manually select checkpoints between the 5th and the 10th epochs using the held-out 50-example development set.[^2]
[^2]: See Figure 9 for a more detailed study comparing validation perplexity and generation quality.
4. Human Evaluation
Section Summary: Researchers evaluated the LIMA language model by having people and GPT-4 compare its responses to those from top models like Alpaca, DaVinci003, Bard, Claude, and GPT-4 on 300 test prompts. LIMA outperformed Alpaca and DaVinci003, matched or exceeded Bard in over half the cases, and even beat Claude and GPT-4 occasionally, despite being trained on far less data. A closer look at 50 random examples showed that half of LIMA's answers were excellent and it followed instructions correctly in most cases, reinforcing the idea that strong pretraining makes extra tuning less necessary.
We evaluate LIMA by comparing it to state-of-the-art language models, and find that it outperforms OpenAI's RLHF-based DaVinci003 and a 65B-parameter reproduction of Alpaca trained on 52, 000 examples, and often produces better-or-equal responses than GPT-4. Analyzing of LIMA generations finds that 50% of its outputs are considered excellent. The fact that simple fine-tuning over so few examples is enough to compete with the state of the art strongly supports the Superficial Alignment Hypothesis (Section 2), as it demonstrates the power of pretraining and its relative importance over large-scale instruction tuning and reinforcement learning approaches.
4.1 Experiment Setup
To compare LIMA to other models, we generate a single response for each test prompt. We then ask crowd workers to compare LIMA outputs to each of the baselines and label which one they prefer. We repeat this experiment, replacing human crowd workers with GPT-4, finding similar agreement levels.
Baselines
We compare LIMA to five baselines: Alpaca 65B ([10]) – we finetune LLaMa 65B ([9]) on the 52, 000 examples in the Alpaca training set ([10]); OpenAI's DaVinci003, ^3 a large language model tuned with reinforcement learning from human feedback (RLHF) ([8]); Google's Bard, based on PaLM ([21]); Anthropic's Claude, ^4 a 52B parameter model trained with reinforcement learning from AI feedback (Constitutional AI) [22], OpenAI's GPT-4 ([23]), a large language model trained with RLHF, which is currently considered the state of the art. Responses from all baselines were sampled throughout April 2023.
Generation
For each prompt, we generate a single response from each baseline model using nucleus sampling ([24]) with $p=0.9$ and a temperature of $\tau=0.7$. We apply a repetition penalty of previously generated tokens with a hyperparameter of 1.2 ([25]). We limit the maximum token length to 2048.
Methodology
At each step, we present annotators with a single prompt and two possible responses, generated by different models. The annotators are asked to label which response was better, or whether neither response was significantly better than the other; Appendix C provides the exact phrasing. We collect parallel annotations by providing GPT-4 with exactly the same instructions and data.
Inter-Annotator Agreement
We compute inter-annotator agreement using tie-discounted accuracy: we assign one point if both annotators agreed, half a point if either annotator (but not both) labeled a tie, and zero points otherwise. We measure agreement over a shared set of 50 annotation examples (single prompt, two model responses – all chosen randomly), comparing author, crowd, and GPT-4 annotations. Among human annotators, we find the following agreement scores: crowd-crowd 82%, crowd-author 81%, and author-author 78%. Despite some degree of subjectivity in this task, there is decent agreement among human annotators.
We also measure the agreement between GPT-4 and humans: crowd-GPT 78% and author-GPT 79% (although we use stochastic decoding, GPT-4 almost always agrees with itself). These figures place GPT-4 on-par in agreement with human annotators, essentially passing the Turking Test for this task ([26]).
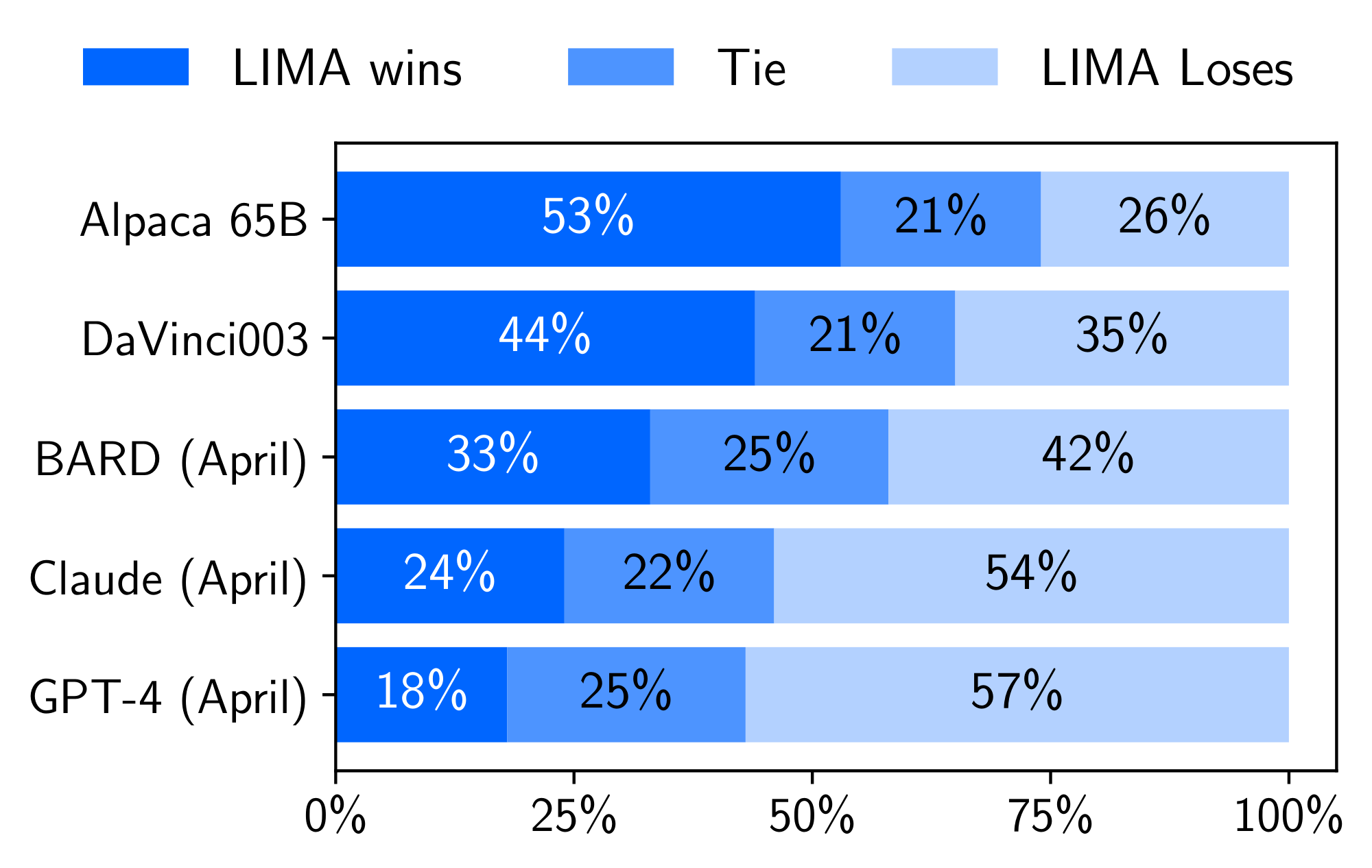
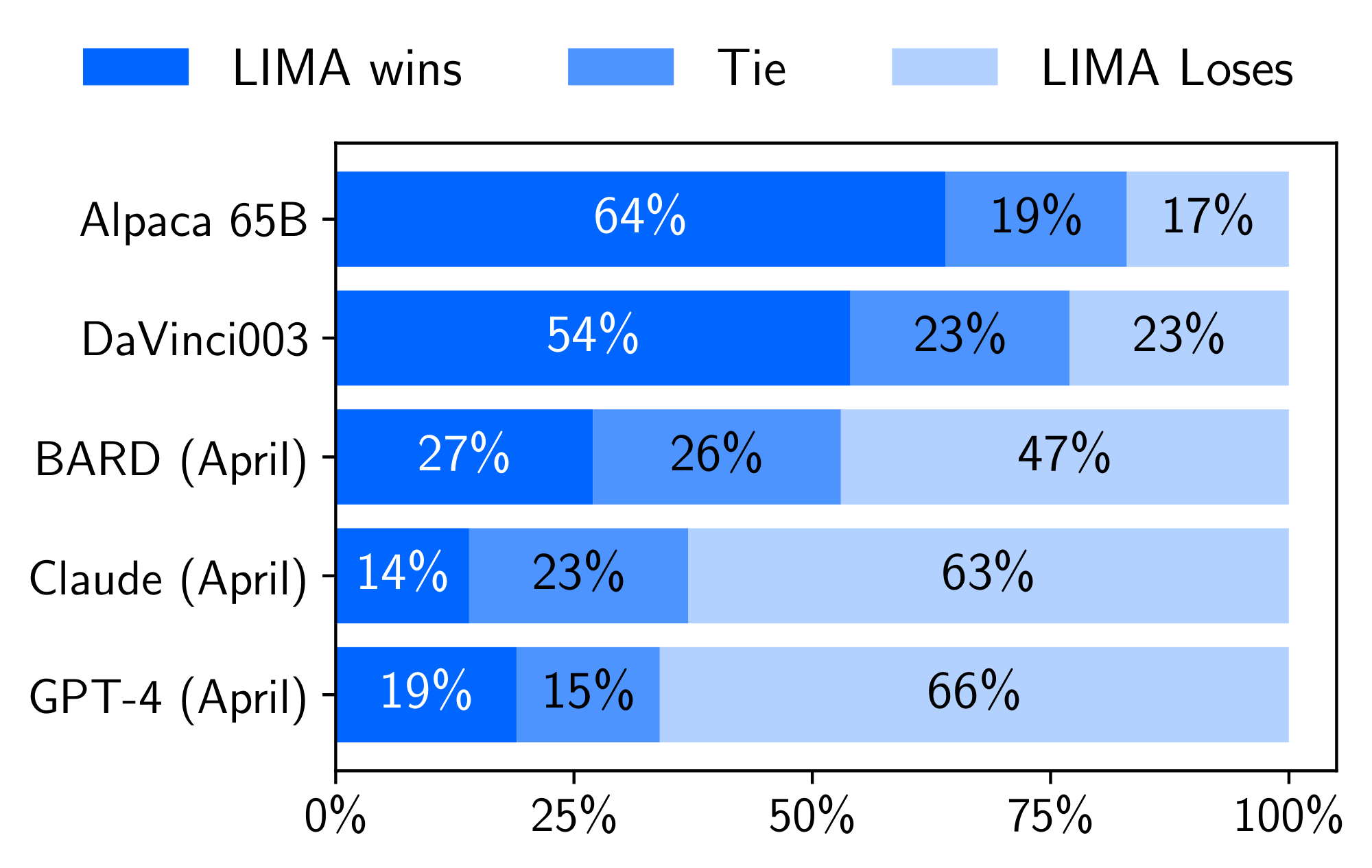
4.2 Results
Figure 1 shows the results of our human preference study, while Figure 2 displays the results of GPT-4 preferences. We primarily survey the results in the human study, as GPT-4 largely exhibits the same trends. Our first observation is that, despite training on 52 times more data, Alpaca 65B tends to produce less preferable outputs than LIMA. The same is true for DaVinci003, though to a lesser extent; what is striking about this result is the fact that DaVinci003 was trained with RLHF, a supposedly superior alignment method. Bard shows the opposite trend to DaVinci003, producing better responses than LIMA 42% of the time; however, this also means that 58% of the time the LIMA response was at least as good as Bard. Finally, we see that while Claude and GPT-4 generally perform better than LIMA, there is a non-trivial amount of cases where LIMA does actually produce better responses. Perhaps ironically, even GPT-4 prefers LIMA outputs over its own 19% of the time.
4.3 Analysis
While our main evaluation assesses LIMA with respect to state-of-the-art models, one must remember that some of these baselines are actually highly-tuned products that may have been exposed to millions of real user prompts during training, creating a very high bar. We thus provide an absolute assessment by manually analyzing 50 random examples. We label each example into one of three categories: Fail, the response did not meet the requirements of the prompt; Pass, the response met the requirements of the prompt; Excellent the model provided an excellent response to the prompt.
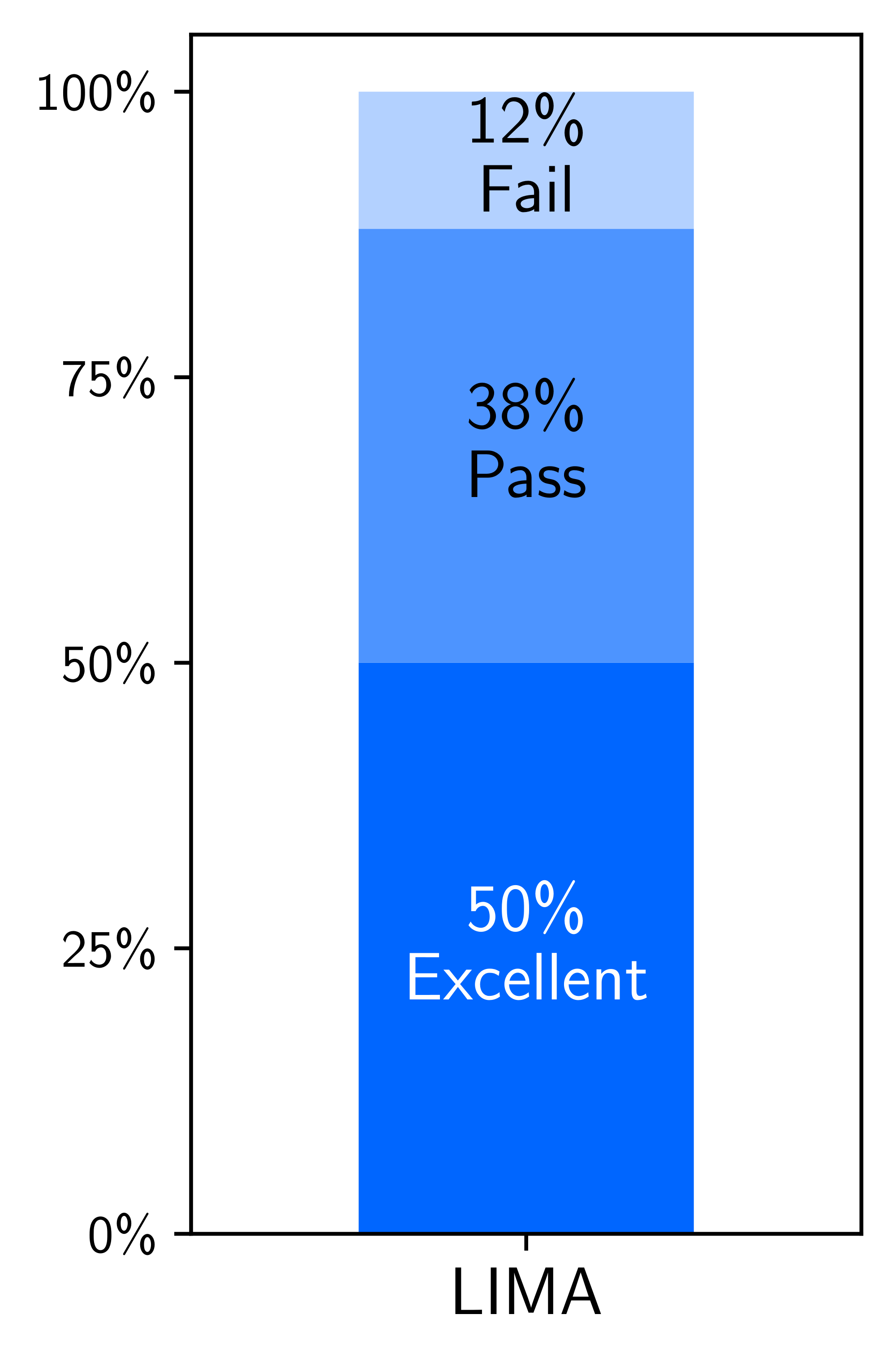
Results
Figure 3 shows that 50% of LIMA answers are considered excellent, and that it is able to follow all but 6 of the 50 analyzed prompts. We do not observe any notable trend within the failure cases. Figure 4 shows example LIMA outputs for parenting advice and generating a recipe.
Out of Distribution
How does LIMA perform on examples Of the 50 analyzed examples, 43 have a training example that is somewhat related in terms of format (e.g. question answering, advice, letter writing, etc). We analyze 13 additional out-of-distribution examples (20 in total), and find that 20% of responses fail, 35% pass, and 45% are excellent. Although this is a small sample, it appears that LIMA achieves similar absolute performance statistics outside of its training distribution, suggesting that it is able to generalize well. Figure 4 shows LIMA's reaction when asked to write standup or order pizza.
Safety
Finally, we analyze the effect of having a small number of safety-related examples in the training set (only 13; see Section 2.2). We check LIMA's response to 30 potentially sensitive prompts from the test set, and find that LIMA responds safely to 80% of them (including 6 out of 10 prompts with malicious intent). In some cases, LIMA outright refuses to perform the task (e.g. when asked to provide a celebrity's address), but when the malicious intent is implicit, LIMA is more likely to provide unsafe responses, as can be seen in Figure 4.
![**Figure 4:** **Model outputs from test prompts.** *Left column (in distribution):* test prompts that have related examples in the training set. *Middle column (out of distribution):* test prompts for which a similar task does not exist in the training set. *Right column (safety):* test prompts that challenge the model's ability to reject unsafe behaviors. The <span style="color:#3078BE">blue</span> text is the prompt. The gray ellipsis <span style="color:#808080">[...]</span> indicates that the response was trimmed to fit this page, but the generated text is actually longer.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/2w4n8dks/complex_fig_0b7a0665cbcb.png)
5. Why is Less More? Ablations on Data Diversity, Quality, and Quantity
Section Summary: Researchers tested how different aspects of training data affect the performance of a language model in generating helpful responses, using controlled experiments on a 7-billion-parameter AI model. They found that using diverse prompts, like varied questions from Stack Exchange, led to better results than sticking to uniform "how-to" instructions from wikiHow, and high-quality filtered responses outperformed unfiltered ones by a noticeable margin. Surprisingly, even multiplying the amount of data by up to 16 times did not improve outcomes, suggesting that for aligning AI with helpfulness, diversity and quality matter more than sheer volume.
We investigate the effects of training data diversity, quality, and quantity through ablation experiments. We observe that, for the purpose of alignment, scaling up input diversity and output quality have measurable positive effects, while scaling up quantity alone might not.
Experiment Setup
We fine-tune a 7B parameter LLaMa model [9] on various datasets, controlling for the same hyperparameters (Section 3).[^5] We then sample 5 responses for each test set prompt, and evaluate response quality by asking ChatGPT (GPT-3.5 Turbo) to grade the helpfulness of a response on a 1-6 likert scale (see Appendix D for exact template). We report the average score alongside a $p=0.95$ two-sided confidence interval.
[^5]: While preliminary experiments show that it is possible to tune the 7B model with only 1, 000 examples, we also found that using at least 2, 000 examples improved stability in this setting.
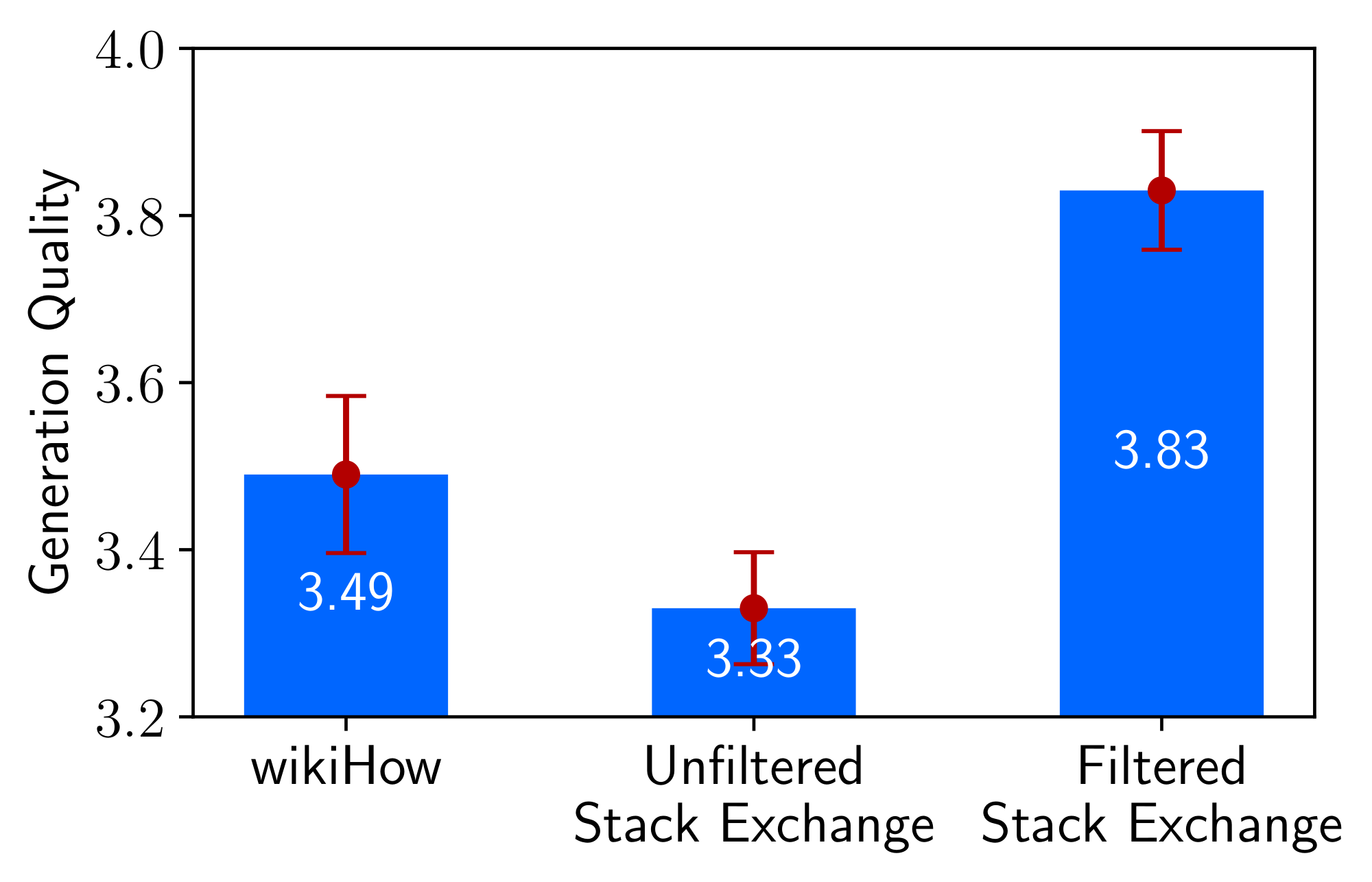
Diversity
To test the effects of prompt diversity, while controlling for quality and quantity, we compare the effect of training on quality-filtered Stack Exchange data, which has heterogeneous prompts with excellent responses, and wikiHow data, which has homogeneous prompts with excellent responses. While we compare Stack Exchange with wikiHow as a proxy for diversity, we acknowledge that there may be other conflating factors when sampling data from two different sources. We sample 2, 000 training examples from each source (following the same protocol from Section 2.1). Figure 5 shows that the more diverse Stack Exchange data yields significantly higher performance.
Quality
To test the effects of response quality, we sample 2, 000 examples from Stack Exchange without any quality or stylistic filters, and compare a model trained on this dataset to the one trained on our filtered dataset. Figure 5 shows that there is a significant 0.5 point difference between models trained on the filtered and unfiltered data sources.
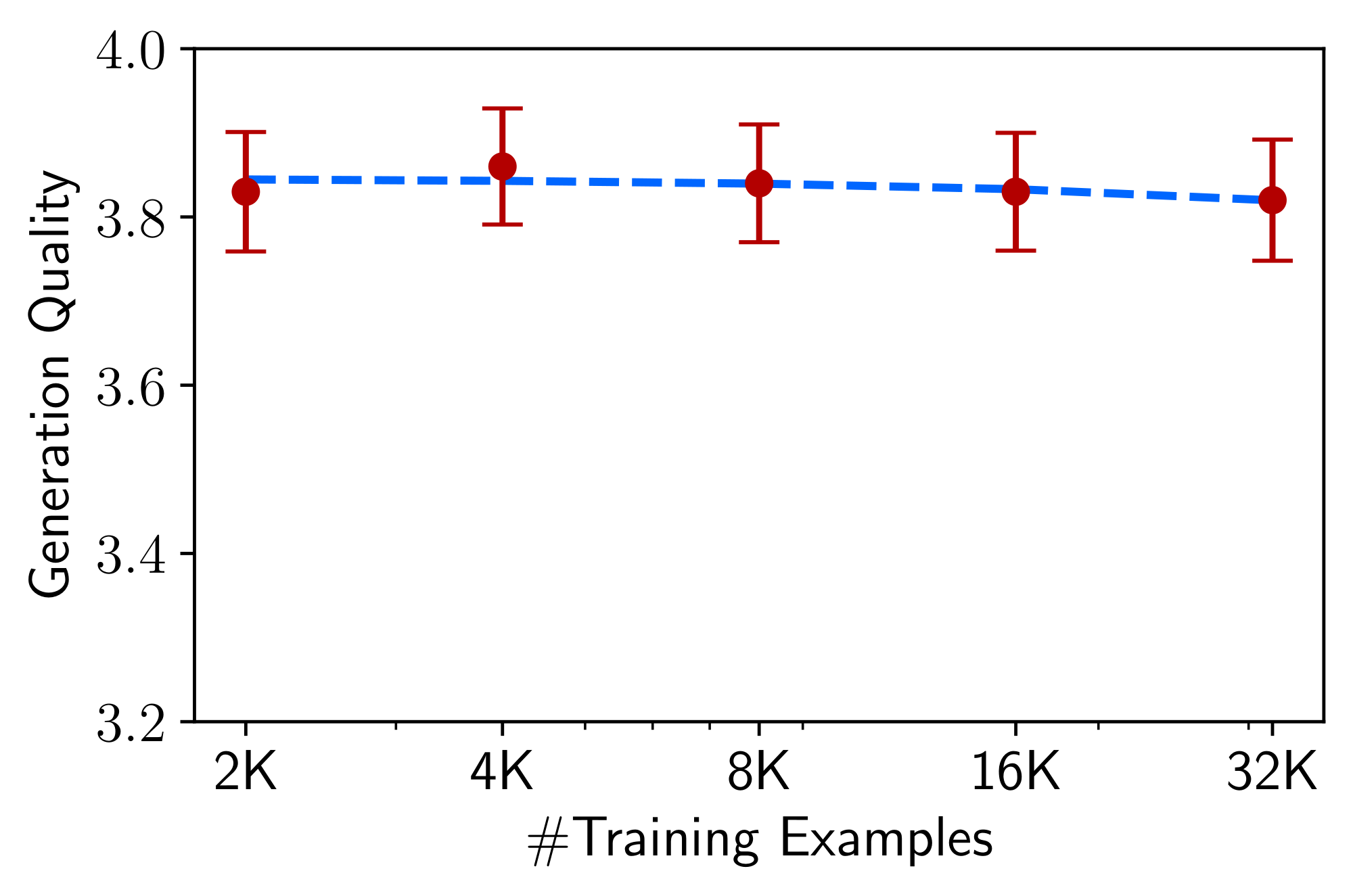
Quantity
Scaling up the number of examples is a well-known strategy for improving performance in many machine learning settings. To test its effect on our setting, we sample exponentially increasing training sets from Stack Exchange. Figure 6 shows that, surprisingly, doubling the training set does not improve response quality. This result, alongside our other findings in this section, suggests that the scaling laws of alignment are not necessarily subject to quantity alone, but rather a function of prompt diversity while maintaining high quality responses.
6. Multi-Turn Dialogue
Section Summary: Researchers tested whether LIMA, a model trained on just 1,000 single-turn conversations, could handle ongoing dialogues without extra training, finding it surprisingly coherent but failing to stay on track in most of six out of ten chats within a few exchanges. To boost its skills, they added 30 multi-turn conversation examples—ten created by the team and twenty adapted from online forums—and retrained the model. This small tweak dramatically improved performance, increasing top-quality responses from about 45 percent to 76 percent, slashing failures, and making it clearly better in seven out of ten new test dialogues, suggesting the model's core abilities come from its initial broad training and need only light guidance to shine.
Can a model fine-tuned on only 1, 000 single-turn interactions engage in multi-turn dialogue? We test LIMA across 10 live conversations, labeling each response as Fail, Pass, or Excellent (see Figure 3). LIMA responses are surprisingly coherent for a zero-shot chatbot, referencing information from previous steps in the dialogue. It is clear though that the model is operating out of distribution; in 6 out of 10 conversations, LIMA fails to follow the prompt within 3 interactions.
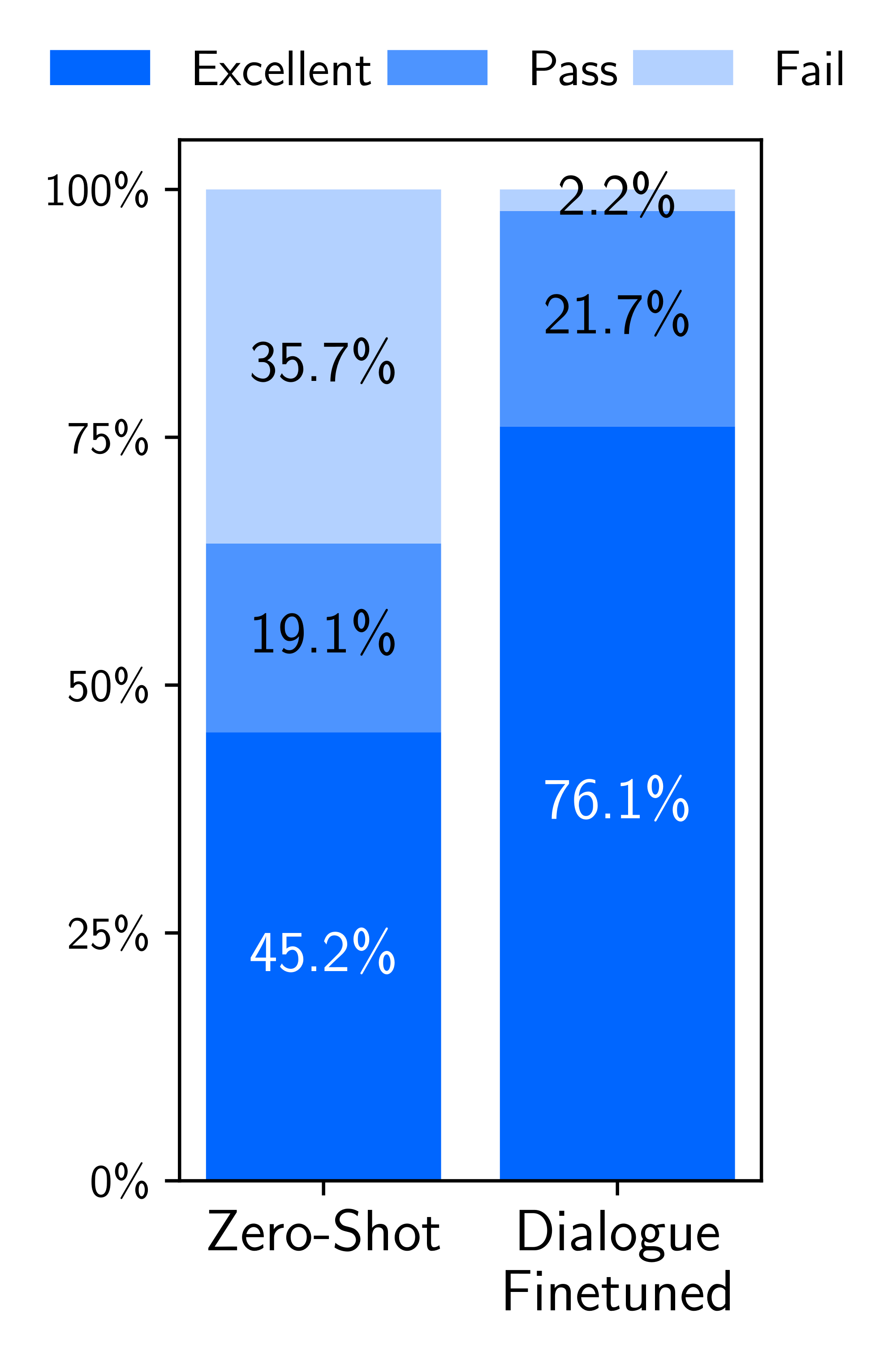
To improve its ability to converse, we gather 30 multi-turn dialogue chains. Among these, 10 dialogues are composed by the authors, while the remaining 20 are based on comment chains from Stack Exchange, which we edit to fit the assistant's style. We fine-tune a new version of LIMA from the pretrained LLaMa model using the combined 1, 030 examples, and conduct 10 live conversations based on the same prompts used for the zero-shot model. Figure 8 shows excerpts from such dialogues.
Figure 7 shows the distribution of response quality. Adding conversations substantially improves generation quality, raising the proportion of excellent responses from 45.2% to 76.1%. Moreover, the failure rate drops from 15 fails per 42 turns (zero-shot) to 1 fail per 46 (fine-tuned). We further compare the quality of the entire dialogue, and find that the fine-tuned model was significantly better in 7 out of 10 conversations, and tied with the zero-shot model in 3. This leap in capability from a mere 30 examples, as well as the fact that the zero-shot model can converse at all, reinforces the hypothesis that such capabilities are learned during pretraining, and can be invoked through limited supervision.[^6]
[^6]: We also experiment with removing examples of a particular task from our dataset. In Appendix E, we show how even 6 examples can make or break the ability to generate text with complex structure.
![**Figure 8:** An example dialogue with LIMA, with and without 30 dialogue examples. The gray ellipsis <span style="color:#808080">[...]</span> indicates that the response was trimmed to fit this page, but the generated text is actually longer.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/2w4n8dks/complex_fig_19cb08db0a0b.png)
7. Discussion
Section Summary: Researchers demonstrated that training a powerful AI language model on just 1,000 carefully chosen examples can yield impressive and competitive performance across a variety of tasks. However, this method has drawbacks, including the intense mental effort required to create those examples, which makes it hard to scale, and the model's lack of robustness compared to commercial AIs, as it can produce poor results from random errors or tricky inputs. Overall, the findings suggest that simple techniques hold great potential for addressing the challenges of aligning AI with human values.
We show that fine-tuning a strong pretrained language model on 1, 000 carefully curated examples can produce remarkable, competitive results on a wide range of prompts. However, there are limitations to this approach. Primarily, the mental effort in constructing such examples is significant and difficult to scale up. Secondly, LIMA is not as robust as product-grade models; while LIMA typically generates good responses, an unlucky sample during decoding or an adversarial prompt can often lead to a weak response. That said, the evidence presented in this work demonstrates the potential of tackling the complex issues of alignment with a simple approach.
Appendix
Section Summary: The appendix details the training process for the LIMA language model, including examples drawn from community Q&A sites and manually created prompts, as shown in figures that highlight how the model was fine-tuned. It explains an unusual finding where the model's perplexity score—a measure of prediction confidence—increased during training but still led to higher-quality responses, evaluated using ChatGPT on a simple rating scale and supplemented by human annotations for preferences. Additionally, adding just six examples of structured text generation, like bullet points or formatted articles, significantly improved the model's ability to handle complex output formats it hadn't seen before, with references to related research provided at the end.
A. Training Examples
Figure 10 shows six training examples from various sources.
![**Figure 10:** **Training examples from different sources.** *Top row:* examples mined from community Q&A. *Bottom row:* manually-authored examples. The <span style="color:#3078BE">blue</span> text is the prompt. The gray ellipsis <span style="color:#808080">[...]</span> indicates that the response was trimmed to fit this page, but the actual training example is longer.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/2w4n8dks/complex_fig_038db5c789c1.png)
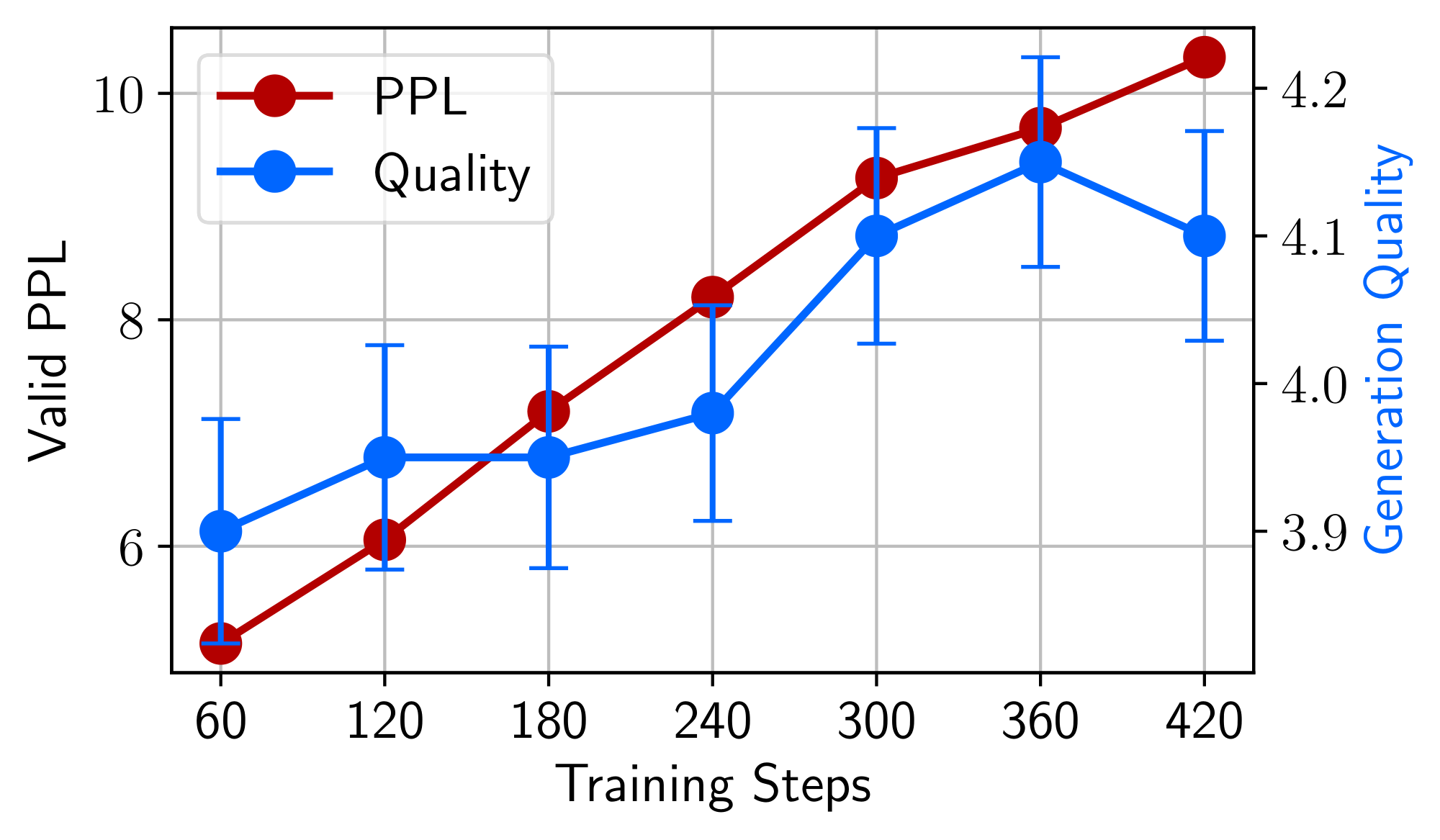
B. Anticorrelation between Perplexity and Generation Quality
When fine-tuning LIMA, we observe that perplexity on held-out Stack Exchange data (2, 000 examples) negatively correlates with the model's ability to produce quality responses. To quantify this manual observation, we evaluate model generations using ChatGPT, following the methodology described in Section 5. Figure 9 shows that as perplexity rises with more training steps – which is typically a negative sign that the model is overfitting – so does the quality of generations increase. Lacking an intrinsic evaluation method, we thus resort to manual checkpoint selection using a small 50-example validation set.
C. Human Annotation
Figure 11 shows the human annotation interface we used to collect preference judgments. Annotators were asked to exercise empathy and imagine that they were the original prompters.

D. ChatGPT Score
Automatically evaluating generative models is a difficult problem. For ablation experiments (Section 5), we use ChatGPT (GPT-3.5 Turbo) to evaluate model outputs on a 6-point Likert score given the prompt in Figure 12.

E. Generating Text with Complex Structure
In our preliminary experiments, we find that although LIMA can respond to many questions in our development set well, it cannot consistently respond to questions that specify the structures of the answer well, e.g. summarizing an article into bullet points or writing an article consisting of several key elements. Hence, we investigate whether adding a few training examples in this vein can help LIMA generalize to prompts with unseen structural requirements. We added six examples with various formatting constraints, such as generating a product page that includes Highlights, About the Product, and How to Use or generating question-answer pairs based on a given article.
After training with these six additional examples, we test the model on a few questions with format constraints and observe that LIMA responses greatly improve. We present two examples in Figure 13, from which we can see that LIMA fails to generate proper answers without structure-oriented training examples (left column), but it can generate remarkably complex responses such as a marketing plan even though we do not have any marketing plan examples in our data (right column).
![**Figure 13:** Model outputs from test prompts that ask the model to generate according to specified structures. The gray ellipsis <span style="color:#808080">[...]</span> indicates that the response was trimmed to fit this page, but the generated text is actually longer.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/2w4n8dks/complex_fig_8d48899d656a.png)
References
[1] Mishra et al. (2021). Natural instructions: Benchmarking generalization to new tasks from natural language instructions. arXiv preprint arXiv:2104.08773. pp. 839–849.
[2] Wei et al. (2022). Finetuned Language Models are Zero-Shot Learners. In International Conference on Learning Representations.
[3] Sanh et al. (2022). Multitask Prompted Training Enables Zero-Shot Task Generalization. In The Tenth International Conference on Learning Representations.
[4] Chung et al. (2022). Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
[5] Edward Beeching et al. (2023). StackLLaMA: An RL Fine-tuned LLaMA Model for Stack Exchange Question and Answering. doi:10.57967/hf/0513. https://huggingface.co/blog/stackllama.
[6] Andreas Köpf et al. (2023). OpenAssistant Conversations – Democratizing Large Language Model Alignment. arXiv preprint arXiv:2304.07327.
[7] Bai et al. (2022). Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862.
[8] Ouyang et al. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems. 35. pp. 27730–27744.
[9] Touvron et al. (2023). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
[10] Rohan Taori et al. (2023). Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_alpaca.
[11] Yuval Kirstain et al. (2021). A Few More Examples May Be Worth Billions of Parameters. arXiv preprint arXiv:2110.04374.
[12] Baumgartner et al. (2020). The Pushshift Reddit Dataset. In Proceedings of the international AAAI conference on web and social media. pp. 830–839.
[13] Kojima et al. (2022). Large Language Models are Zero-Shot Reasoners. In ICML 2022 Workshop on Knowledge Retrieval and Language Models.
[14] Wei et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In Advances in Neural Information Processing Systems.
[15] Wang et al. (2022). Super-NaturalInstructions:Generalization via Declarative Instructions on 1600+ Tasks. In EMNLP.
[16] Or Honovich et al. (2022). Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor. arXiv:2212.09689.
[17] Yizhong Wang et al. (2022). Self-Instruct: Aligning Language Model with Self Generated Instructions. arXiv:2212.10560.
[18] Chiang et al. (2023). Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality*. https://lmsys.org/blog/2023-03-30-vicuna/.
[19] Zhiqing Sun et al. (2023). Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision. arXiv:2305.03047.
[20] Loshchilov, Ilya and Hutter, Frank (2017). Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
[21] Chowdhery et al. (2022). Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
[22] Bai et al. (2022). Constitutional AI: Harmlessness from AI Feedback. arXiv preprint arXiv:2212.08073.
[23] OpenAI (2023). GPT-4 Technical Report. arXiv:2303.08774.
[24] Holtzman et al. (2019). The Curious Case of Neural Text Degeneration. In International Conference on Learning Representations.
[25] Keskar et al. (2019). Ctrl: A conditional transformer language model for controllable generation. arXiv preprint arXiv:1909.05858.
[26] Efrat, Avia and Levy, Omer (2020). The turking test: Can language models understand instructions?. arXiv preprint arXiv:2010.11982.