VideoGPT: Video Generation using VQ-VAE and Transformers
Wilson Yan ${}^{, 1}$
Yunzhi Zhang ${}^{, 1}$
Pieter Abbeel ${}^{1}$
Aravind Srinivas ${}^{1}$
${}^{*}$Equal contribution
${}^{1}$University of California, Berkeley.
Correspondence to: Wilson Yan, Aravind Srinivas <[email protected], [email protected]>
Abstract
We present VideoGPT: a conceptually simple architecture for scaling likelihood based generative modeling to natural videos. VideoGPT uses VQ-VAE that learns downsampled discrete latent representations of a raw video by employing 3D convolutions and axial self-attention. A simple GPT-like architecture is then used to autoregressively model the discrete latents using spatio-temporal position encodings. Despite the simplicity in formulation and ease of training, our architecture is able to generate samples competitive with state-of-the-art GAN models for video generation on the BAIR Robot dataset, and generate high fidelity natural videos from UCF-101 and Tumbler GIF Dataset (TGIF). We hope our proposed architecture serves as a reproducible reference for a minimalistic implementation of transformer based video generation models. Samples and code are available at https://wilson1yan.github.io/videogpt/index.html.
Executive Summary: Video generation using deep learning models has lagged behind advances in images, text, and audio, partly due to the high complexity of capturing spatial and temporal patterns in moving scenes. This gap matters now because generative video models support practical applications like forecasting future frames for autonomous driving, weather prediction, or robotics, where understanding physical dynamics is key. As compute resources grow, simpler, scalable architectures are needed to push video modeling forward without the instability often seen in competing methods like generative adversarial networks (GANs).
This document introduces VideoGPT, a straightforward architecture designed to generate realistic videos by combining two established techniques: a vector quantized variational autoencoder (VQ-VAE) for compressing videos into discrete codes and a transformer-based model (similar to GPT) for predicting those codes sequentially. The goal was to demonstrate that this minimalistic approach could produce high-quality video samples competitive with more complex GAN-based systems, while being easier to train and evaluate.
The team trained VideoGPT in two stages. First, they used a VQ-VAE with 3D convolutions and attention mechanisms to compress short video clips (typically 16 frames at 64x64 resolution) into compact discrete representations, drawing from datasets like BAIR Robot Pushing (over 40,000 robot interaction clips), UCF-101 (13,000 action videos), and Tumblr GIFs (100,000 diverse clips). This compression reduces data redundancy by about 64 times. Second, a transformer model autoregressively generates these representations, which the VQ-VAE then decodes back into videos. Training occurred over 100,000 to 600,000 steps on up to 8 GPUs, with key assumptions including uniform downsampling across space and time to balance efficiency and detail.
The most important results show VideoGPT generating videos that rival state-of-the-art GANs. On the BAIR dataset, it achieved a Fréchet Video Distance (FVD, a measure of realism where lower is better) of 103, matching top GAN performers like TrIVD-GAN and outperforming others like SAVP (116). On UCF-101, it scored 24.7 on Inception Score (IS, higher indicates better diversity and quality), surpassing many GAN baselines but trailing the leader (33). The model produced diverse, realistic clips on natural datasets like Tumblr GIFs, capturing motions like camera pans and human actions without overfitting, unlike on smaller UCF-101 where training and test losses diverged slightly. Ablations confirmed that axial attention in VQ-VAE improved reconstruction quality by 20-30% in FVD, and larger transformers (up to 16 layers) boosted performance until compute limits kicked in.
These findings mean likelihood-based models like VideoGPT can match GAN quality for video generation while offering stable training and reliable evaluation, reducing risks of mode collapse or optimization failures common in GANs. This could lower costs for developing forecasting tools in safety-critical areas like self-driving cars, where predictable outputs aid planning, and enable new uses in simulation for robotics or content creation. Unlike prior work focused on pixel-level modeling, VideoGPT's latent-space approach speeds up sampling by reducing dimensions, though it sometimes sacrifices fine details compared to expectations from image models.
Next, teams should scale VideoGPT to larger datasets beyond 100,000 clips to avoid overfitting and test on higher resolutions (e.g., 128x128 or longer sequences), potentially integrating conditional generation for tasks like action-guided videos. For immediate use, adopt single-codebook VQ-VAEs with balanced downsampling as the baseline, trading minor reconstruction losses for faster training; multiple codebooks offer no clear gains here but could be revisited with more data. A pilot on real-world forecasting applications, like robot trajectory prediction, would validate broader impact.
Confidence in these results is high for the tested datasets and metrics, as they align with established benchmarks and include rigorous ablations, but caution is needed for untested scales—small datasets like UCF-101 showed overfitting, and extreme downsampling can blur details, suggesting gaps in generalizing to diverse real-world videos. Further validation on massive, varied corpora would strengthen applicability.
1. Introduction
Section Summary: Deep generative models have made remarkable strides in creating realistic images, audio, text, and music, thanks to advances in AI architectures and greater computing power. However, generating high-quality natural videos has lagged behind because videos are far more complex, involving intricate patterns across both space and time that demand even more resources. To tackle this, the authors favor stable likelihood-based autoregressive models trained on compressed latent representations to reduce redundancies and improve efficiency, leading to their proposed VideoGPT system for video generation, which also aids applications like weather forecasting and self-driving cars.
Deep generative models of multiple types ([1, 2, 3, 4]) have seen incredible progress in the last few years on multiple modalities including natural images ([5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17]), audio waveforms conditioned on language features ([18, 19, 20, 21]), natural language in the form of text ([22, 23]), and music generation ([24]). These results have been made possible thanks to fundamental advances in deep learning architectures ([25, 3, 5, 26, 6, 27]) as well as the availability of compute resources ([28, 29]) that are more powerful and plentiful than a few years ago.
While there have certainly been impressive efforts to model videos [30, 31, 32, 33], high-fidelity natural videos is one notable modality that has not seen the same level of progress in generative modeling as compared to images, audio, and text. This is reasonable since the complexity of natural videos requires modeling correlations across both space and time with much higher input dimensions. Video modeling is therefore a natural next challenge for current deep generative models. The complexity of the problem also demands more compute resources which can also be deemed as one important reason for the relatively slow progress in generative modeling of videos.
Why is it useful to build generative models of videos? Conditional and unconditional video generation implicitly addresses the problem of video prediction and forecasting. Video prediction ([34, 35, 36, 37]) can be seen as learning a generative model of future frames conditioned on the past frames. Architectures developed for video generation can be useful in forecasting applications for weather prediction [37], autonomous driving (for e.g., such as predicting the future in more semantic and dense abstractions like segmentation masks ([38])). Finally, building generative models of the world around us is considered as one way to measure our understanding of physical common sense and predictive intelligence ([39]).
Multiple classes of generative models have been shown to produce strikingly good samples such as autoregressive models ([3, 5, 40, 27, 22, 16]), generative adversarial networks (GANs) ([2, 41]), variational autoencoders (VAEs) ([1, 42, 43, 44, 14, 45]), Flows ([46, 4, 8, 9]), vector quantized VAE (VQ-VAE) ([12, 13, 17]), and lately diffusion and score matching models ([47, 48, 15]). These different generative model families have their tradeoffs across various dimensions: sampling speed, sample diversity, sample quality, optimization stability, compute requirements, ease of evaluation, and so forth. Excluding score-matching models, at a broad level, one can group these models into likelihood-based (PixelCNNs, iGPT, NVAE, VQ-VAE, Glow), and adversarial generative models (GANs). The natural question is: What is a good model class to pick for studying and scaling video generation?
First, we make a choice between likelihood-based and adversarial models. Likelihood-based models are convenient to train since the objective is well understood, easy to optimize across a range of batch sizes, and easy to evaluate. Given that videos already present a hard modeling challenge due to the nature of the data, we believe likelihood-based models present fewer difficulties in the optimization and evaluation, hence allowing us to focus on the architecture modeling[^1]. Next, among likelihood-based models, we pick autoregressive models simply because they have worked well on discrete data in particular, have shown greater success in terms of sample quality [17], and have well established training recipes and modeling architectures that take advantage of latest innovations in Transformer architectures [26, 49, 50, 51].
[^1]: It is not the focus of this paper to say likelihood models are better than GANs for video modeling. This is purely a design choice guided by our inclination to explore likelihood based generative models and non-empirically established beliefs with respect to stability of training.
Finally, among autoregressive models, we consider the following question: Is it better to perform autoregressive modeling in a downsampled latent space without spatio-temporal redundancies compared to modeling at the atomic level of all pixels across space and time? Below, we present our reasons for choosing the former: Natural images and videos contain a lot of spatial and temporal redundancies and hence the reason we use image compression tools such as JPEG ([52]) and video codecs such as MPEG ([53]) everyday. These redundancies can be removed by learning a denoised downsampled encoding of the high resolution inputs. For example, 4x downsampling across spatial and temporal dimensions results in 64x downsampled resolution so that the computation of powerful deep generative models is spent on these more fewer and useful bits. As shown in VQ-VAE ([12]), even a lossy decoder can transform the latents to generate sufficiently realistic samples. This framework has in recent times produce high quality text-to-image generation models such as DALL-E [17]. Furthermore, modeling in the latent space downsampled across space and time instead of the pixel space improves sampling speed and compute requirements due to reduced dimensionality.
The above line of reasoning leads us to our proposed model: VideoGPT[^2], a simple video generation architecture that is a minimal adaptation of VQ-VAE and GPT architectures for videos. VideoGPT employs 3D convolutions and transposed convolutions ([54]) along with axial attention ([51, 50]) for the autoencoder in VQ-VAE, learning a downsampled set of discrete latents from raw pixels of the video frames. These latents are then modeled using a strong autoregressive prior using a GPT-like ([22, 49, 16]) architecture. The generated latents from the autoregressive prior are then decoded to videos of the original resolution using the decoder of the VQ-VAE.
[^2]: We note that Video Transformers [55] also employ generative pre-training for videos using the Subscale Pixel Networks (SPN) [27] architecture. Despite this, it is fair to use the GPT terminology for our model because our architecture more closely resembles the vanilla Transformer in a manner similar to iGPT [16].
Our results are highlighted below:
On the widely benchmarked BAIR Robot Pushing dataset ([56]), VideoGPT can generate realistic samples that are competitive with existing methods such as TrIVD-GAN ([57]), achieving an FVD of 103 when benchmarked with real samples, and an FVD* ([13]) of 94 when benchmarked with reconstructions.
In addition, VideoGPT is able to generate realistic samples from complex natural video datasets, such as UCF-101 and the Tumblr GIF dataset
We present careful ablation studies for the several architecture design choices in VideoGPT including the benefit of axial attention blocks, the size of the VQ-VAE latent space, number of codebooks, and the capacity (model size) of the autoregressive prior.
VideoGPT can easily be adapted for action conditional video generation. We present qualitative results on the BAIR Robot Pushing dataset and Vizdoom simulator ([58]).
2. Background
Section Summary: The Vector Quantized Variational Autoencoder (VQ-VAE) is a machine learning model that compresses complex data, like images, into a simpler, discrete set of codes stored in a codebook, then reconstructs the original data as accurately as possible. It trains by balancing three goals: faithfully rebuilding the data, aligning the codes with the compressed representations, and keeping the compression stable, with a faster training method using exponential moving averages for updating the codebook. GPT models, including Image-GPT, are powerful transformer-based systems that predict sequences of discrete data, such as words or pixels, by learning patterns step by step through self-attention mechanisms and maximizing the likelihood of correct predictions.
2.1. VQ-VAE
The Vector Quantized Variational Autoencoder (VQ-VAE) ([12]) is a model that learns to compress high dimensional data points into a discretized latent space and reconstruct them. The encoder $E(x)\rightarrow h$ first encodes $x$ into a series of latent vectors $h$ which is then discretized by performing a nearest neighbors lookup in a codebook of embeddings $C = {e_i}_{i=1}^K$ of size $K$. The decoder $D(e)\rightarrow \hat{x}$ then learns to reconstruct $x$ from the quantized encodings. The VQ-VAE is trained using the following objective:
$ \mathcal{L} = \underbrace{\left\lVert x - D(e)\right\rVert_2^2}{\mathcal{L}{\text{recon}}} + \underbrace{\left\lVert sg[E(x)] - e\right\rVert_2^2}{\mathcal{L}{\text{codebook}}} + \underbrace{\beta\left\lVert sg[e] - E(x)\right\rVert_2^2}{\mathcal{L}{\text{commit}}} $
where $sg$ refers to a stop-gradient. The objective consists of a reconstruction loss $\mathcal{L}{\text{recon}}$, a codebook loss $\mathcal{L}{\text{codebook}}$, and a commitment loss $\mathcal{L}_{\text{commit}}$. The reconstruction loss encourages the VQ-VAE to learn good representations to accurately reconstruct data samples. The codebook loss brings codebook embeddings closer to their corresponding encoder outputs, and the commitment loss is weighted by a hyperparameter $\beta$ and prevents the encoder outputs from fluctuating between different code vectors.
An alternative replacement for the codebook loss described in [12] is to use an EMA update which empirically shows faster training and convergence speed. In this paper, we use the EMA update when training the VQ-VAE.
2.2. GPT
GPT and Image-GPT ([16]) are a class of autoregressive transformers that have shown tremendous success in modelling discrete data such as natural language and high dimensional images. These models factorize the data distribution $p(x)$ according to $p(x) = \prod_{i=1}^d p(x_i|x_{<i})$ through masked self-attention mechanisms and are optimized through maximum likelihood. The architectures employ multi-head self-attention blocks followed by pointwise MLP feedforward blocks following the standard design from [26].

3. VideoGPT
Section Summary: VideoGPT is a new approach for efficiently modeling complex video data by first training a system called VQ-VAE to create discrete codes from videos, using 3D convolutions for processing space and time, along with attention mechanisms in its encoder and decoder blocks. These blocks incorporate normalization layers and axial attention to handle the data effectively, with shared learned embeddings for positions. To generate new videos, it then trains a prior network based on an image model architecture, adding dropout for better regularization, and supports conditional generation through techniques like cross-attention for frame inputs or adjustable norms for actions and classes.
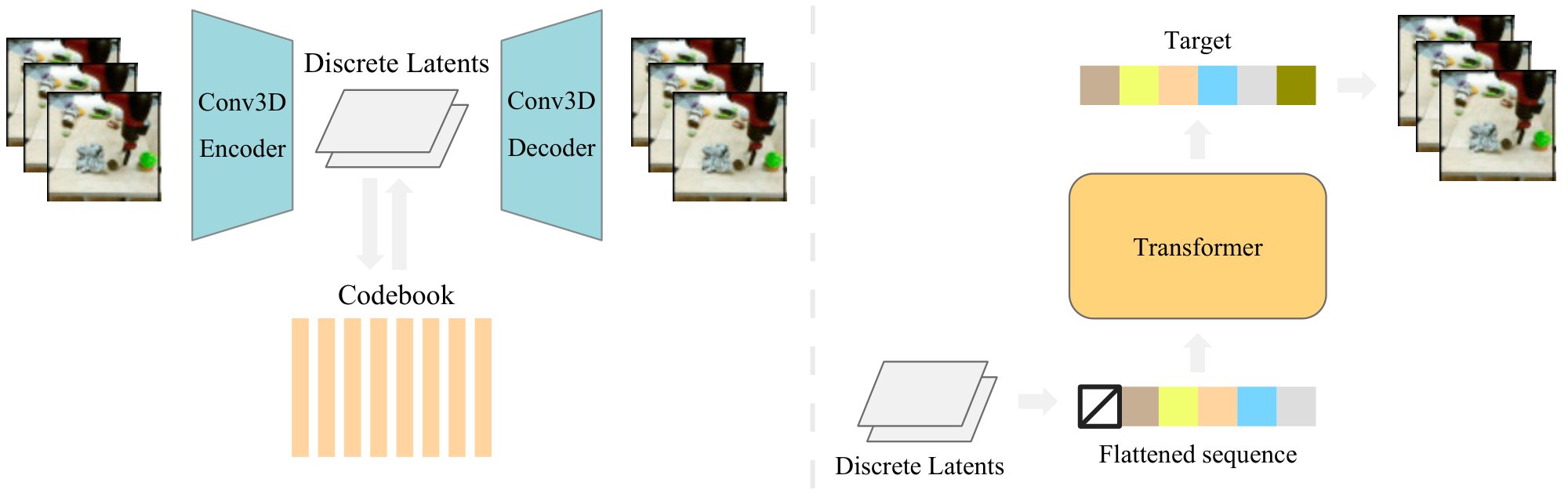
Our primary contribution is VideoGPT, a new method to model complex video data in a computationally efficient manner. An overview of our method is shown in Figure 2.

Learning Latent Codes In order to learn a set of discrete latent codes, we first train a VQ-VAE on the video data. The encoder architecture consists of a series of 3D convolutions that downsample over space-time, followed by attention residual blocks. Each attention residual block is designed as shown in Figure 4, where we use LayerNorm ([59]), and axial attention layers following [51, 50].
The architecture for the decoder is the reverse of the encoder, with attention residual blocks followed by a series of 3D transposed convolution that upsample over space-time. The position encodings are learned spatio-temporal embeddings that are shared between all axial attention layers in the encoder and decoder.
Learning a Prior The second stage of our method is to learn a prior over the VQ-VAE latent codes from the first stage. We follow the Image-GPT architecture for prior network, except that we add dropout layers after the feedforward and attention block layers for regularization.
Although the VQ-VAE is trained unconditionally, we can generate conditional samples by training a conditional prior. We use two types of conditioning:
- Cross Attention: For video frame conditioning, we first feed the conditioned frames into a 3D ResNet, and then perform cross-attention on the ResNet output representation during prior network training.
- Conditional Norms: Similar to conditioning methods used in GANs, we parameterize the gain and bias in the transformer Layer Normalization ([59]) layers as affine functions of the conditional vector. This conditioning method is used for action and class-conditioning models.
4. Experiments
Section Summary: The experiments evaluate a new video generation method called VideoGPT by testing its ability to create realistic video samples from datasets like Moving MNIST, BAIR Robot Pushing, ViZDoom, and UCF-101, while also examining how different design choices in the underlying architecture impact performance. On BAIR and UCF-101, it produces competitive results compared to existing techniques, achieving strong scores on metrics like Fréchet Video Distance and Inception Score, with samples that capture diverse trajectories and environments without simply copying training data. Qualitatively, the model generates lifelike reconstructions and action-conditioned videos, though it shows signs of overfitting on smaller datasets like UCF-101, suggesting a need for larger ones to fully test its potential.
In the following section, we evaluate our method and design experiments to answer the following questions:
- Can we generate high-fidelity samples from complex video datasets?
- How do different architecture design choices for VQ-VAE and prior network affect performance?
4.1. Training Details
All image data is scaled to $[-0.5, 0.5]$ before training. For VQ-VAE training, we use random restarts for embeddings, and codebook initialization by copying encoder latents as described in [24]. In addition, we found VQ-VAE training to be more stable (less codebook collapse) when using Normalized MSE for the reconstruction loss, where MSE loss is divided by the variance of the dataset. For all datasets except UCF-101, we train on $64\times 64$ videos of sequence length $16$. For the transformer, we train Sparse Transformers [49] with local and strided attention across space-time. Exact architecture details and hyperparameters can be found in Appendix A. We achieve all results with a maximum of 8 Quadro RTX 6000 GPUs (24 GB memory).
4.2. Moving MNIST
For Moving MNIST, VQ-VAE downsamples input videos by a factor of 4 over space-time (64x total reduction), and contains two residual layers with no axial-attention. We use a codebook of $512$ codes, each $64$-dim embeddings. To learn the single-frame conditional prior, we train a conditional transformer with $384$ hidden features, $4$ heads, $8$ layers, and a ResNet-18 single frame encoder. Figure 3 shows several different generated trajectories conditioned on a single frame.


:Table 1: FVD on BAIR
| Method $^{\text{3}}$ | FVD ($\downarrow$) |
|---|---|
| SV2P | $262.5$ |
| LVT | $125.8$ |
| SAVP | $116.4$ |
| DVD-GAN-FP | $109.8$ |
| VideoGPT (ours) | $103.3$ |
| TrIVD-GAN-FP | $103.3$ |
| Video Transformer | $\mathbf{94\pm 2}$ |
4.3. BAIR Robot Pushing
For BAIR, VQ-VAE downsamples the inputs by a factor of 2x over each of height, width and time dimensions. The embedding in the latent space is a $256$-dimensional vector, which is discretized through a codebook with $1024$ codes. We use $4$ axial-attention residual blocks for the VQ-VAE encoder and a prior network with a hidden size of $512$ and $16$ layers.
Quantitatively, Table 1[^3] shows FVD results on BAIR, comparing our method with prior work. Although our method does not achieve state of the art, it is able to produce very realistic samples competitive with the best performing GANs.
[^3]: SV2P ([60]), SAVP ([61]), DVD-GAN-FP ([33]), Video Transformer ([55]), Latent Video Transformer (LVT) ([62]), and TrIVD-GAN ([57]) are our baselines
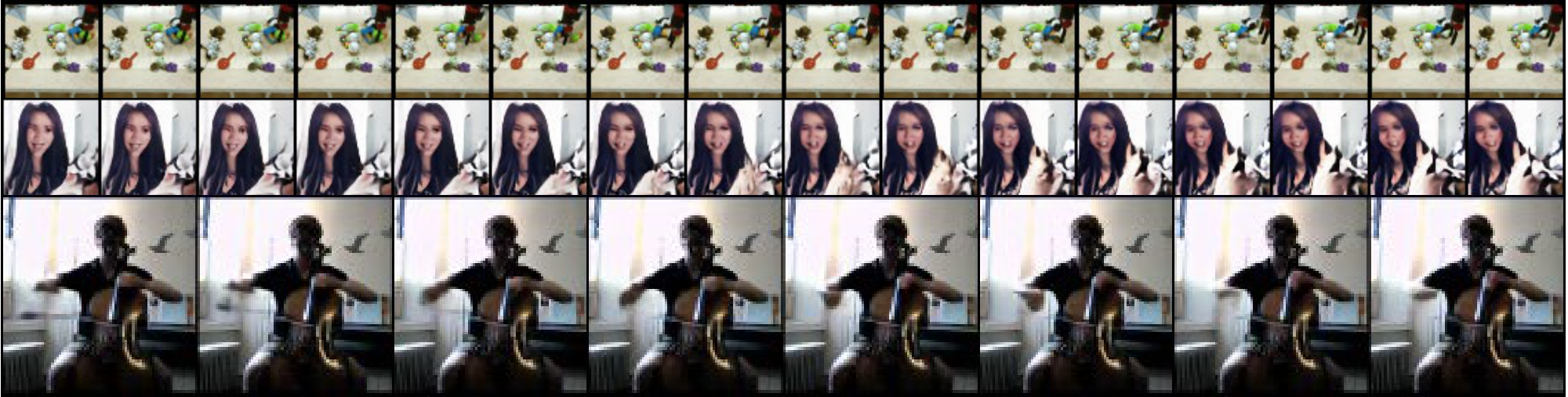
Qualitatively, Figure 5 shows VQ-VAE reconstructions on BAIR. Figure 6 shows samples primed with a single frames. We can see that our method is able to generate realistically looking samples. In addition, we see that VideoGPT is able to sample different trajectories from the same initial frame, showing that it is not simply copying the dataset.
4.4. ViZDoom
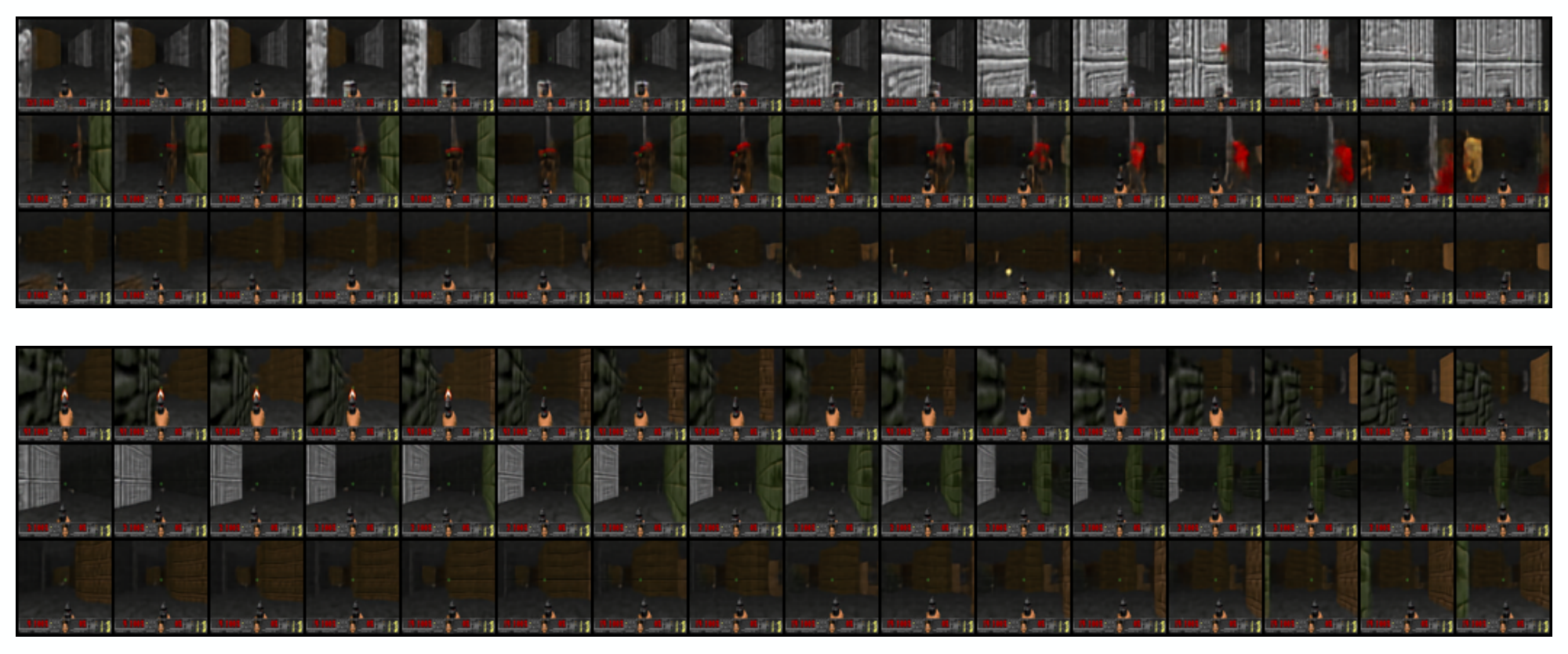
For ViZDoom, we use the same VQ-VAE and transformer architectures as for the BAIR dataset, with the exception that the transformer is trained without single-frame conditioning. We collect the training data by training a policy in each ViZDoom environment, and collecting rollouts of the final trained policies. The total dataset size consists of 1000 episodes of length 100 trajectories, split into an 8:1:1 train / validataion / test ratio. We experiment on the Health Gathering Supreme and Battle2 ViZDoom environments, training both unconditional and action-conditioned priors. VideoGPT is able to capture complex 3D camera movements and environment interactions. In addition, action-conditioned samples are visually consistent with the input action sequence and show a diverse range of backgrounds and scenarios under different random generations for the same set of actions. Samples can be found in Appendix B.[^4]
[^4]: VGAN ([30]), TGAN [63], MoCoGAN ([32]), Progressive VGAN [64], TGAN-F ([65]), TGANv2 [66], DVD-GAN [33] are our baselines for IS on UCF-101.
\begin{tabular}{@{}cc@{}}
\toprule
Method\textsuperscript{4} & IS ($\uparrow$) \\ \midrule
VGAN & $8.31 \pm 0.09$ \\
TGAN & $11.85 \pm 0.07$ \\
MoCoGAN & $12.42 \pm 0.03$ \\
Progressive VGAN & $14.56 \pm 0.05$ \\
TGAN-F & \multicolumn{1}{l}{$22.91 \pm 0.19$} \\
\textbf{VideoGPT (ours)} & \multicolumn{1}{l}{$24.69 \pm 0.30$} \\
TGANv2 & \multicolumn{1}{l}{$28.87 \pm 0.67$} \\
DVD-GAN & \multicolumn{1}{l}{$\mathbf{32.97 \pm 1.7}$} \\ \bottomrule
\end{tabular}
4.5. UCF-101
UCF-101 ([67]) is an action classification dataset with 13, 320 videos from 101 different classes. We train unconditional VideoGPT models on $16$ frame $64 \times 64$ and $128\times 128$ videos, where the original videos have their shorter side scaled to $128$ pixels, and then center cropped.
Table 2 shows results comparing Inception Score[^5] (IS) ([68]) calculations against various baselines. Unconditionally generated samples are shown in Figure 7. Similarly observed in [33], we notice that that VideoGPT easily overfits UCF-101 with a train loss of $3.40$ and test loss of $3.12$, suggesting that UCF-101 may be too small a dataset of the relative complexity of the data itself, and more exploration would be needed on larger datasets.
[^5]: Inception Score is calculated using the code at https://github.com/pfnet-research/tgan2
4.6. Tumblr GIF (TGIF)
TGIF ([69]) is a dataset of 103, 068 selected GIFs from Tumblr, totalling around 100, 000 hours of video. Figure 8 shows samples from a trained unconditional VideoGPT model. We see that the video sample generations are able to capture complex interactions, such as camera movement, scene changes, and human and object dynamics. Unlike UCF-101, VideoGPT did not overfit on TGIF with a train loss of $2.87$ and test loss $2.86$.


4.7. Ablations
In this section, we perform ablations on various architectural design choices for VideoGPT.
Axial-attention in VQ-VAE increases reconstruction and generation quality.
:::
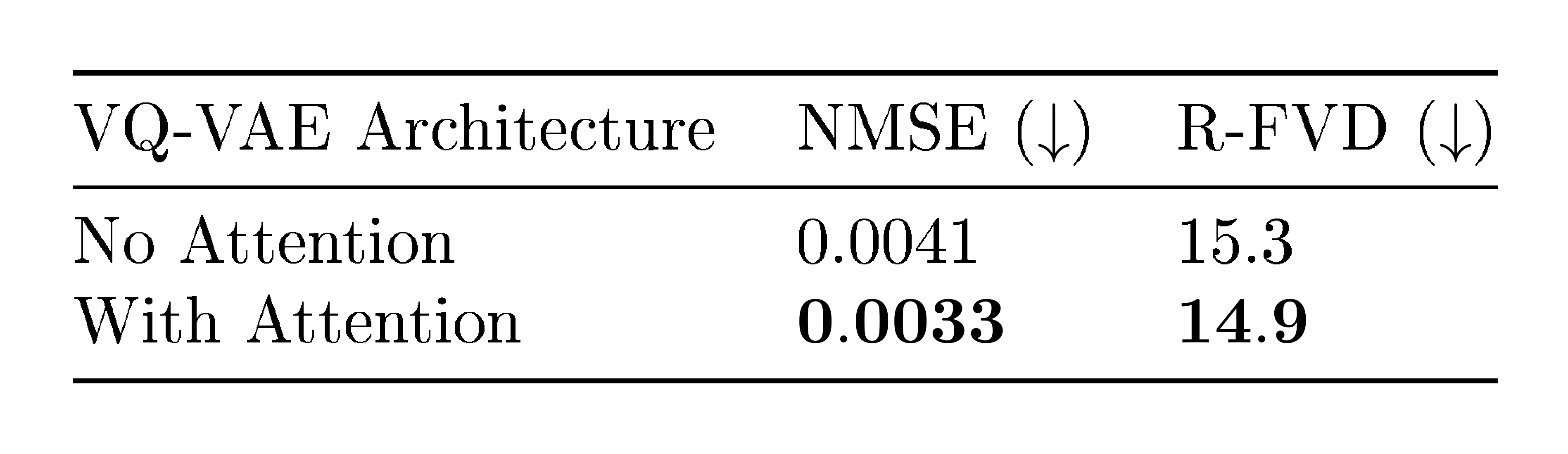
Table 3: Ablation on attention in VQ-VAE. R-FVD is with reconstructed examples
:::
We compare VQ-VAE with and without axial attention blocks as shown in Table 3. Empirically, incorporating axial attention into the VQ-VAE architecture improves reconstruction (NMSE) performance, and has better reconstruction FVD. Note that in order to take into account the added parameter count from attention layers, we increase the number of convolutional residual blocks in the "No Attention" version for better comparability. Figure 5 shows samples of videos reconstructed by VQ-VAE with axial attention module.
Larger prior network capacity increases performance.
:Table 4: Ablations comparing the number of transformer layers
| Transformer Layers | bits/dim | FVD ($\downarrow$) |
|---|---|---|
| 2 | $2.84$ | $120.4 \pm 6.0$ |
| 4 | $2.52$ | $110.0 \pm 2.4$ |
| 8 | $2.39$ | $103.3 \pm 2.2$ |
| 16 | $2.05$ | $103.6 \pm 2.0$ |
Computational efficiency is a primary advantage of our method, where we can first use the VQ-VAE to downsample by space-time before learning an autoregressive prior. Lower resolution latents allow us to train a larger and more expressive prior network to learn complex data distributions under memory constraints. We run an ablation on the prior network size which shows that a larger transformer network produces better results. Table 4 shows the results of training transformers of varied number of layers on BAIR. We can see that for BAIR, our method benefits from training larger models, where the bits per dim shows substantial improvement in increasing layers, and FVD and sample quality show increments in performance up until around 8 layers.
A balanced temporal-spatial downsampling in VQ-VAE latent space increase performance.
:::
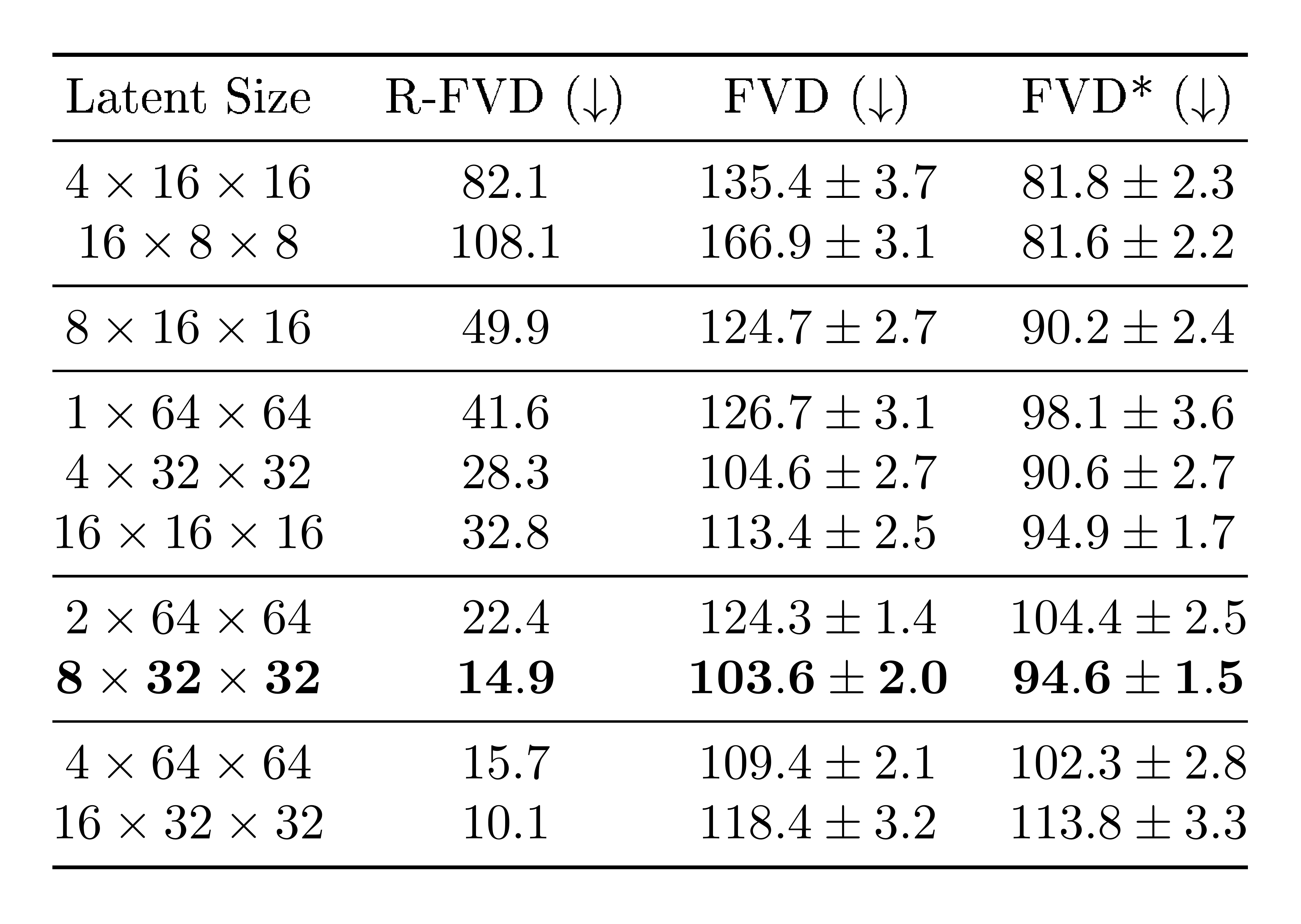
Table 5: Ablations comparing different VideoGPT latent sizes on BAIR. R-FVD is the FVD of VQ-VAE reconstructions, and FVD* is the FVD between samples generated by VideoGPT and samples encoded-decoded from VQ-VAE. For each partition below, the total number of latents is the same with varying amounts of spatio-temporal downsampling
:::
A larger downsampling ratio results in a smaller latent code size, which allows us to train larger and more expressive prior models. However, limiting the expressivity of the discrete latent codes may introduce a bottleneck that results in poor VQ-VAE reconstruction and sample quality. Thus, VideoGPT presents an inherent trade-off between the size of the latents, and the allowed capacity of prior network. Table 5 shows FVD results from training VideoGPT on varying latent sizes for BAIR. We can see that larger latents sizes have better reconstruction quality (lower R-FVD), however, the largest latents $16 \times 32 \times 32$ does not perform the best sample-quality-wise due to limited compute constraints on prior model size. On the other hand, the smallest set of latents $4\times 16 \times 16$ and $16 \times 8 \times 8$ have poor reconstruction quality and poor samples. There is a sweet-spot in the trade-off at around $8\times 32 \times 32$ where we observe the best sample quality.
In addition to looking at the total number of latents, we also investigate the appropriate downsampling for each latent resolution. Each partition in Table 5 shows latent sizes with the same number of total latents, each with different spatio-temporal downsampling allocations. Unsurprisingly, we find that a balance of downsampling ratio ($2\times 2 \times 2$, corresponding to latent size $8\times 32 \times 32$) between space and time is the best, as opposed to downsampling over only space or only time.
Further increasing the number of latent codes does not affect performance.
:::

Table 6: Ablations comparing the number of codebook codes
:::
In Table 6, we show experimental results for running VideoGPT with different number of codes in the codebooks. For all three runs, the VQ-VAE latent code vector has size $8 \times 32 \times 32$. In the case of BAIR, we find that reconstruction quality improves with increasing the number of codes due to better expressivity in the discrete bottleneck. However, they ultimately do not affect sample quality. This may be due to the fact that in the case of BAIR, using 256 codes surpasses a base threshold for generation quality.
Using one VQ-VAE codebook instead of multiple improves performance.
:Table 7: Ablations comparing the number of codebooks
| Latent Size | R-FVD ($\downarrow$) | FVD ($\downarrow$) | bits/dim |
|---|---|---|---|
| $\mathbf{8\times32\times32\times 1}$ | $\mathbf{14.9}$ | $\mathbf{103.6 \pm 2.0}$ | $\mathbf{2.05}$ |
| $16\times 16\times 16\times 2$ | $17.2$ | $106.3 \pm 1.7$ | $2.41$ |
| $8\times 16\times 16 \times 4$ | $17.7$ | $131.4 \pm 2.9$ | $2.68$ |
| $4\times 16\times 16 \times 8$ | $23.1$ | $135.7 \pm 3.3$ | $2.97$ |
In our main results, we use one codebook for VQ-VAE. In Table 7, we compare VideoGPT with different number of codebooks. Specifically, multiple codebooks is implemented by multiplying VQ-VAE's encode output channel dimension by $C$ times, where $C$ is the number of codebooks. The encoder output is then sliced along channel dimension, and each slice is quantized through a separate codebook. As a result, the size of the discrete latents are of dimension $T \times H \times W \times C$, as opposed to $T\times H\times W$ when using a single codebook. Generally, multiple codebooks may be more favorable over increasing the downsampling resolution as multiple codebooks allows a combinatorially better scaling in bottleneck complexity. In our experiments, we increase the number of codebooks, and reduce spatio-temporal resolutions on latent sizes to keep the size of the latent space constant. We see that increasing the number of codebooks worsens sample quality performance, and the best results are attained at the highest resolution with one codebook. Nevertheless, incorporating multiple codebooks might shows its advantage when trained with a larger dataset or a different VQ-VAE architecture design.
5. Related Work
Section Summary: This section reviews prior research on video prediction, which involves forecasting future video frames from past ones and actions, often tested on robot manipulation datasets like BAIR, and includes techniques like vid2vid that transform videos using abstract guides such as semantic masks or poses. For video generation, it covers autoregressive models like Video Pixel Networks and Subscale Video Transformers that build frames pixel by pixel, as well as GAN-based approaches such as DVD-GAN, which create diverse videos conditioned on past frames or classes, though many remain computationally intensive. The authors' method extends VQ-VAE for simpler video generation with discrete latents and transformers, offering an accessible baseline unlike more complex hierarchical setups.
Video Prediction The problem of video prediction ([34]) is quite related to video generation in that the latter is one way to solve the former. Plenty of methods have been proposed for video prediction on the BAIR Robot dataset ([35, 56, 60, 70, 71, 61]) where the future frames are predicted given the past frame(s) and (or) action(s) of a robot arm moving across multiple objects thereby benchmarking the ability of video models to capture object-robot interaction, object permanance, robot arm motion, etc. Translating videos to videos is another paradigm to think about video prediction with a prominent example being vid2vid [72]. The vid2vid framework uses automatically generated supervision from more abstract information such as semantic segmentation ([38]) masks, keypoints, poses, edge detectors, etc to further condition the GAN based video translation setup.
Video Generation Most modern generative modeling architectures allow for easy adaptation of unconditional video generation to conditional versions through conditional batch-norm ([7]), concatenation ([73, 5]), etc. Video Pixel Networks ([36]) propose a convolutional LSTM based encoding of the past frames to be able to generate the next frame pixel by pixel autoregressively with a PixelCNN ([5]) decoder. The architecture serves both as a video generative as well as predictive model, optimized through log-likelihood loss at the pixel level. Subscale Video Transformers ([55]) extend the idea of Subscale Pixel Networks ([27]) for video generation at the pixel level using the subscale ordering across space and time. However, the sampling time and compute requirements are large for these models. In the past, video specific architectures have been proposed for GAN based video generation with primitive results by [30]. Recently, DVD-GAN proposed by [33] adopts a BigGAN like architecture for videos with disentangled (axial) non-local ([74]) blocks across space and time. They present a wide range of results, unconditional, past frame(s) conditional, and class conditional video generation.
Other examples of prior work with video generation of GANs include [63], [32], [64], [75]. In addition, [66] and [65] propose more scalable and efficient GAN models for training on less compute. Our approach builds on top of VQ-VAE ([12]) by adapting it for video generation. A clean architecture with VQ-VAE for video generation has not been presented yet and we hope VideoGPT is useful from that standpoint. While VQ-VAE-2 ([13]) proposes using multi-scale hierarchical latents and SNAIL blocks [76] (and this setup has been applied to videos in [77]), the pipeline is inherently complicated and hard to reproduce. For simplicity, ease of reproduction and presenting the first VQ-VAE based video generation model with minimal complexity, we stick with a single scale of discrete latents and transformers for the autoregressive priors, a design choice also adopted in DALL-E [17].
6. Conclusion
Section Summary: Researchers have introduced VideoGPT, a new system for creating videos by slightly modifying image-generation tools called VQ-VAE and Transformer models. This approach allows VideoGPT to produce videos that match the quality of the best existing methods based on GAN technology. The study also includes tests on important design elements of VideoGPT to guide improvements in future video-making systems.
We have presented VideoGPT, a new video generation architecture adapting VQ-VAE and Transformer models typically used for image generation to the domain of videos with minimal modifications. We have shown that VideoGPT is able to synthesize videos that are competitive with state-of-the-art GAN based video generation models. We have also presented ablations on key design choices used in VideoGPT which we hope is useful for future design of architectures in video generation.
Acknowledgement
The work was in part supported by NSF NRI Grant #2024675 and by Berkeley Deep Drive.
Appendix
A. Architecture Details and Hyperparameters
A.1. VQ-VAE Encoder and Decoder
\begin{tabular}{@{}llcc@{}}
\toprule
& Moving MNIST & \multicolumn{1}{l}{BAIR / RoboNet / ViZDoom} & \multicolumn{1}{l}{UCF-101 / TGIF} \\ \midrule
\multicolumn{1}{l|}{Input size} & $16\times 64\times 64$ & $16\times 64\times 64$ & $16\times 64\times 64$ \\
\multicolumn{1}{l|}{Latent size} & $4\times16\times16$ & $8\times32\times 32$ & $4\times32\times32$ \\
\multicolumn{1}{l|}{$\beta$ (commitment loss coefficient)} & 0.25 & 0.25 & 0.25 \\
\multicolumn{1}{l|}{Batch size} & 32 & 32 & 32 \\
\multicolumn{1}{l|}{Learning rate} & $7\times 10^{-4}$ & $7\times 10^{-4}$ & $7\times 10^{-4}$ \\
\multicolumn{1}{l|}{Hidden units} & 240 & 240 & 240 \\
\multicolumn{1}{l|}{Residual units} & 128 & 128 & 128 \\
\multicolumn{1}{l|}{Residual layers} & 2 & 4 & 4 \\
\multicolumn{1}{l|}{Uses attention} & No & Yes & Yes \\
\multicolumn{1}{l|}{Codebook size} & 512 & 1024 & 1024 \\
\multicolumn{1}{l|}{Codebook dimension} & 64 & 256 & 256 \\
\multicolumn{1}{l|}{Encoder filter size} & 3 & 3 & 3 \\
\multicolumn{1}{l|}{Upsampling conv filter size} & 4 & 4 & 4 \\
\multicolumn{1}{l|}{Training steps} & 20k & 100K & 100K \\ \bottomrule
\end{tabular}
A.2. Prior Networks
\begin{tabular}{@{}lllll@{}}
\toprule
& Moving MNIST & BAIR / RoboNet & ViZDoom & UCF-101 / TGIF \\ \midrule
\multicolumn{1}{l|}{Input size} & $4 \times 16 \times 16$ & $8 \times 32 \times 32$ & $8\times 32 \times 32$ & $4 \times 32 \times 32$ \\
\multicolumn{1}{l|}{Conditional sizes} & $1\times 64\times64$ & $3 \times 64 \times 64$, 64 & $60$ (HGS), $315$ (Battle2) & n/a \\
\multicolumn{1}{l|}{Batch size} & 32 & 32 & 32 & 32 \\
\multicolumn{1}{l|}{Learning rate} & $3\times 10^{-4}$ & $3\times 10^{-4}$ & $3\times 10^{-4}$ & $3\times 10^{-4}$ \\
\multicolumn{1}{l|}{Vocabulary size} & 512 & 1024 & 1024 & 1024 \\
\multicolumn{1}{l|}{Attention heads} & 4 & 4 & 4 & 8 \\
\multicolumn{1}{l|}{Attention layers} & 8 & 16 & 16 & 20 \\
\multicolumn{1}{l|}{Embedding size} & 192 & 512 & 512 & 1024 \\
\multicolumn{1}{l|}{Feedforward hidden size} & 384 & 2048 & 2048 & 4096 \\
\multicolumn{1}{l|}{Resnet depth} & 18 & 34 & n/a & n/a \\
\multicolumn{1}{l|}{Resnet units} & 512 & 512 & n/a & n/a \\
\multicolumn{1}{l|}{Dropout} & 0.1 & 0.2 & 0.2 & 0.2 \\
\multicolumn{1}{l|}{Training steps} & 80k & 150K & 150K & 200K / 600K \\ \bottomrule
\end{tabular}
B. ViZDoom Samples

References
Section Summary: This section lists key research papers and articles that have shaped the field of artificial intelligence, focusing on generative models that can create realistic images, audio, videos, and text from data patterns. It includes foundational works like variational autoencoders and generative adversarial networks from the mid-2010s, along with more recent advances in diffusion models, language processing, and music generation. These references draw from conferences, journals, and preprints, highlighting contributions from researchers at organizations like OpenAI and Google.
[1] Kingma, D. P. and Welling, M. Auto-encoding variational Bayes. Proceedings of the 2nd International Conference on Learning Representations, 2013.
[2] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. Generative adversarial nets. In Advances in neural information processing systems, pp.\ 2672–2680, 2014.
[3] van den Oord, A., Kalchbrenner, N., and Kavukcuoglu, K. Pixel recurrent neural networks. International Conference on Machine Learning (ICML), 2016b.
[4] Dinh, L., Sohl-Dickstein, J., and Bengio, S. Density estimation using Real NVP. arXiv preprint arXiv:1605.08803, 2016.
[5] van den Oord, A., Kalchbrenner, N., Vinyals, O., Espeholt, L., Graves, A., and Kavukcuoglu, K. Conditional image generation with pixelcnn decoders. arXiv preprint arXiv:1606.05328, 2016c.
[6] Zhang, H., Goodfellow, I., Metaxas, D., and Odena, A. Self-attention generative adversarial networks. In International Conference on Machine Learning, pp.\ 7354–7363. PMLR, 2019.
[7] Brock, A., Donahue, J., and Simonyan, K. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018.
[8] Kingma, D. P. and Dhariwal, P. Glow: Generative flow with invertible 1x1 convolutions. arXiv preprint arXiv:1807.03039, 2018.
[9] Ho, J., Chen, X., Srinivas, A., Duan, Y., and Abbeel, P. Flow++: Improving flow-based generative models with variational dequantization and architecture design. arXiv preprint arXiv:1902.00275, 2019a.
[10] Karras, T., Aila, T., Laine, S., and Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv preprint arXiv:1710.10196, 2017.
[11] Karras, T., Laine, S., and Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 4401–4410, 2019.
[12] Van Den Oord, A., Vinyals, O., et al. Neural discrete representation learning. In Advances in Neural Information Processing Systems, pp.\ 6306–6315, 2017.
[13] Razavi, A., van den Oord, A., and Vinyals, O. Generating diverse high-fidelity images with vq-vae-2. In Advances in Neural Information Processing Systems, pp.\ 14866–14876, 2019.
[14] Vahdat, A. and Kautz, J. Nvae: A deep hierarchical variational autoencoder. arXiv preprint arXiv:2007.03898, 2020.
[15] Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. arXiv preprint arXiv:2006.11239, 2020.
[16] Chen, M., Radford, A., Child, R., Wu, J., Jun, H., Dhariwal, P., Luan, D., and Sutskever, I. Generative pretraining from pixels. In Proceedings of the 37th International Conference on Machine Learning, 2020.
[17] Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., and Sutskever, I. Zero-shot text-to-image generation. arXiv preprint arXiv:2102.12092, 2021.
[18] van den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A., and Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016a.
[19] Oord, A. v. d., Li, Y., Babuschkin, I., Simonyan, K., Vinyals, O., Kavukcuoglu, K., Driessche, G. v. d., Lockhart, E., Cobo, L. C., Stimberg, F., et al. Parallel wavenet: Fast high-fidelity speech synthesis. arXiv preprint arXiv:1711.10433, 2017.
[20] Prenger, R., Valle, R., and Catanzaro, B. Waveglow: A flow-based generative network for speech synthesis. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 3617–3621. IEEE, 2019.
[21] Bińkowski, M., Donahue, J., Dieleman, S., Clark, A., Elsen, E., Casagrande, N., Cobo, L. C., and Simonyan, K. High fidelity speech synthesis with adversarial networks. arXiv preprint arXiv:1909.11646, 2019.
[22] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog, 1(8):9, 2019.
[23] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
[24] Dhariwal, P., Jun, H., Payne, C., Kim, J. W., Radford, A., and Sutskever, I. Jukebox: A generative model for music. arXiv preprint arXiv:2005.00341, 2020.
[25] He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385, 2015.
[26] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need. arXiv preprint arXiv:1706.03762, 2017.
[27] Menick, J. and Kalchbrenner, N. Generating high fidelity images with subscale pixel networks and multidimensional upscaling. arXiv preprint arXiv:1812.01608, 2018.
[28] Jouppi, N. P., Young, C., Patil, N., Patterson, D., Agrawal, G., Bajwa, R., Bates, S., Bhatia, S., Boden, N., Borchers, A., et al. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, pp.\ 1–12, 2017.
[29] Amodei, D. and Hernandez, D. Ai and compute. Heruntergeladen von https://blog. openai. com/aiand-compute, 2018.
[30] Vondrick, C., Pirsiavash, H., and Torralba, A. Generating videos with scene dynamics. In Advances in neural information processing systems, pp.\ 613–621, 2016.
[31] Kalchbrenner, N., Oord, A. v. d., Simonyan, K., Danihelka, I., Vinyals, O., Graves, A., and Kavukcuoglu, K. Video pixel networks. arXiv preprint arXiv:1610.00527, 2016.
[32] Tulyakov, S., Liu, M.-Y., Yang, X., and Kautz, J. Mocogan: Decomposing motion and content for video generation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 1526–1535, 2018.
[33] Clark, A., Donahue, J., and Simonyan, K. Adversarial video generation on complex datasets, 2019.
[34] Srivastava, N., Mansimov, E., and Salakhudinov, R. Unsupervised learning of video representations using lstms. In International conference on machine learning, pp.\ 843–852, 2015.
[35] Finn, C., Goodfellow, I., and Levine, S. Unsupervised learning for physical interaction through video prediction. In Advances in neural information processing systems, pp.\ 64–72, 2016.
[36] Kalchbrenner, N., Oord, A., Simonyan, K., Danihelka, I., Vinyals, O., Graves, A., and Kavukcuoglu, K. Video pixel networks. In International Conference on Machine Learning, pp.\ 1771–1779. PMLR, 2017.
[37] Sønderby, C. K., Espeholt, L., Heek, J., Dehghani, M., Oliver, A., Salimans, T., Agrawal, S., Hickey, J., and Kalchbrenner, N. Metnet: A neural weather model for precipitation forecasting. arXiv preprint arXiv:2003.12140, 2020.
[38] Luc, P., Neverova, N., Couprie, C., Verbeek, J., and LeCun, Y. Predicting deeper into the future of semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Oct 2017.
[39] Lake, B. M., Salakhutdinov, R., and Tenenbaum, J. B. Human-level concept learning through probabilistic program induction. Science, 350(6266):1332–1338, 2015.
[40] Parmar, N., Vaswani, A., Uszkoreit, J., Kaiser, Ł., Shazeer, N., and Ku, A. Image transformer. arXiv preprint arXiv:1802.05751, 2018.
[41] Radford, A., Metz, L., and Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015.
[42] Kingma, D. P., Salimans, T., Jozefowicz, R., Chen, X., Sutskever, I., and Welling, M. Improving variational inference with inverse autoregressive flow. In Advances in Neural Information Processing Systems, 2016.
[43] Mittal, G., Marwah, T., and Balasubramanian, V. N. Sync-draw: Automatic video generation using deep recurrent attentive architectures. In Proceedings of the 25th ACM international conference on Multimedia, pp.\ 1096–1104, 2017.
[44] Marwah, T., Mittal, G., and Balasubramanian, V. N. Attentive semantic video generation using captions. In Proceedings of the IEEE International Conference on Computer Vision, pp.\ 1426–1434, 2017.
[45] Child, R. Very deep vaes generalize autoregressive models and can outperform them on images. arXiv preprint arXiv:2011.10650, 2020.
[46] Dinh, L., Krueger, D., and Bengio, Y. Nice: Non-linear independent components estimation. arXiv preprint arXiv:1410.8516, 2014.
[47] Sohl-Dickstein, J., Weiss, E. A., Maheswaranathan, N., and Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. arXiv preprint arXiv:1503.03585, 2015.
[48] Song, Y. and Ermon, S. Generative modeling by estimating gradients of the data distribution. In Advances in Neural Information Processing Systems, pp.\ 11918–11930, 2019.
[49] Child, R., Gray, S., Radford, A., and Sutskever, I. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019.
[50] Ho, J., Kalchbrenner, N., Weissenborn, D., and Salimans, T. Axial attention in multidimensional transformers. arXiv preprint arXiv:1912.12180, 2019b.
[51] Huang, Z., Wang, X., Huang, L., Huang, C., Wei, Y., and Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 603–612, 2019.
[52] Wallace, G. K. The jpeg still picture compression standard. IEEE transactions on consumer electronics, 38(1):xviii–xxxiv, 1992.
[53] Le Gall, D. Mpeg: A video compression standard for multimedia applications. Communications of the ACM, 34(4):46–58, 1991.
[54] Tran, D., Bourdev, L., Fergus, R., Torresani, L., and Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE international conference on computer vision, pp.\ 4489–4497, 2015.
[55] Weissenborn, D., Täckström, O., and Uszkoreit, J. Scaling autoregressive video models. arXiv preprint arXiv:1906.02634, 2019.
[56] Ebert, F., Finn, C., Lee, A. X., and Levine, S. Self-supervised visual planning with temporal skip connections. arXiv preprint arXiv:1710.05268, 2017.
[57] Luc, P., Clark, A., Dieleman, S., Casas, D. d. L., Doron, Y., Cassirer, A., and Simonyan, K. Transformation-based adversarial video prediction on large-scale data. arXiv preprint arXiv:2003.04035, 2020.
[58] Kempka, M., Wydmuch, M., Runc, G., Toczek, J., and Jaśkowski, W. Vizdoom: A doom-based ai research platform for visual reinforcement learning. In 2016 IEEE Conference on Computational Intelligence and Games (CIG), pp.\ 1–8. IEEE, 2016.
[59] Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
[60] Babaeizadeh, M., Finn, C., Erhan, D., Campbell, R. H., and Levine, S. Stochastic variational video prediction. arXiv preprint arXiv:1710.11252, 2017.
[61] Lee, A. X., Zhang, R., Ebert, F., Abbeel, P., Finn, C., and Levine, S. Stochastic adversarial video prediction. arXiv preprint arXiv:1804.01523, 2018.
[62] Rakhimov, R., Volkhonskiy, D., Artemov, A., Zorin, D., and Burnaev, E. Latent video transformer. arXiv preprint arXiv:2006.10704, 2020.
[63] Saito, M., Matsumoto, E., and Saito, S. Temporal generative adversarial nets with singular value clipping. In Proceedings of the IEEE international conference on computer vision, pp.\ 2830–2839, 2017.
[64] Acharya, D., Huang, Z., Paudel, D. P., and Van Gool, L. Towards high resolution video generation with progressive growing of sliced wasserstein gans. arXiv preprint arXiv:1810.02419, 2018.
[65] Kahembwe, E. and Ramamoorthy, S. Lower dimensional kernels for video discriminators. Neural Networks, 132:506–520, 2020.
[66] Saito, M. and Saito, S. Tganv2: Efficient training of large models for video generation with multiple subsampling layers. arXiv preprint arXiv:1811.09245, 2018.
[67] Soomro, K., Zamir, A. R., and Shah, M. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402, 2012.
[68] Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., and Chen, X. Improved techniques for training gans. arXiv preprint arXiv:1606.03498, 2016.
[69] Li, Y., Song, Y., Cao, L., Tetreault, J., Goldberg, L., Jaimes, A., and Luo, J. Tgif: A new dataset and benchmark on animated gif description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.\ 4641–4650, 2016.
[70] Denton, E. L. et al. Unsupervised learning of disentangled representations from video. In Advances in neural information processing systems, pp.\ 4414–4423, 2017.
[71] Denton, E. and Fergus, R. Stochastic video generation with a learned prior. arXiv preprint arXiv:1802.07687, 2018.
[72] Wang, T.-C., Liu, M.-Y., Zhu, J.-Y., Liu, G., Tao, A., Kautz, J., and Catanzaro, B. Video-to-video synthesis. arXiv preprint arXiv:1808.06601, 2018.
[73] Salimans, T., Karpathy, A., Chen, X., and Kingma, D. P. Pixelcnn++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications. arXiv preprint arXiv:1701.05517, 2017.
[74] Wang, X., Girshick, R., Gupta, A., and He, K. Non-local neural networks. arXiv preprint arXiv:1711.07971, 2017.
[75] Yushchenko, V., Araslanov, N., and Roth, S. Markov decision process for video generation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, pp.\ 0–0, 2019.
[76] Chen, X., Mishra, N., Rohaninejad, M., and Abbeel, P. Pixelsnail: An improved autoregressive generative model. arXiv preprint arXiv:1712.09763, 2017.
[77] Walker, J., Razavi, A., and Oord, A. v. d. Predicting video with vqvae. arXiv preprint arXiv:2103.01950, 2021.