Design and Analysis of Switchback Experiments
Iavor Bojinov
Technology and Operations Management Unit, Harvard Business School, Boston, MA 02163, [email protected]
David Simchi-Levi
Institute for Data, Systems, and Society, Department of Civil and Environmental Engineering, and Operations Research Center, Massachusetts Institute of Technology, Cambridge, MA 02139, [email protected]
Jinglong Zhao
Boston University, Questrom School of Business, Boston, MA, 02215, [email protected]
Abstract
Switchback experiments, where a firm sequentially exposes an experimental unit to random treatments, are among the most prevalent designs used in the technology sector, with applications ranging from ride-hailing platforms to online marketplaces. Although practitioners have widely adopted this technique, the derivation of the optimal design has been elusive, hindering practitioners from drawing valid causal conclusions with enough statistical power. We address this limitation by deriving the optimal design of switchback experiments under a range of different assumptions on the order of the carryover effect — the length of time a treatment persists in impacting the outcome. We cast the optimal experimental design problem as a minimax discrete optimization problem, identify the worst-case adversarial strategy, establish structural results, and solve the reduced problem via a continuous relaxation. For switchback experiments conducted under the optimal design, we provide two approaches for performing inference. The first provides exact randomization based $p$-values, and the second uses a new finite population central limit theorem to conduct conservative hypothesis tests and build confidence intervals. We further provide theoretical results when the order of the carryover effect is misspecified and provide a data-driven procedure to identify the order of the carryover effect. We conduct extensive simulations to study the numerical performance and empirical properties of our results, and conclude with practical suggestions.
Executive Summary: Switchback experiments are a key tool for technology companies testing new features, such as pricing algorithms on ride-hailing platforms or promotions in online marketplaces. These tests involve repeatedly assigning a single unit—like an entire city or product line—to treatment or control conditions over time. The approach helps address real-world issues like interference (where one user's treatment affects others) and limited experimental units, which plague traditional A/B tests. However, without proper design, these experiments suffer from high variability, lingering effects from prior treatments (called carryover effects), and unreliable conclusions, potentially leading to flawed business decisions. With tech firms running thousands of such tests annually, optimizing them is urgent to boost efficiency and trust in data-driven choices.
This paper sets out to develop the optimal design and analysis methods for switchback experiments, focusing on estimating causal effects while accounting for carryover effects of known or estimated length (m periods). It aims to minimize estimation error under minimal assumptions about outcomes, making it practical for settings where effects vary across users or time.
The authors use a theoretical framework to solve for the best experiment structure. They treat the problem as a minimax optimization: find the design that minimizes the worst-case estimation variance across possible outcomes. Key assumptions include bounded outcomes and carryover effects lasting exactly m periods, with no anticipation of future treatments. They derive solutions analytically, provide exact and asymptotic inference methods, and validate through simulations using linear models with noise. Data comes from synthetic scenarios mimicking ride-hailing or retail applications, with time horizons up to thousands of periods and sample sizes of 100,000 runs for precision.
The core findings reveal that the optimal design uses fair coin flips (50% chance of treatment at each randomization point) to balance symmetry and reduce bias. Randomization should occur sparingly: every m periods in ideal cases, starting after 2m periods and ending m periods before the horizon (T). For example, if T equals n times m (with n at least 4), points are at 1, 2m+1, up to (n-2)m+1—this cuts variance by 20-30% compared to naive daily randomizations or equal-epoch splits. Inference works via Horvitz-Thompson estimators, yielding unbiased results; exact p-values come from resampling assignments, while asymptotic tests use a new central limit theorem for confidence intervals, conservatively bounding variance to ensure reliability even if m is slightly off. Simulations show the design outperforms benchmarks, with rejection rates reaching 80-90% for detectable effects over longer horizons (T/m > 100), and a procedure to estimate m via paired tests on separate units or epochs.
These results mean firms can run switchback experiments with 25-30% lower variance, leading to sharper estimates of policy impacts—like whether a new surge-pricing rule boosts revenue by 10-20% without interference bias. This matters for risk management: better designs cut false positives/negatives, speed up rollouts (e.g., from weeks to days), and comply with internal standards for causal claims in high-stakes sectors. Unlike prior work assuming specific models, this non-parametric approach is robust, differing from expectations by showing fair flips are always optimal regardless of carryover length.
Next, practitioners should estimate m from domain knowledge or run preliminary tests comparing designs for candidate values (e.g., 1 vs. 2 periods), aiming for T/m over 100 for power. Implement the optimal points via software, using exact inference for small T or asymptotic for large; if multiple units exist, replicate and pool results. For non-ideal T (not a multiple of m), solve the optimization numerically or trim periods to fit.
Confidence is high: proofs establish unbiasedness and optimality under stated assumptions, simulations confirm performance across effect sizes (1-3 units) and noise levels, with type I errors near 5% and type II dropping below 20% at sufficient scale. Caution is needed for large m (near T/4), where variance rises, or unmodeled dynamics like adaptation—pilot tests or model extensions could help. Further work might explore adaptive designs or broader estimands.
1. Introduction
Section Summary: Academic scholars have long recognized the value of experimentation for businesses, but its widespread use has surged in the past decade, driven by cost savings in the tech industry, leading many large companies to adopt A/B testing tools that compare standard and improved versions of products or services over business metrics. However, these simple tests often struggle with interference—where one participant's experience affects others—and estimating personalized effects, issues common in platforms like ride-hailing apps or retail settings. This paper introduces a new framework for switchback experiments, which repeatedly apply treatments to the same unit over time to directly measure individual impacts and overcome interference, while making fewer assumptions about underlying models and outlining optimal designs for practical applications like pricing algorithms or limited-unit studies in finance and psychology.
Academic scholars have appreciated the benefits that experimentation brings to firms for many decades ([1, 2, 3, 4, 5, 6, 7, 8]). However, widespread adoption of the practice has only taken off in the last decade, partly fueled by the rapid cost reductions achieved by firms in the technology sector ([9, 10, 11, 12, 13]). Most large firms now possess internal tools for experimentation, and a growing number of smaller and more conventional companies are purchasing the capabilities from third-party sellers that offer full-stack integration ([14]). These tools typically allow simple "A/ $B''$ tests that compare the standard offering " $A''$ to a new or improved version " $B''$. The comparisons are made across a range of different business outcomes, and the tests are usually conducted for at least a week ([13]). This simple practice has provided tremendous value to firms ([15]).
However, some firms and authors have recognized the limitations of these simple A/B tests ([16, 17]); the two most prominent being handling interference (the scenario where the assignment of one subject impacts another's outcomes) and estimating heterogeneous (or personalized) effects. For example, many online platforms and retail marketplaces often observe varying levels of interference when conducting experiments (see [18, 19, 20, 21, 22, 23, 24] for online platforms like Airbnb, DoorDash, Lyft, and Uber; and [25, 26, 27, 28] for retail markets like Amazon, AB InBev, Rue la la, Zara) and desire to estimate heterogeneous effects (see [29, 30, 31, 32]).
In this paper, we simultaneously tackle both of these two challenges by developing a theoretical framework for the optimal design and analysis of switchback experiments under the minimal amount of assumptions. In switchback experiments, we sequentially expose a unit to a random treatment, measure its response, and repeat the procedure for a fixed period of time ([33, 34]). By administering alternate treatments to the same unit, we can directly estimate an individual level causal effect and alleviate the challenges posed by interference.
In addressing the two challenges, many works in the literature assume specific outcome models under interference. [35, 36, 24] work on experimental design for two-sided online platforms, by assuming that the interference can be captured via game-theoretic modeling. [22] assumes an underlying Markov Chain model and formulates the experimental design problem as estimating the difference between two steady state reward distributions. Some other literature directly models the interference through a network, e.g. [37, 38, 39, 40, 41, 42]. In such models, a treatment assigned to one node of the network creates a "spillover effect, " which impacts the outcomes of the neighboring nodes. All of the above methods make specific assumptions on the outcome models. If these assumptions hold, the above methods correctly identify the causal effects (or the model parameters) with great precision; if these assumptions do not hold, the estimates are likely biased.
Unlike the above works, we make no specific outcome model assumptions in this paper. Instead, we make assumptions about the existence of the carryover effects, which refer to the persistence of past interventions in impacting the future outcomes. More specifically, we make assumptions on the order of carryover effects, which refers to the duration of time periods of such persistence. We then establish formal results on the optimal design of switchback experiments under different assumptions of the order of the carryover effects; we also propose a data-driven procedure to estimate the order of the carryover effects.
Applications. There are two classes of applications where switchback experiments are widely used in practice. The first arises when units interfere with each other either through a network or some more complicated unknown structure. For example, consider a ride-hailing platform that wants to test a new fare pricing algorithm's effectiveness in a large city ([21]). Administering the test version to a subset of drivers can impact their behavior, which, in turn, could change the behavior of drivers that are receiving the old version. Directly comparing the revenue generated by the drivers across the two groups will likely provide a biased estimate of what would happen if everyone were assigned to the new version compared to the old. Instead, practitioners treat the city as a single aggregated unit and use a switchback experiment to estimate the intervention's effectiveness, thereby alleviating the problem caused by interference. A similar issue often arises in revenue management when, for example, a retailer wants to test the effectiveness of a new promotion planning algorithm ([26]). Administering the new version to a subset of Stock Keeping Units (SKU's) cannibalizes the sales from the other SKU's. Again comparing the generated revenue across the two groups is unlikely to provide an accurate measure of the promotion's effectiveness. Again, practitioners treat all the SKU's as a single aggregated unit and use a switchback experiment to obtain accurate estimates of the promotion's effectiveness.
The second application arises when we have a limited number of experimental units, and we believe the effects are likely to be heterogeneous. For example, [34] used switchback experiments to make causal claims about the relative effectiveness of algorithms compared with humans at executing large financial trades across a range of financial markets. More generally, psychologists and biostatisticians regularly use switchback experiments whenever studying the effectiveness of an intervention on a single unit, e.g., [43] and [44].
Main Contributions. There are three significant challenges to using switchback experiments. The first is that causal estimators from switchback experiments have large variances as the precision is a function of the total number of assignments. The second is that past interventions are likely to impact future outcomes; this is often referred to as a carryover effect. Typically, many authors assume that there are no carryover effects ([45, 46, 47]), although some recent work has relaxed this assumption ([33, 48, 49]). The third is that standard super population inference — where researchers either assume a model for the outcome, or that the units are sampled from an infinitely large population — requires unrealistic assumptions that fail to capture the problem's personalized nature ([34]).
This paper's main contributions are to address these three challenges and present a framework that allows firms and researchers to run reliable switchback experiments. First, we derive optimal designs for switchback experiments, ensuring that we select a design that leads to the lowest variance among the most popular class assignment mechanisms. The designs are optimal in the sense that we search for both the optimal randomization points and the optimal randomization probabilities, which, together, capture the most general class of randomization mechanisms. Second, we assume the presence of a carryover effect and show that our estimation and inference are valid both when the order of the carryover effect is correctly specified and misspecified, the latter leading to a minor increase in the variance. For practitioners, we also propose a method to identify the order of the carryover effect by running a series of carefully designed switchback experiments. Finally, we take a purely design-based perspective on uncertainty; that is, we treat the outcomes as unknown but fixed (or equivalently, we condition on the set of potential outcomes) and assume that the assignment mechanism is the only source of randomness ([50, 51, 52, 53]). The main benefit of a design-based perspective is that the inference, and in turn the causal conclusions, do not depend on our ability to correctly specify a model describing the phenomena we are studying, ensuring that our findings are wholly non-parametric and robust to model misspecification ([54], Chapter 5).
Roadmap. The paper is structured as follows. In Section 2 we define the notations, the assumptions, and the assignment mechanism that we focus on, which we will refer to as the regular switchback experiments. In Section 3, we discuss how to design an effective regular switchback experiment under the minimax rule. The design is optimal with respect to (i) the optimal treatment assignment probability, and (ii) the randomization frequency and randomization points. We cast the design problem as a minimax discrete optimization problem, identify the worst-case adversarial strategy, establish structural results, and then explicitly find the optimal design. In Section 4, we discuss how to perform inference and conduct statistical testing based on the results obtained from an optimally designed switchback experiment. We propose an exact test for sharp null hypotheses, and an asymptotic test for testing the average treatment effect. We also discuss how to make inference when the carryover effect is misspecified, and how to conduct hypothesis testing to identify the true order of the carryover effect. In Section 5, we run simulations to test the correctness and effectiveness of our proposed theoretical results under various simulation setups. In Section 6, we give empirical illustrations on how to conduct a switchback experiment in practice and conclude with limitations which may lead to future research directions. All technical proofs are in the Appendix.
2. Notations, Assumptions, and Regular Switchback Experiments
Section Summary: This section introduces the basic setup for analyzing experiments like testing a new pricing algorithm on a ride-hailing platform over short time periods, such as hours in a city, where each period assigns the platform to either a control (standard setup) or treatment (new algorithm) condition. It defines an "assignment path" as the full sequence of these choices over a fixed duration, and "potential outcomes" as the possible results that could occur for any sequence, though only one is observed in practice. To simplify analysis, it assumes outcomes at any time depend only on past assignments (not future ones) and are influenced by only the most recent few assignments, allowing for reliable causal inferences without assuming how the data is generated.
2.1 Assignment Paths and Potential Outcomes
We focus our discussion on a single experimental unit. For example, this unit could be a ride-hailing platform testing the effectiveness of a new fare pricing algorithm in a city. At each time point $t\in [T]={1, 2, ..., T}$, we assign the unit to receive an intervention $W_t\in{0, 1}$. For example, one experimental period could be one to two hours for a ride-hailing platform and $T$ could be two weeks, i.e., $T=336$ when one period is one hour. In some applications, the time horizon $T$ is pre-determined, e.g., a typical experimental duration for a ride-hailing platform is a few weeks; however, when $T$ is not pre-determined, Section 6 provides details for how to choose an appropriate $T$. Throughout most of this paper, with the exception being the derivation of our asymptotic results, we consider $T$ to be a known, fixed constant.
Following convention, we say that the unit is assigned to treatment if $W_t=1$ and control when $W_t=0$; in A/B testing terminology, " $A''$ is control and " $B''$ is treatment. For example, [18] studied how a new surge-pricing subsidy (the treatment) compared to the current setup without the subsidy (the control). The assignment path is then the collection of assignments and is denoted using a vector notation whose dimensions are specified in the subscript, $\bm{W}{1:T} = (W_1, W_2, ..., W_T) \in {0, 1}^T$. We adopt the convention that $\bm{W}{1:T}$ stands for a random assignment path, while $\bm{w}_{1:T}$ stands for one realization.
After administering the assigned intervention, we observe a corresponding outcome. For example, this could be the average ride-matching rate (often defined as the proportion of requested rides that were successfully matched with a driver) during each two hour experimental period. Following the extended potential outcomes framework, at time $t\in [T]$, we posit that for each possible assignment path $\bm{w}{1:T}$ there exists a corresponding potential outcome denoted by $Y_t(\bm{w}{1:T})$; the set of all potential outcomes are collected in $\mathbb{Y} = {Y_t(\bm{w}{1:T})}{t \in [T], \bm{w}_{1:T} \in {0, 1}^T}$ with support $\mathbb{Y} \in \mathcal{Y}$.
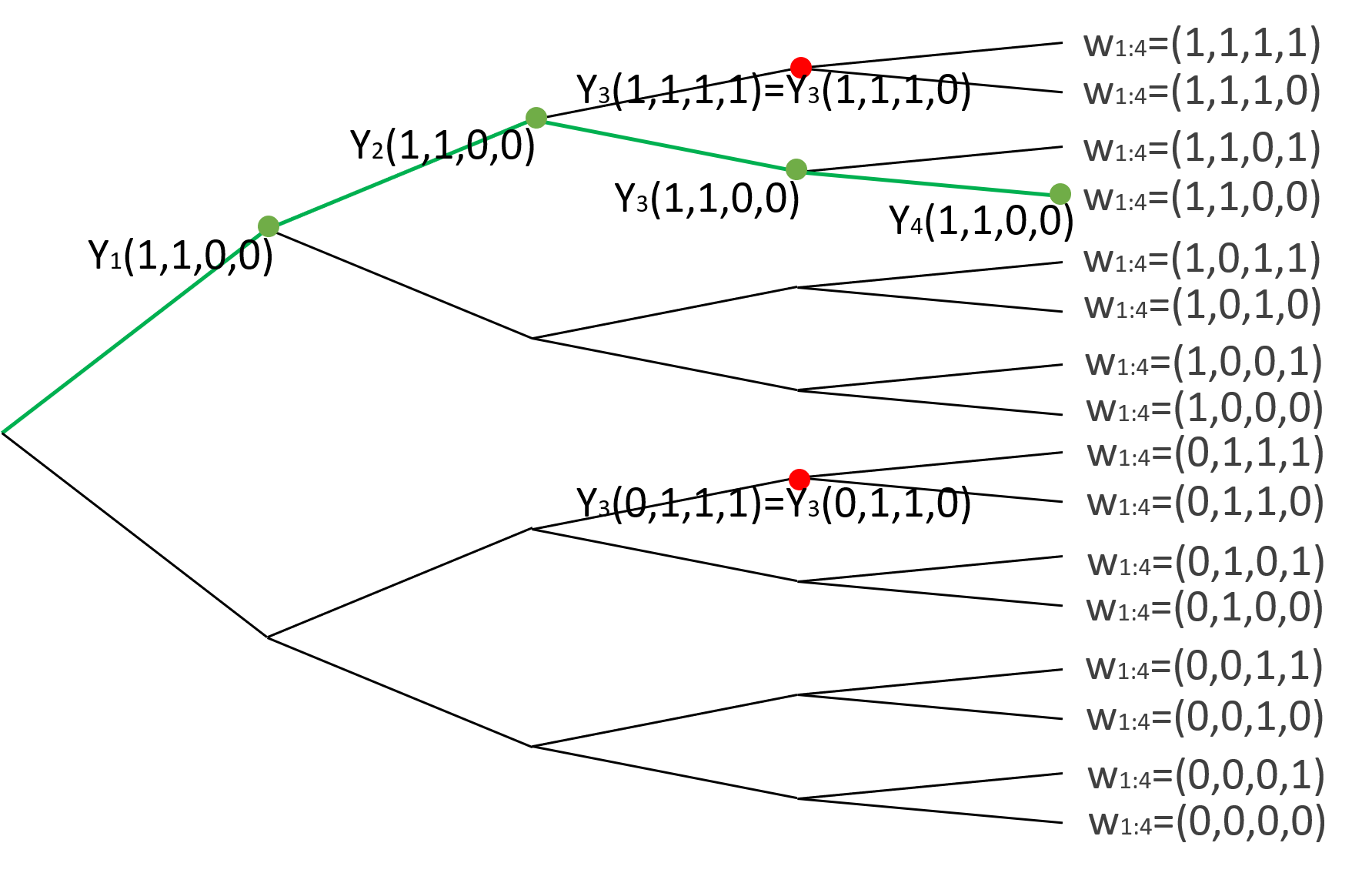
Example 1
When $T=4$, there are $16$ assignment paths as shown in Figure 1.
Associated with each assignment path $\bm{w}{1:4}$ are four potential outcomes $Y_1(\bm{w}{1:4}), Y_2(\bm{w}{1:4}), Y_3(\bm{w}{1:4}), Y_4(\bm{w}_{1:4})$. $\square$
Throughout this paper, we do not directly model the potential outcomes or impose a parametric relationship with the assignment path; instead, we treat them as unknown but fixed quantities, or, equivalently, we implicitly condition on $\mathbb{Y}$. Our setup does not preclude the possibility that the potential outcomes were generated through a dynamic process; however, it allows us to be completely agnostic to the data generating process, making our causal claims more objective. To make inference possible, we rely on the variation introduced by the random assignment path; this is commonly referred to as finite-sample or design-based perspective and has a long history going back to [55], [50], [51], and [52]. Unlike traditional sampling-based inference, the design-based approach does not require a hypothetical population from which to sample experimental units, see [54] and [53] for recent reviews. Instead, we make two assumptions that limit the dependence of the potential outcomes on assignment paths. Below let ${t:t'} = {t, t+1, ..., t'}$, for any $t<t' \in [T]$.
Assumption 2: Non-anticipating Potential Outcomes
For any $t \in [T]$, $\bm{w}{1:t} \in {0, 1}^t$, and for any $\bm{w}'{t+1:T}, \bm{w}''_{t+1:T} \in {0, 1}^{T-t}$,
$ Y_{t}(\bm{w}{1:t}, \bm{w}'{t+1:T}) = Y_{t}(\bm{w}{1:t}, \bm{w}''{t+1:T}). $
Assumption 2 states that the potential outcomes at time $t$ do not depend on future treatments ([34, 56, 57]). Since we control the assignment mechanism instead of letting the experimental units to administer future assignments (e.g., at a ride-hailing platform, a passenger does not know the price in the next hour), the design ensures that this assumption is satisfied.
Example 3: Example Section 2.1 Continued
Under Assumption 2, $Y_3(1, 1, 1, 1) = Y_3(1, 1, 1, 0)$. In Figure 1 the red dot at $Y_3(1, 1, 1)$ stands for both $Y_3(1, 1, 1, 1)$ and $Y_3(1, 1, 1, 0)$. $\square$
Assumption 4: $m$-Carryover Effects
There exists a fixed and given $m$, such that for any $t \in {m+1, m+2, ..., T}, \bm{w}{t-m:T} \in {0, 1}^{T-t+m+1}$, and for any $\bm{w}'{1:t-m-1}, \bm{w}''_{1:t-m-1} \in {0, 1}^{t-m-1}$,
$ Y_{t}(\bm{w}'{1:t-m-1}, \bm{w}{t-m:T}) = Y_{t}(\bm{w}''{1:t-m-1}, \bm{w}{t-m:T}). $
Assumption 4 restricts the order of the carryover effect ([58, 59, 34, 56]). The validity of Assumption 4 depends on the setting and requires practitioners to use their domain knowledge to choose an appropriate $m$. Examples arise in ride-hailing, in which the effect of surge pricing on a ride-hailing platform typically dissipates after one or two hours, depending on the city size ([60]). Moreover, in Section 4.4 we propose a data driven procedure for selecting an appropriate $m$.
Assumptions Assumption 2 and Assumption 4 allow us to simplify notation. For any $t \in {m+1, ..., T}$ and any two assignment paths $\bm{w}{1:T}, \bm{w}'{1:T} \in {0, 1}^{m+1}$, whenever $\bm{w}{t-m:t} = \bm{w}'{t-m:t}$ this leads to
$ Y_{t}(\bm{w}{1:T}) = Y{t}(\bm{w}'_{1:T}). $
In the remainder of this paper, we will write $Y_{t}(\bm{w}{t-m:t}) := Y{t}(\bm{w}{1:T})$ to emphasize the dependence on treatments $\bm{w}{t-m:t}$. For example, the potential outcomes at the two red dots in Figure 1 are equal, i.e., $Y_3(1, 1) := Y_3(1, 1, 1, 1) = Y_3(1, 1, 1, 0) = Y_3(0, 1, 1, 1) = Y_3(0, 1, 1, 0)$
2.2 Causal Effects
In the potential outcomes approach to causal inference, any comparison of potential outcomes has a causal interpretation. In this paper, we focus on a special set of causal estimands that measure the relative effectiveness of persistently assigning a unit to treatment as opposed to control. For any $p \in {0, 1, ..., T-1}$, let $\bm{1}{p+1} = (1, 1, ..., 1)$ be a vector of $(p+1)$ ones; let $\bm{0}{p+1} = (0, 0, ..., 0)$ be a vector of $(p+1)$ zeros. Define the average lag- $p$ causal effect of consecutive treatments on the outcome, for any $p \in {0, 1, ..., T-1}$,
$ \begin{align} \tau_p(\mathbb{Y}) = \frac{1}{T-p} \sum_{t=p+1}^{T} [Y_t(\bm{1}{p+1}) - Y_t(\bm{0}{p+1})]. \end{align}\tag{1} $
This estimand captures the effects of permanently deploying a new policy , and has been widely studied in the longitudinal experiments since the early work of [33].
########## type="Remark"
Although we focus on an average causal effect, all of our results and analysis trivially extend to the total causal effect, which does not normalize, i.e., $(T-p)\tau_p(\mathbb{Y})$.
The optimal design as we will show in Section 3 will remain unchanged.
In our setup, $p$ reflects the experimental designer's knowledge of the order of the carryover effect; see discussion below Assumption 4. Such a knowledge is either correct, which we refer to as the perfect knowledge case ($p=m$), or incorrect, which we refer to as the "misspecified" $m$ case[^1] ($p \ne m$). In this section we focus on the $p=m$ case to derive the optimal design; Section 4.3 considers what happens when $m$ is misspecified by discussing the $p \ne m$ case.
[^1]: Some authors specifically focus on $p<m$, particularly when $m$ is of the same order as $T$ ([34]).
The challenge of causal inference on switchback experiments is that we only observe one assignment path. In other words, for each period $t$, we observe at most either $Y_t(\bm{1}{p+1})$ or $Y_t(\bm{0}{p+1})$ (and sometimes neither). After conducting a switchback experiment, the observed data contains $\bm{w}^{\mathsf{obs}}{1:T}$ the realized assignment path, and $Y_t^{\mathsf{obs}} = Y_t(\bm{w}^{\mathsf{obs}}{1:T})$ the observed outcome at time $t$ under the realized assignment path $\bm{w}^{\mathsf{obs}}_{1:T}$. To link the observed and potential outcomes, we assume there is only one version of the treatment[^2], and that there is no non-compliance.
[^2]: When combined with non-interference if there were multiple units, this is known as the stable unit treatment value assumption ([52]).
2.3 Regular Switchback Experiments
The design of switchback experiment induces a probabilistic distribution over assignment paths $\bm{w}_{1:T} \in {0, 1}^T$. Formally, a design of switchback experiment is any $\eta: {0, 1}^T \to [0, 1]$ such that
$ \begin{align*} \sum_{\bm{w}{1:T} \in {0, 1}^T} \eta(\bm{w}{1:T}) = 1, & & \eta(\bm{w}{1:T}) \geq 0, \ \forall \ \bm{w}{1:T} \in {0, 1}^T. \end{align*} $
Explicitly, $\eta(\cdot)$ is the underlying discrete distribution of the random assignment path $\bm{W}_{1:T}$.
In this paper, we narrow our scope to the family of regular switchback experiments. This family of experiments are parameterized by $\mathbb{T}$ and $\mathbb{Q}$, defined as
$ \mathbb{T} = { t_0 = 1 < t_1 < t_2 < ... < t_K } \subseteq [T], $
where $K < T$ is a positive integer, and $\mathbb{T}$ contains a total of $K+1$ integers, which is a subset of all the time indices; and
$ \mathbb{Q} = (q_0, q_1, ..., q_K) \in (0, 1)^{K+1} := \mathcal{Q}, $
where $\mathbb{Q}$ is a vector of $K+1$ real numbers between $(0, 1)$. For the ease of notations also denote $t_{K+1} = T+1$, though our time horizon is only $T$ periods.
Definition 5: Regular Switchback Experiments
For any $\mathbb{T} = { t_0 = 1 < t_1 < ... < t_K } \subseteq [T]$, and any $\mathbb{Q} = (q_0, q_1, ..., q_K) \in (0, 1)^{K+1}$, a regular switchback experiment $(\mathbb{T}, \mathbb{Q})$ administers a probabilistic treatment at any time $t$, given by:
$ \Pr(W_t = 1) = \begin{aligned} & q_k, & & \text{ \ if \ } t_k \leq t \leq t_{k+1} - 1 \end{aligned}\tag{2} $
In words, the experimental designer jointly decides on a collection of randomization points, which consists of flipping biased coins at each period $t \in {t_0, ..., t_K}$, as well as a collection of randomization probabilities behind the biased coins, $(q_0, ..., q_K)$. If the resulting flip at period $t_k$ is heads, then the experimental designer assigns the unit to treatment during periods $(t_k, t_k+1, ..., t_{k+1}-1)$; otherwise, if tails, assigns the unit to control during periods $(t_k, t_k+1, ..., t_{k+1}-1)$.
Example 6
When $T=4$, $\mathbb{T}={t_0=1, t_1=3}, \mathbb{Q}=(q_0, q_1)=(1/2, 1/2)$ corresponds to the following design: with probability $1/4$, $\bm{W}{1:4} = (1, 1, 1, 1)$; with probability $1/4$, $\bm{W}{1:4} = (1, 1, 0, 0)$; with probability $1/4$, $\bm{W}{1:4} = (0, 0, 1, 1)$; with probability $1/4$, $\bm{W}{1:4} = (0, 0, 0, 0)$.
See Figure 2 (left figure) for the four assignment paths that are in the support of the discrete probability distribution. $\square$
Example 7
Not all switchback experiments are regular.
For example, when $T=4$: with probability $1/4$, $\bm{W}{1:4} = (1, 1, 1, 0)$; with probability $1/4$, $\bm{W}{1:4} = (1, 0, 0, 0)$; with probability $1/4$, $\bm{W}{1:4} = (0, 1, 1, 1)$; with probability $1/4$, $\bm{W}{1:4} = (0, 0, 0, 1)$.
See Figure 2 (right figure) for the four assignment paths that are in the support of the discrete probability distribution. $\square$

In Section 3, we show that fair coin flipping (i.e., $q_k = 1/2, \forall \ k \in {0, 1, ..., K}$) is indeed optimal, under a mild assumption.[^3] The reason behind fair coin flips reflects our limited assumption on the outcome model and the inherent symmetry in the potential outcomes.
[^3]: Researchers have either shown that versions of completely randomized experiments (corresponding to "fair coin flips") are optimal, e.g., [61, 62, 56] where they make mild assumptions on permutation invariance; or have explicitly assumed that the coins flips be fair, e.g., [63, 64].
Note that we do not consider adaptive treatment assignments as most firms design the entire experiment before the experiment is launched; the treatment assignments are typically not updated based on the observed outcomes. We briefly outline adaptive experimental designs as future extensions in Section 6.
For any regular switchback experiment $(\mathbb{T}, \mathbb{Q})$, we may use $\mathbb{T}$ to refer to the same experiment when $\mathbb{Q}$ is clear from the context. We denote the underlying discrete probability distribution using $\eta_{\mathbb{T}, \mathbb{Q}}(\cdot)$. For any $\mathbb{T}$ and $\mathbb{Q}$, the discrete probability distribution has a total of $2^{K+1}$ many supports. The assignment path is random, and follows the discrete probability distribution $\eta_{\mathbb{T}, \mathbb{Q}}(\cdot)$:
$ \eta_{\mathbb{T}, \mathbb{Q}}(\bm{w}{1:T}) = \left{ \begin{aligned} & \prod{k=0}^K q_{t_k}^{\mathbf{1}{ w_{t_k} = 1 }} \cdot \bar{q}{t_k}^{\mathbf{1}{ w{t_k} = 0 }}, & & \text{ \ if \ } \forall \ k \in {0, 1, ..., K}, w_{t_k} = w_{t_k+1} = ... = w_{t_{k+1}-1}, \ & 0, & & \text{ \ otherwise. \ } \end{aligned} \right.\tag{3} $
In the remainder of this paper, unless explicitly noted, all probabilities and expectations are taken with respect to this discrete probability distribution $\eta_{\mathbb{T}, \mathbb{Q}}(\cdot)$.
2.4 Estimation
Now that $\eta_{\mathbb{T}, \mathbb{Q}}(\cdot)$ is determined, following any realization of the assignment path $\bm{w}_{1:T}$, we use the Horvitz-Thompson estimator to estimate the causal effect:
$ \begin{align} \widehat{\tau}p (\eta{\mathbb{T}, \mathbb{Q}}, \bm{w}{1:T}, \mathbb{Y}) & = \frac{1}{T-p} \sum{t=p+1}^T \left{ Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{w}{t-p:t} = \bm{1}{p+1}}}}{\Pr(\bm{W}{t-p:t} = \bm{1}{p+1})} - Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{w}{t-p:t} = \bm{0}{p+1}}}}{{\Pr(\bm{W}{t-p:t} = \bm{0}{p+1})}} \right}. \end{align}\tag{4} $
We emphasize that the estimator $\widehat{\tau}_p (\cdot, \cdot, \cdot)$ depends on (i) the probability distribution that the assignment path is sampled from, (ii) the realization of the assignment path, and (iii) the set of potential outcomes.
Example 8
Suppose $T=4, p=m=1$.
Suppose the assignments are probabilistic and $\Pr(W_t=1) = \Pr(W_t=0) = 1/2, \forall t\in[4].$ With probability $1/16$ the green assignment path as in Figure 1 is administered, $\bm{W}_{1:4} = (1, 1, 0, 0)$.
The estimator is then $\widehat{\tau}_1 = \frac{1}{3}\left{4 Y_2(1, 1) + 0 - 4 Y_4(0, 0)\right}.$ $\square$
Since the assignment path $\bm{W}_{1:T}$ is random, this Horvitz-Thompson estimator is also random. Moreover, when the assignment path satisfies a regular switchback, the probabilities in the denominator are known. As we will show in Theorem 13, under the optimal design, these probabilities will be multiplicatives of $1/2$, allowing us to avoid the known stability issues of the Horvitz-Thompson estimator when the probabilities are extreme (either close to 0 or close to 1). It is well-known that the Horvitz-Thompson estimator is unbiased if the treatment and control probabilities are both non-zero.
Proposition 9: Unbiasedness of the Horvitz-Thompson Estimator
In a regular switchback experiment, under Assumptions Assumption 2 and Assumption 4, the Horvitz-Thompson estimator is unbiased for the average lag- $p$ causal effect of consecutive treatments on outcome, i.e.,
$ \mathbb{E}[\widehat{\tau}p(\eta{\mathbb{T}, \mathbb{Q}}, \bm{W}_{1:T}, \mathbb{Y})] = \tau_p(\mathbb{Y}). $
The expectation $\mathbb{E}[\cdot]$ is taken with respect to the random assignment $\bm{W}{1:T} \sim \eta{\mathbb{T}, \mathbb{Q}}(\cdot)$. when it is obvious we will compress the subscript in the expectation writing $\mathbb{E}[\cdot]$ to mean $\mathbb{E}{\bm{W}{1:T} \sim \eta_{\mathbb{T}, \mathbb{Q}}}[\cdot]$. The proof to Proposition 9 is standard, by checking the expectations. We defer its proof to Section 9 in the Appendix.
2.5 Evaluation of Experiments: the Decision-Theoretic Framework
To evaluate the quality of a design of experiment, we adopt the decision-theoretic framework ([65, 66]). When the random design is $\eta_{\mathbb{T}, \mathbb{Q}}(\cdot)$, for any realization of the assignment path $\bm{w}_{1:T}$ and any set of potential outcomes $\mathbb{Y}$, we define the loss function
$ \begin{align*} L(\eta_{\mathbb{T}, \mathbb{Q}}, \bm{w}{1:T}, \mathbb{Y}) = \left(\widehat{\tau}p(\eta{\mathbb{T}, \mathbb{Q}}, \bm{w}{1:T}, \mathbb{Y}) - \tau_p(\mathbb{Y}) \right)^2 \end{align*} $
and the risk function
$ \begin{align} r(\eta_{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}) = \sum_{\bm{w}{1:T} \in {0, 1}^T} \eta{\mathbb{T}, \mathbb{Q}}(\bm{w}{1:T}) \cdot \left(\widehat{\tau}p(\eta{\mathbb{T}, \mathbb{Q}}, \bm{w}{1:T}, \mathbb{Y}) - \tau_p(\mathbb{Y}) \right)^2 \end{align}\tag{5} $
Such a risk function quantifies the expected squared difference between our estimand and estimator. Since the estimator is unbiased, the risk function also has a second interpretation: the variance of the estimator. A design with a lower risk is also a design whose estimator has a lower variance.
Example 10: Examples Section 2.3 and Section 2.4 Revisited
Suppose $T=4$ and $p=m=1$.
As in Example Section 2.3, $\mathbb{T}={1, 3}$. With probability $1/4$, $\bm{W}{1:4} = (1, 1, 0, 0)$, $\widehat{\tau}1(\mathbb{T}) = \frac{1}{3}{2Y_2(1, 1)-2Y_4(0, 0)}$, $L(\eta{\mathbb{T}, \mathbb{Q}}, \bm{w}{1:T}, \mathbb{Y}) = \frac{1}{9} \left(Y_2(1, 1) + Y_2(0, 0) - Y_3(1, 1) + Y_3(0, 0) - Y_4(1, 1) - Y_4(0, 0) \right)^2.$ As in Example Section 2.4, $\tilde{\mathbb{T}}={1, 2, 3, 4}$. With probability $1/16$, $\bm{W}{1:4} = (1, 1, 0, 0)$, $\widehat{\tau}1(\tilde{\mathbb{T}}) = \frac{1}{3}{4Y_2(1, 1)-4Y_4(0, 0)}$, $L(\eta{\tilde{\mathbb{T}}, \mathbb{Q}}, \bm{w}{1:T}, \mathbb{Y}) = \frac{1}{9} \left(3Y_2(1, 1) + Y_2(0, 0) - Y_3(1, 1) + Y_3(0, 0) - Y_4(1, 1) - 3Y_4(0, 0) \right)^2.$ $\square$
Example Section 2.5 suggests that, even if the two realizations of the assignment path are the same and the potential outcomes are the same, since the probability distributions $\eta_{\mathbb{T}, \mathbb{Q}}$ and $\eta_{\tilde{\mathbb{T}}, \mathbb{Q}}$ are distinct, the corresponding estimators $\widehat{\tau}1(\mathbb{T})$ and $\widehat{\tau}1(\tilde{\mathbb{T}})$ could be different, and the corresponding loss functions $L(\eta{\mathbb{T}, \mathbb{Q}}, \bm{w}{1:T}, \mathbb{Y})$ and $L(\eta_{\tilde{\mathbb{T}}, \mathbb{Q}}, \bm{w}{1:T}, \mathbb{Y})$ could also be different. This observation suggests that there exists some design $\eta{\mathbb{T}^*}$ that has a small risk. In the next section we find such a design when $m$ is correctly specified.
3. Design of Regular Switchback Experiments under Minimax Rule
Section Summary: This section explores how to design regular switchback experiments—alternating between treatment and control periods—to best estimate causal effects, focusing on choosing the right timing and probabilities for random switches. It uses a minimax approach to create a design that performs well even in the worst-case scenarios of unknown outcomes, assuming these outcomes are bounded within a certain range. Key results show that randomizing with equal 50-50 probabilities at switch points is optimal, while the number and placement of switches involve balancing enough randomization for reliable data against too many, which might dilute useful observations.
The goal of this section is to find the optimal design of regular switchback experiments, i.e., to select the optimal randomization points and the optimal randomization probabilities. Throughout this section we assume $m$ is known and we set $p=m$.
We formalize our experimental design problem through the minimax framework. The minimax decision rule ([65, 61, 62]) finds an optimal design of experiment such that the worst-case risk against an adversarial selection of potential outcomes is minimized,
$ \begin{align} \min_{\mathbb{T} \in [T], \mathbb{Q} \in \mathcal{Q}} \max_{\mathbb{Y} \in \mathcal{Y}} \ r(\eta_{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}) = \min_{\mathbb{T} \in [T], \mathbb{Q} \in \mathcal{Q}} \max_{\mathbb{Y} \in \mathcal{Y}} \ \sum_{\bm{w}{1:T} \in {0, 1}^T} \eta{\mathbb{T}, \mathbb{Q}}(\bm{w}_{1:T}) \cdot \left(\widehat{\tau}p(\bm{w}{1:T}, \mathbb{Y}) - \tau_p(\mathbb{Y}) \right)^2. \end{align}\tag{6} $
One compelling reason to adopt the minimax framework, as commented in the seminal work of [61], is that "the experimenter's information about the model is never perfect. When a model is proposed, there is always the possibility that the 'true' model deviates from the assumed model." Instead of finding the best possible design by imposing a model, we try to derive the best possible design for the worse possible set of potential outcomes.
To overcome minimaxity and to lay out the foundation for inference, we impose an additional assumption on the support of the potential outcome. Since the potential outcomes are unknown but fixed, we assume that their absolute values are bounded from above, and that bound is attainable at every time period.
Assumption 11: Bounded Potential Outcomes
The potential outcomes are bounded by some constant, i.e., $\exists \ B>0, s.t. \ \forall \ t \in [T], \ \forall \ \bm{w} \in {0, 1}^T$, $\left| Y_t(\bm{w}) \right| \leq B, $ or, equivalently, $\mathbb{Y} \in \mathcal{Y} = [-B, B]^{T}$.
Assumption 11 is often satisfied since it assumes that the potential outcomes are bounded by the same (possibly a large) constant, (e.g., the ride-matching rate from each experimental period is always a finite quantity) and that the extreme could possibly occur at any point in time (e.g., the maximum ride-matching rate could be observed at any time). In particular, knowledge about the magnitude of $B$ is not required, and, as we show below, the optimal design does not depend on $B$.
The reason to make Assumption 11 is two fold. First, for optimization purposes, Assumption 11 reflects the inherent symmetry in the potential outcomes under both treatment and control, which is in the same spirit as the permutation invariance assumption ([61, 62, 56]). It is such symmetry that ensures the optimality of fair coin flipping. See Theorem 13 below. Second, for inferential purposes, Assumption 11 ensures that the variance of the estimator is well-behaved, which is commonly assumed in the finite-sample inference literature ([67, 68, 34, 69, 70]). It is the well-behaved variance that lays the foundation of our limiting distribution in Theorem 20.
To solve the minimax problem Equation 6, we start by focusing on the inner maximization part. We characterize the worst-case potential outcomes by identifying two dominating strategies for the adversarial selection of potential outcomes. Denote $\mathbb{Y}^{+} = \left{Y_t(\bm{1}{m+1}) = Y_t(\bm{0}{m+1}) = B \right}{t \in {m+1:T}}$ and $\mathbb{Y}^{-} = \left{Y_t(\bm{1}{m+1}) = Y_t(\bm{0}{m+1}) = -B \right}{t \in {m+1:T}}$
Lemma 12
Under Assumptions Assumption 2–Assumption 11, $\mathbb{Y}^{+}$ and $\mathbb{Y}^{-}$ are the only two dominating strategies for the adversarial selection of potential outcomes.
That is, for any $\mathbb{T} \subseteq [T]$ and for any $\mathbb{Y} \in \mathcal{Y}$,
$ \begin{align*} r(\eta_{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}^+) \geq r(\eta_{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}); & & r(\eta_{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}^-) \geq r(\eta_{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}). \end{align*} $
Moreover, for any $\mathbb{Y} \in \mathcal{Y}$ such that $\mathbb{Y} \ne \mathbb{Y}^{+}, \mathbb{Y} \ne \mathbb{Y}^{-}$, the above two inequalities are strict.
The proof of Lemma 12 can be found in Section 10.3.1. Lemma 12 simplifies the minimax problem in Equation 6, as it allows us to replace $\mathbb{Y}$ by $\mathbb{Y}^* = \mathbb{Y}^+$ or $\mathbb{Y}^* = \mathbb{Y}^-$, and reduce the minimax problem Equation 6 into a minimization problem
$ \min_{\mathbb{T}\in[T], \mathbb{Q}\in \mathcal{Q}} r(\eta_{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}^*). $
Next we solve this minimization problem by first finding the optimal $\mathbb{Q}$ values.
Theorem 13: Optimality of Fair Coin Flipping
Under Assumptions Assumption 2–Assumption 11, any optimal design of experiment $(\mathbb{T}, \mathbb{Q})$ must satisfy $q_0=q_1=...=q_K=1/2$.
The proof of Theorem 13 can be found in Section 10.4.1. Theorem 13 suggests that the optimal randomization probabilities should be $1/2$. So we can restrict our scope to only finding the experiments induced by fair coin flipping, and focus on the trade-off behind the number and timing of the randomization points.
The trade-off lies between having too many randomization points (corresponding to large $K$) and too few randomization points (corresponding to small $K$). Intuitively, too many decreases the probability of observing consecutive treatments $\bm{1}{m+1}$ or controls $\bm{0}{m+1}$, which, in turn, decreases the amount of useful data. On the other hand, too few decreases the number of independent observations and reduces our ability to produce reliable results. Both of these scenarios reduce our ability to draw valid causal claims. Theorem 14 formalizes this trade-off.
Theorem 14: Optimal Design
Under Assumptions Assumption 2–Assumption 11, the optimal solution to the design of regular switchback experiment as we have introduced in Equation 6 is equivalent to the optimal solution to the following subset selection problem.
$ \begin{align} \min_{\mathbb{T} \subset [T]} \left{ 4 \sum_{k=0}^{K} (t_{k+1} - t_{k})^2 + 8 m (t_K - t_1) + 4 m^2 K - 4 m^2 + 4 \sum_{k=1}^{K-1} [(m-t_{k+1}+t_{k})^+]^2\right} \end{align}\tag{7} $
In particular, when $m=0$ then $\mathbb{T}^* = {1, 2, 3, ..., T}$; when $m>0$, and if there exists $n \geq 4 \in \mathbb{N}$, s.t. $T = n m$, then $\mathbb{T}^* = {1, 2m+1, 3m+1, ..., (n-2)m+1}$.
The proof of Theorem 14 is deferred to Section 10.6.1 in the appendix. Theorem 14 presents the optimal design in a class of perfect cases when the time horizon splits into several equal-length epochs[^4]; see Table 1 for an example. In practice, we recommend selecting $T$ that satisfies the condition in Theorem 14; see Section 6 for a discussion.
[^4]: For other imperfect cases when $T$ is not divisible by $m$, we can also solve Equation 7 and find the optimal design. However, we do not present closed-form solutions to such subset selection problem due to integrality issues. Technical discussions about the optimal design in such imperfect cases are deferred to Section 10.6 in the Appendix.
::: {caption="Table 1: An example of the optimal design $\mathbb{T}^*={1, 5, 7, 9}$ when $T=12$ and $p=m=2$."}
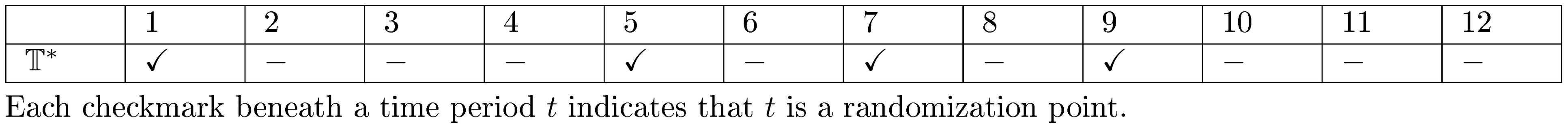
:::
There are two important implications of Theorem 14. First, the optimal randomization frequency depends on the physical duration of the carryover effect, regardless of the granularity of one single experimental period. This observation suggests that practitioners should set each period to be almost as long as the order of the carryover effect, which sheds some light on the selection of granularity when practitioners design the experiment. See Example Section 3. Second, a special case arises when there are no carryover effects $(m=0)$ or very little carryover effect $(m=1)$; in both cases the optimal designs are almost the same. This observation suggests a layer of robustness when the granularity is set to be the same as the suspected order of the carryover effect; see Example Section 3.
Example 15: Two Granularity Levels
In the ride-sharing application, suppose the firm has two options to treat one single time period either as 0.5 hour or 1 hour; and suppose the carryover effect lasts for 2 hours.
When one single experimental period corresponds to 0.5 hour, the carryover effect lasts for $m=4$ periods.
When one single experimental period corresponds to 1 hour, the carryover effect lasts for $m=2$ periods.
From Theorem 14, the optimal design exhibits an optimal structure that randomizes once every $m$ periods (except for the first and last epoch, which lasts for $2m$ time periods each).
In both cases, the optimal design would randomize once every two hours. $\square$
Example 16: Little Carryover Effect
For example, Theorem 14 suggests that the optimal design when $m=0$ is $\mathbb{T}^* = {1, 2, 3, ..., T}$, and when $m=1$ is $\mathbb{T}^* = {1, 3, 4, ..., T-1}$.
This suggests that the minimax optimal design in the absence of a carryover effect is robust to the existence of a short carryover effect.
4. Inference and Testing
Section Summary: After running the experiment, researchers analyze the sequence of treatments given and the resulting outcomes over time to draw conclusions about treatment effects. They propose two testing methods: an exact test that simulates alternative treatment paths to check if outcomes would be identical with no effects, and a more practical asymptotic test that approximates the average treatment effect using statistical bounds and variance estimates. These approaches account for carryover effects from prior treatments and include ways to estimate such effects through additional experiments if needed.
After designing and running the experiment, we obtain two time series. The first is the observed assignment path $\bm{w}{1:T}^{\mathsf{obs}}$, and the second is the corresponding observed outcomes $\bm{Y}{1:T}^{\mathsf{obs}}$. See Figure 3. To draw inference from this data we propose two methods, an exact randomization based test and a finite population conservative test that establishes asymptotic result.
In Section 4.1 and Section 4.2, we assume perfect knowledge of $m$, i.e., $p=m$, and we will write $\tau_m$ and $\widehat{\tau}_m$ to stand for $\tau_p$ and $\widehat{\tau}_p$, respectively. We discuss in Section 4.3 the case when $p \ne m$ and show that our inference methods are still valid. To conclude this section, we provide in Section 4.4 a data-driven procedure to identify a possible value for the carryover effect by running multiple experiments. Such a procedure relaxes Assumption 4 and is of great practical relevance.
4.1 Exact Inference
We propose an exact non-parametric test for the sharp null of no effect at every time point ([50, 52, 34]):
$ H_{0}:Y_{t}(\bm{w}{t-m:t}) - Y{t}(\bm{w}'{t-m:t}) = 0 \quad \text{for all } \bm{w}{t-m:t}, \bm{w}_{t-m:t}^{\prime }, \quad t \in {m+1:T}.\tag{8} $
The sharp null hypothesis implies that $Y_{t}(\bm{w}{t-m:t}^{\mathsf{obs}})=Y{t}(\bm{w}{t-m:t})$ for all $\bm{w}{t-m:t} \in {0, 1}^t$. That is, regardless of the assignment path $\bm{w}_{t-m:t}$ we would have observed the same outcomes.
We can conduct exact tests by using the known assignment mechanism to simulate new assignment paths; see Algorithm 1 for details. The test depends on the observation that, under the sharp null hypothesis of no treatment effect Equation 8, any assignment path $\bm{w}^{[i]}{1:T}$ leads to the same observed outcomes. In particular, in Step 3, we assume the observed outcomes remain unchanged. Thus all treatment paths lead to the same observed outcomes $Y^\mathsf{obs}{m+1:T}$. To obtain a confidence interval, we propose inverting a sequence of exact hypothesis tests to identify the region outside of which Equation (8) is violated at the prespecified nominal level ([54], Chapter 5). In practice, obtaining confidence intervals through this approach is somewhat challenging; instead, we refer the reader to the subsequent section that provides a less computationally intensive approach.

4.2 Asymptotic Inference
We now introduce a conservative test for the null of no average treatment effect:
$ H_{0}: \tau_m = \frac{1}{T-m} \sum_{t=m+1}^{T} [Y_t(\bm{1}{m+1}) - Y_t(\bm{0}{m+1})] = 0.\tag{9} $
To test such a null, we derive a finite population central limit theorem to approximate the distribution of the Horvitz-Thompson estimator.
Assume $n = T/m \geq 4$ is an integer, then under the optimal design as shown in Theorem 13 and Theorem 14, the assignment path is determined by the realizations at $W_1, W_{2m+1}, ..., W_{(n-2)m+1}$. To make the dependence on randomization clear, we introduce the following notations. For any $k \in {0, 1, ..., n-2}$, let $\bar{Y}k(\bm{1}{m+1}) = \sum_{t=(k+1)m+1}^{(k+2)m} Y_t(\bm{1}{m+1})$ and $\bar{Y}k(\bm{0}{m+1}) = \sum{t=(k+1)m+1}^{(k+2)m} Y_t(\bm{0}_{m+1})$. Moreover, for any $k \in {0, 1, ..., n-2}$, let $\bar{Y}k^\mathsf{obs} = \sum{t=(k+1)m+1}^{(k+2)m} Y_t^\mathsf{obs}$ be the sum of the observed outcomes.
Lemma 17: Variance of the Horvitz-Thompson Estimator Under the Optimal Design
Under Assumptions Assumption 2–Assumption 11 and under the optimal design as shown in Theorem 13 and Theorem 14, if $n = T/m \geq 4$ is an integer, then the variance of the Horvitz-Thompson estimator, $\mathsf{Var}(\widehat{\tau}_m)$, is
$ \begin{align} \mathsf{Var}(\widehat{\tau}m) = \frac{1}{(T-m)^2} & \left{ \bar{Y}0(\bm{1}{m+1})^2 + \bar{Y}0(\bm{0}{m+1})^2 + 2 \bar{Y}0(\bm{1}{m+1}) \bar{Y}0(\bm{0}{m+1}) \vphantom{\sum{k=0}^{n-3} 2 \left[\bar{Y}k(\bm{1}{m+1}) \right] } \right. \nonumber \ & + \sum_{k=1}^{n-3} \left[3 \bar{Y}k(\bm{1}{m+1})^2 + 3 \bar{Y}k(\bm{0}{m+1})^2 + 2 \bar{Y}k(\bm{1}{m+1}) \bar{Y}k(\bm{0}{m+1}) \right] \nonumber \ & + \bar{Y}{n-2}(\bm{1}{m+1})^2 + \bar{Y}{n-2}(\bm{0}{m+1})^2 + 2 \bar{Y}{n-2}(\bm{1}{m+1}) \bar{Y}{n-2}(\bm{0}{m+1}) \nonumber \ & + \left.\sum_{k=0}^{n-3} 2 \left[\bar{Y}k(\bm{1}{m+1}) + \bar{Y}k(\bm{0}{m+1}) \right] \cdot \left[\bar{Y}{k+1}(\bm{1}{m+1}) + \bar{Y}{k+1}(\bm{0}{m+1})\right] \right} \end{align}\tag{10} $
Lemma 17 provides the variance of the Horvitz-Thompson estimator under the optimal design. Since we never observe all the potential outcomes, most of the cross-product terms in Equation 10 can not be directly estimated. Instead, we provide the following upper bound to 10 and propose an unbiased estimator.
Corollary 18
Under the conditions in Lemma 17, there exists an upper bound for the variance of the Horvitz-Thompson estimator, $\mathsf{Var}(\widehat{\tau}_m) \leq \mathsf{Var}^\mathsf{U}(\widehat{\tau}m)$, which can be estimated by $\widehat{\sigma}^2\mathsf{U}$, defined as:
$ \begin{align*} \widehat{\sigma}^2_\mathsf{U} = \frac{1}{(T-m)^2} \left{ 8 (\bar{Y}0^\mathsf{obs})^2 + \sum{k=1}^{n-3} 32 (\bar{Y}k^\mathsf{obs})^2 \mathbf{1}{W{km+1} = W_{(k+1)m+1}} + 8 (\bar{Y}_{n-2}^\mathsf{obs})^2 \right}. \end{align*} $
Moreover, $\widehat{\sigma}^2_\mathsf{U}$ is unbiased, i.e., $\mathbb{E}[\widehat{\sigma}^2_\mathsf{U}] = \mathsf{Var}^\mathsf{U}(\widehat{\tau}_m)$.
Corollary 18 provides the foundation to make conservative inference. We make the following technical assumption for the asymptotic normal distribution to hold.
Assumption 19: Non-negligible Variance
Assume that the randomization distribution has a non-negligible variance, i.e.,
$ \begin{align} \mathsf{Var}(\widehat{\tau}_m) \geq \Omega(n^{-1}). \end{align}\tag{11} $
In particular, one sufficient condition for Equation 11 is to assume that all the potential outcomes are positive, i.e., there exists some constant $b>0$, such that $\forall t \in [T], \forall \bm{w}{1:T} \in {0, 1}^T$, $Y_t(\bm{w}{1:T}) \geq b$.
Intuitively, the key to most central limit theorems is that all the variables roughly have variances of the same order. In other words, there cannot be a small number of variables that compromise the majority of the variance. Since under Assumption 11 the potential outcomes are bounded, each variable contributes to the total variance of order $O(n^{-2})$. Assumption 19 suggests that the total variance is large enough, such that it cannot come from only a few of the time periods.
Theorem 20: Asymptotic Normality
Let $m$ be fixed. For any $n \geq 4 \in \mathbb{N}$, define an $n$-replica experiment such that there are $T = n m$ time periods.
We take the optimal design as in Theorem 14 whose randomization points are at $\mathbb{T}^* = {1, 2m+1, 3m+1, ..., (n-2)m+1}$.
Under Assumptions Assumption 2–Assumption 4, and under Assumption 19, the limiting distribution of the Horvitz-Thompson estimator in the $n$-replica experiment has an asymptotic normal distribution.
That is, let $\mathsf{Var}(\widehat{\tau}_m)$ be defined in Lemma 17.
As $n \to +\infty$,
$ \begin{align*} \frac{\widehat{\tau}_m - \tau_m}{\sqrt{\mathsf{Var}(\widehat{\tau}_m)}} \xrightarrow[]{D} \mathcal{N}(0, 1). \end{align*} $
Theorem 20 is in the spirit of the finite population central limit theorems as in [71, 67, 68, 49, 70]. Note that, Theorem 20 does not require $\mathsf{Var}(\widehat{\tau}_m)$ to converge as $n \to +\infty$.
To conduct inference, we replace $\mathsf{Var}(\widehat{\tau}m)$ by $\widehat{\sigma}{\mathsf{U}}^2$ as provided in Corollary 18. Define the test statistic to be $z = \left| \widehat{\tau}m \right| / \sqrt{\widehat{\sigma}{\mathsf{U}}^2}$. When the alternative hypothesis is two-sided, the estimated $p$-value is given by $\widehat{p}_{\mathsf{N}} = 2 - 2 \Phi(z)$, where $\Phi$ is the CDF of a standard normal distribution.
The proofs of Lemma 17, Corollary 18, and Theorem 20 are deferred to Section 11.2, Section 11.3, and Section 11.4 in the Appendix, respectively.
4.3 Inference under Misspecified $m$
Up to now, we assumed that we knew the order of the carryover effect $m$, and set $p=m$. In practice, we may not know the exact value of the carryover effect, and we have to select $p$ either based on domain knowledge or the procedure we recommend in Section 4.4. In this section, we consider what happens when $p \ne m$ and show that the estimation and inference are still valid and meaningful, although the design from Theorem 14 is no longer optimal. Below we distinguish two cases: $p>m$ and $p<m$.
When $p>m$, due to Assumption 4, $Y_t(\bm{1}{p+1}) = Y_t(\bm{1}{m+1}), \forall t \in {p+1:T}$, and the lag- $p$ causal effect is essentially the lag- $m$ causal effect. So all the estimation and inference results still hold.
However, when $p<m$, the Horvitz-Thompson estimator Equation 4 will be biased for the causal estimand. See Section 11.4 for more discussions. When $p<m$, the exact inference procedure as in Section 4.1 remains valid. For the asymptotic inference procedure, a similar result to Theorem 20 still holds when $m$ is misspecified, as we state in Corollary 21. The only difference is that when $p<m$, the asymptotic normal distribution will not be centered around the causal estimand as we defined in Equation 1, but some quantity that we will discuss in Section 11.4. The proof is deferred to Section 11.6 in the Appendix.
Corollary 21: Asymptotic Normality when $m$ is Misspecified
For any $n \geq 4 \in \mathbb{N}$, define an $n$-replica experiment such that there are $T = n p$ time periods.
Take the optimal design as in Theorem 14 whose randomization points are at $\mathbb{T}^* = {1, 2p+1, 3p+1, ..., (n-2)p+1}$.
We have the following two observations.
i When $p>m$, under Assumptions Assumption 2–Assumption 4, the variance of the Horvitz-Thompson estimator, $\mathsf{Var}(\widehat{\tau}_p)$, is explicitly given by Equation 10.
ii Furthermore, no matter if $p>m$ or $p<m$, under Assumptions Assumption 2–Assumption 11 and assume $\mathsf{Var}(\widehat{\tau}_p) \geq \Omega(n^{-1})$, the limiting distribution of the Horvitz-Thompson estimator in the $n$-replica experiment has an asymptotic normal distribution.
That is, as $n \to +\infty$,
$ \begin{align*} \frac{\widehat{\tau}_p - \mathbb{E}[\widehat{\tau}_p]}{\sqrt{\mathsf{Var}(\widehat{\tau}_p)}} \xrightarrow[]{D} \mathcal{N}(0, 1). \end{align*} $
Corollary 21, together with Theorem 20, is the key to identification of $m$, the order of the carryover effect. In Section 4.4 we provide a procedure to identify $m$.
4.4 Identifying the Order of the Carryover Effect
Using Theorem 20 and Corollary 21 we can define a hypothesis testing procedure, which, combined with a searching method, yields an estimate of the order of the carryover effect.
To build intuition, suppose we have access to two comparable experimental units. The two experimental units could be two separate units or two non-overlapping time epochs on one experimental unit such that the two epochs are far enough such that the carryover effect from one does not affect the outcomes of the other. Suppose, on the first experimental unit, we design an optimal experiment under $p=p_1$ and on the second unit, we use $p=p_2$; without loss of generality let $p_1 < p_2$.
After running the experiment and collecting the results, consider the following two statistics. For the first unit, we calculate $\widehat{\tau}{p_1}$, the sampling average, and $\widehat{\sigma}^2{p_1}$, the conservative sampling variance as suggested by Corollary 18. For the second unit, we calculate $\widehat{\tau}{p_2}$ and $\widehat{\sigma}^2{p_2}$.
Define a procedure that tests the following null hypothesis:
$ \begin{align} H_0: \ m \leq p_1 \end{align}\tag{12} $
Under the null hypothesis Equation 12, $\tau_{p_1} = \tau_{p_2} = \tau_m$, and so both $\widehat{\tau}{p_1}$ and $\widehat{\tau}{p_2}$ are unbiased estimators of $\tau_m$. Furthermore, given that the two estimators both conform asymptotic normal distributions, and that the two experimental units are independent, the difference between the two estimators should be an asymptotic normal distribution centered around zero, i.e., $(\widehat{\tau}{p_1} - \widehat{\tau}{p_2}) / \sqrt{\mathsf{Var}(\tau_{p_1}) + \mathsf{Var}(\tau_{p_2})} \xrightarrow[]{D} \mathcal{N}(0, 1)$. To test the null hypothesis Equation 12, define the test statistic to be $z = \left| \widehat{\tau}{p_1} - \widehat{\tau}{p_2} \right| / \sqrt{\widehat{\sigma}^2_{p_1} + \widehat{\sigma}^2_{p_2}}$. The estimated $p$-value is given by $\widehat{p} = 2 - 2 \Phi(z)$, where $\Phi$ is the CDF of a standard normal distribution.
The above procedure enables us to test the null hypothesis Equation 12. We can combine such a procedure with any searching method to identify $m$.
5. Simulation Study
Section Summary: This simulation study tests an optimal design for switchback experiments, which alternate treatments over time to account for lingering effects, against two simpler benchmarks to see which minimizes errors in estimating treatment impacts. Researchers ran extensive computer simulations using a basic model of outcomes influenced by past treatments, over 120 periods with two-period carryover, and found the optimal design had the lowest error risk in both worst-case scenarios and specific outcome patterns, confirming its theoretical advantages and unbiased estimates. Additional tests explored how well the method works over different time lengths, under model mismatches, and for detecting carryover duration through hypothesis testing.
There are five goals for this simulation study. First, to show that the optimal design in Theorem 14 has the smallest risk compared against two benchmarks. There are two dimensions for our comparison: the worst-case risk and the risk under a specific outcome model. Second, to verify the asymptotic normal distribution under a non-asymptotic setup, and to study the quality of the upper bound proposed in Corollary 18. Third, to understand the rejection rate and its dependence on the length of time horizon. Fourth, to study the performance of the optimal design under a misspecified $m$, and to compare the difference of the two inference methods proposed in Section 4. Fifth, to study the performance of the hypothesis testing procedure as proposed in Section 4.4, which identifies $m$ the length of the carryover effect.
We start with a simple linear additive carryover effect model which originates from [72, 73, 74].
$ \begin{align} Y_t(\bm{w}{1:t}) = \mu + \alpha_t + \delta^{(1)} w_t + \delta^{(2)} w{t-1} + ... + \delta^{(t)} w_1 + \epsilon_t \end{align}\tag{13} $
where $\mu$ is a fixed effect; $\alpha_t$ is a fixed effect associated to period $t$; $\delta^{(1)}, \delta^{(2)}, ..., \delta^{(t)}$ are non-stochastic coefficients; $w_t, w_{t-1}, ..., w_1$ are the treatment indicators; $\epsilon_t$ is the random noise in period $t$. We will run many simulations based on this model. For a more detailed discussion of the flexibility of the potential outcome framework, see Section 11.7 in the Appendix.
5.1 Comparison of the Risk Functions for Different Designs
5.1.1 Simulation setup.
We consider two setups. The first setup is for the worst-case risk. We consider $T=120$, $p=m=2$ where $m$ is correctly identified, and $Y_t(\bm{1}_3) = Y_t(\bm{0}_3) = 10$. We compare three different designs of switchback experiments. The first one is our proposed optimal design as in Theorem 14, such that $\mathbb{T}^*={1, 5, 7, ..., 117}$. The second one is the most common and naive switchback experiment, which independently assign treatment/control in every period with half-half probability. It is parameterized by $\mathbb{T}^\mathsf{H1}={1, 2, 3, ..., 120}$. The third one is the "intuitive" experiment discussed in Table 1, which divides the time horizon into several epochs each with length $m+1=3$. It is parameterized by $\mathbb{T}^\mathsf{H2}={1, 4, 7, ..., 118}$.
Second, we run simulations based on the outcome model as in Equation 13. Similar to the first setup, we consider again $T=120, p=m=2$ where $m$ is correctly identified. For the outcome model, we consider $\mu = 0$, $\alpha_t = \log{(t)}$, and $\epsilon_t \sim N(0, 1)$ are i.i.d. standard normal distributions. For any $t >3$, let $\delta^{(t)} = 0$. We will vary the values of $\delta^{(1)}, \delta^{(2)}, \delta^{(3)} \in {1, 2}$ and conduct experiments under $2^3=8$ different scenarios. Again we compare the same three different designs of switchback experiments. $\mathbb{T}^*={1, 5, 7, ..., 117}, \mathbb{T}^\mathsf{H1}={1, 2, 3, ..., 120}$, and $\mathbb{T}^\mathsf{H2}={1, 4, 7, ..., 118}$.
We simulate one assignment path at a time, and conduct an experiment following this assignment path. Since the outcome model is prescribed, we can calculate both the causal estimand and and the observed outcomes (along the simulated assignment path). Then, we calculate the Horvitz-Thompson estimator based on the simulated assignment path and the simulated observed outcomes. With both the estimand and estimator, we can calculate the loss function. We repeat the above procedure enough ($100000$) times to obtain an accurate approximation of the risk function.
5.1.2 Simulation results.
First, we calculate the worst-case risk functions via simulations. Notice that, when $p=m=2$, we could explicitly calculate the worst-case risk functions under the three different designs of switchback experiments $\mathbb{T}^*, \mathbb{T}^\mathsf{H1}$, and $\mathbb{T}^\mathsf{H2}$. Even though we can explicitly calculate them via the following expression (See Lemma 31 in the Appendix for details),
$ \begin{align} \frac{B^2}{(T-m)^2} \left{ 4 \sum_{k=1}^{K+1} (t_{k} - t_{k-1})^2 + 8 m (t_K - t_1) + 4 m^2 K - 4 m^2 + 4 \sum_{k=2}^{K} [(m-t_k+t_{k-1})^+]^2\right}, \end{align}\tag{14} $
we still use the simulation to confirm this result. See Table 2 for our simulation results.
The causal effect is $\tau_2 = 0$ because $Y_t(\bm{1}_3) = Y_t(\bm{0}_3) = 10$. The simulated estimator is $\mathbb{E}[\widehat{\tau}^*2] = -0.0291$ for our proposed optimal design, and $\mathbb{E}[\widehat{\tau}^\mathsf{H1}2] = 0.0104$ and $\mathbb{E}[\widehat{\tau}^\mathsf{H2}2] = -0.0478$ for the two benchmarks, respectively. The risk function is $r(\eta{\mathbb{T}^*}) = 26.78$ for our proposed optimal design, and $r(\eta{\mathbb{T}^\mathsf{H1}}) = 33.67$ and $r(\eta{\mathbb{T}^\mathsf{H1}}) = 27.85$ for the two benchmarks, respectively. Such simulation results suggest that our proposed optimal design have the smallest risk, under the worst case outcome model. In the last three columns are the risk functions of the three designs, all suggested by expression Equation 14. The risk functions calculated from theory take values that are very close to the risk functions calculated from expression Equation 14, which verifies our theory.
::: {caption="Table 2: Simulation results for the worst-case risk function."}

:::
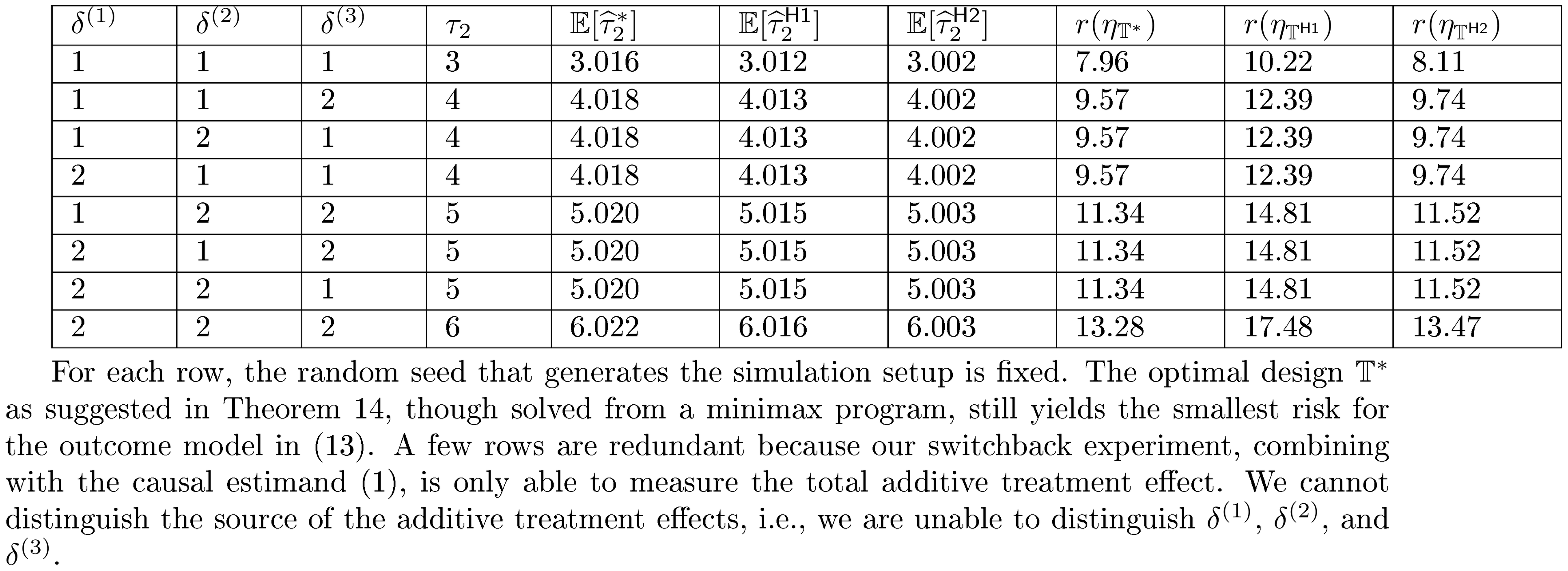
Second, we calculate the risk functions based on the outcome model in Equation 13. See Table 3. As we vary the values of $\delta^{(1)}$, $\delta^{(2)}$ and $\delta^{(3)}$, the average lag- $2$ causal effect is being changed. All three estimators are able to reflect the change as the estimand changes. The risk function can be simulated and we see that the risk function associated with the first benchmark $\mathbb{T}^\mathsf{H1}$ is $28% \sim 32%$ larger than the optimal design; and the second benchmark $\mathbb{T}^\mathsf{H2}$ is $1% \sim 2%$ larger. Such simulation results suggest again that our proposed optimal design have the smallest risk.
::: {caption="Table 3: Simulation results for the risk function based on the outcome model in Equation 13."}
:::
Moreover, as $r(\eta_{\mathbb{T}^\mathsf{H2}})$ is close to $r(\eta_{\mathbb{T}^*})$ and both are much smaller than $r(\eta_{\mathbb{T}^\mathsf{H1}})$, our results suggest that when $m$ is unknown, it is better to select $p$ to be slightly larger than the true $m$ as opposed to significantly smaller.
As the magnitude of treatment effects increase, the associated risk functions also increase. The relative difference between risk functions of $r(\eta_{\mathbb{T}^\mathsf{H1}})$ and $r(\eta_{\mathbb{T}^*})$ increases, while the relative difference between $r(\eta_{\mathbb{T}^\mathsf{H1}})$ and $r(\eta_{\mathbb{T}^*})$ decreases. This coincides with the intuitions discussed in Section 3.
5.2 Asymptotic Normality
5.2.1 Simulation setup.
We run simulations based on the outcome model in Equation 13, with $T=120$ and $m=2$. We will consider three cases: (i) $m$ is correctly specified so $p=2$; (ii) $p=3$, and we estimate lag- $3$ causal estimand as in Equation 1; (iii) $p=1$, and we pretend as if we estimated the lag- $1$ causal estimand. However, as the lag- $1$ causal estimand is not well defined, we instead estimate a different quantity, which we refer to as the " $m$-misspecified lag- $p$ causal estimand" (See details and definition in Equation 24).
For the outcome model, we consider $\mu = 0$, $\alpha_t = \log{(t)}$, and $\epsilon_t \sim N(0, 1)$ are i.i.d. standard normal distributions. For any $t >3$, let $\delta^{(t)} = 0$. For simplicity, let $\delta^{(1)} = \delta^{(2)} = \delta^{(3)} = \delta$. We vary $\delta \in {1, 2, 3}$ and conduct experiments under $3$ different scenarios. We simulate one assignment path at a time, and conduct experiments following this assignment path. Since the outcome model is prescribed, we calculate the observed outcomes based on the simulated assignment path. Then we calculate the Horvitz-Thompson estimator, and the conservative estimator of the randomization variance (Corollary 18), based on the simulated assignment path and the simulated observed outcomes. On the other hand, the lag- $p$ causal estimand is easy to calculate once the outcome model is prescribed. Yet the $m$-misspecified lag- $p$ causal estimand has to be calculated in conjunction with the simulated assignment path. By repeating the above procedure enough ($100000$) times we obtain a distribution of the estimator.
5.2.2 Simulation results.
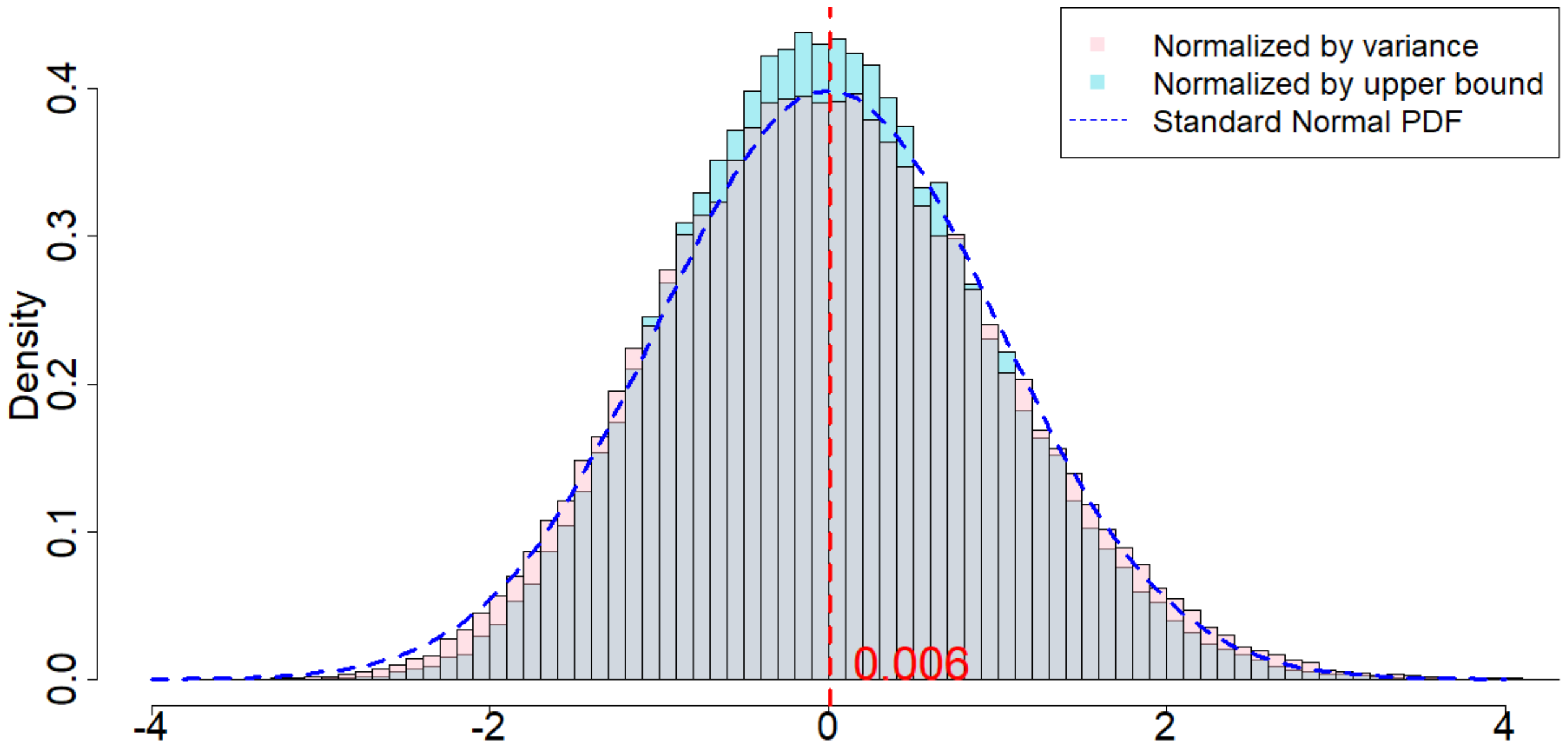
In Figure 4, the dotted dark blue line is the Probability Density Function of the standard normal distribution. The pink histogram corresponds to the distribution induced by $\frac{\widehat{\tau}_p - \tau_p}{\sqrt{\mathsf{Var}(\widehat{\tau}_p)}}$, which is the estimator (after re-centering at zero) normalized by the square root of the true randomization variance[^5]. Such a distribution, as suggested by Theorem 20, converges to a standard normal distribution when $T$ is large. Comparing to the dotted dark blue line, Figure 4 suggests that Theorem 20 approximately holds for moderate values of $T$. The light blue histogram corresponds to the distribution induced by $\frac{\widehat{\tau}p - \tau_p}{\sqrt{\mathbb{E}[\widehat{\sigma}^2{U}]}}$, which is the estimator (after re-centering at zero) normalized by the expectation of the conservative upper bound of the randomization variance. Since we replace the true variance by the conservative upper bound, the shape of the distribution is more concentrated around zero, as we see from the "taller" histogram. The red vertical line is the expected value of the randomization distribution for the pink histogram. The cases of $\delta=1$ and $\delta=2$ are similar, and the cases of overestimated $m$ and underestimated $m$ are also similar. We discuss them in Section 11.9 in the Appendix.
[^5]: We numerically find such variance $\mathsf{Var}(\widehat{\tau}p)$, and the expectation of the conservative upper bound $\mathbb{E}[\widehat{\sigma}^2{U}]$
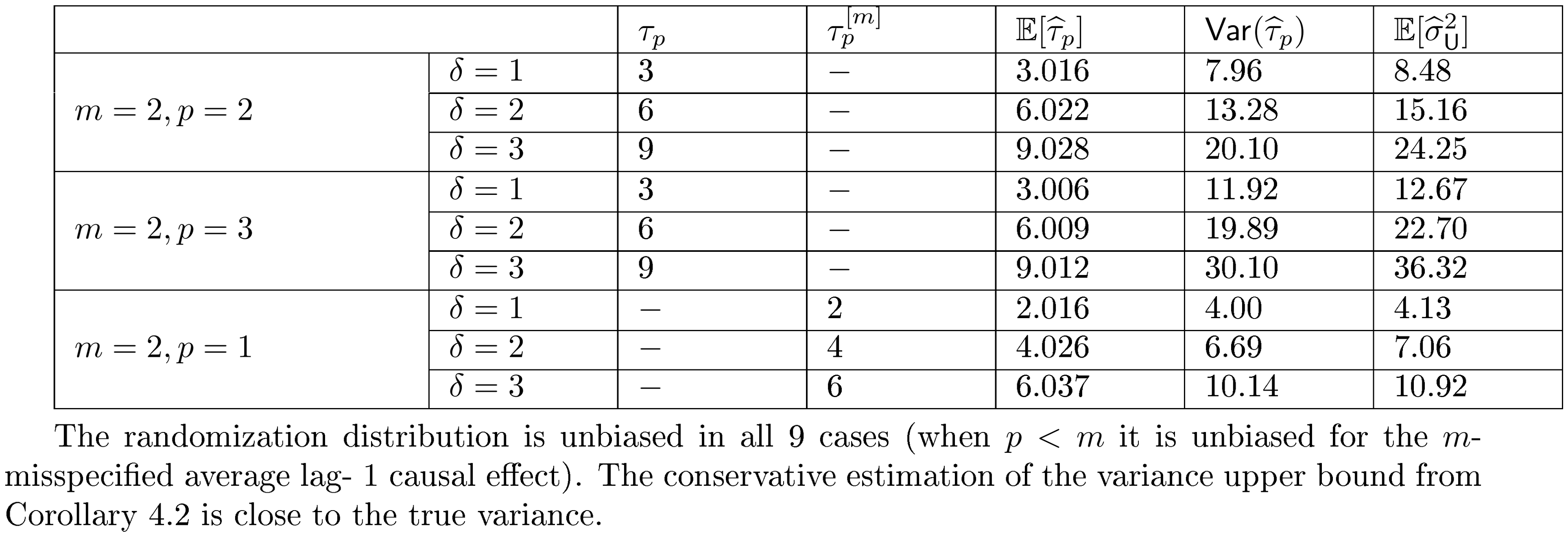
For all the nine cases ($p \in {1, 2, 3}$ and $\delta\in{1, 2, 3}$), see Table 4 for the expected values and the variances of the randomization distributions, as well as the conservative estimator of the randomization variances. Note that the three cases all have the same underlying outcome model. It is the different knowledge of $m$ that leads to three different designs of experiments.
::: {caption="Table 4: Simulation results for the randomization distribution."}
:::
From Table 4, we make the following two observations. (i) Unbiasedness of the Horvitz-Thompson estimator. When $m$ is correctly specified, $\mathbb{R}[\widehat{\tau}_p]$ is very close to $\tau_p$, verifying the unbiasedness of the estimator. When $m=2, p=3$, the estimand remains unchanged, and the estimator remains unbiased. But the variance of the estimator is larger. When $m=2, p=1$, the estimand is the $m$-misspecified estimand, and the estimator is unbiased for this $m$-misspecified estimand. (ii) Quality of Corollary 18 and Corollary 21. As we increase $\delta$, the variances of the randomization distributions also increase. The conservative estimators of the randomization variances are very close to the true variances, which suggests that Corollary 18 and Corollary 21 approximate the true variances quite well.
5.2.3 Robustness Check.
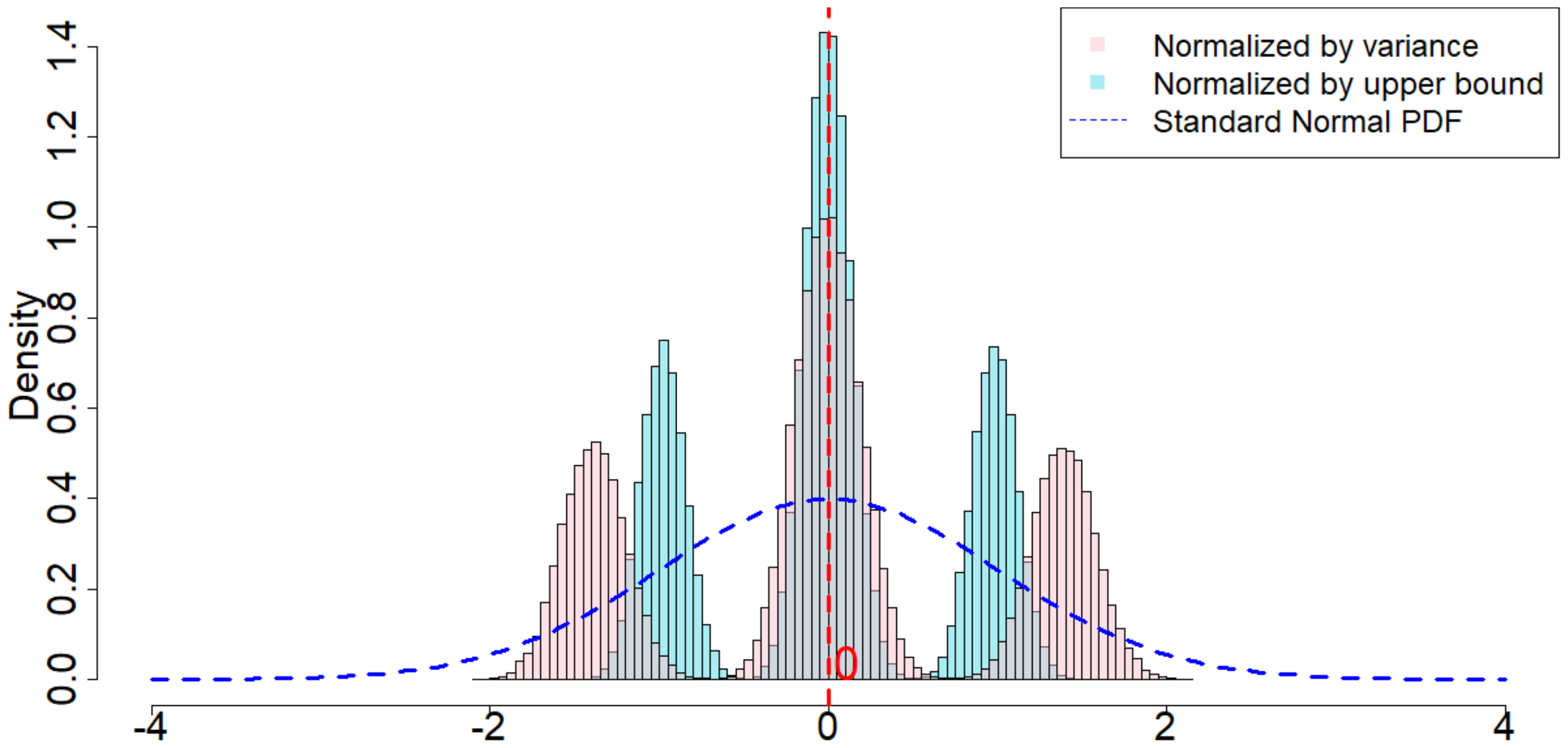
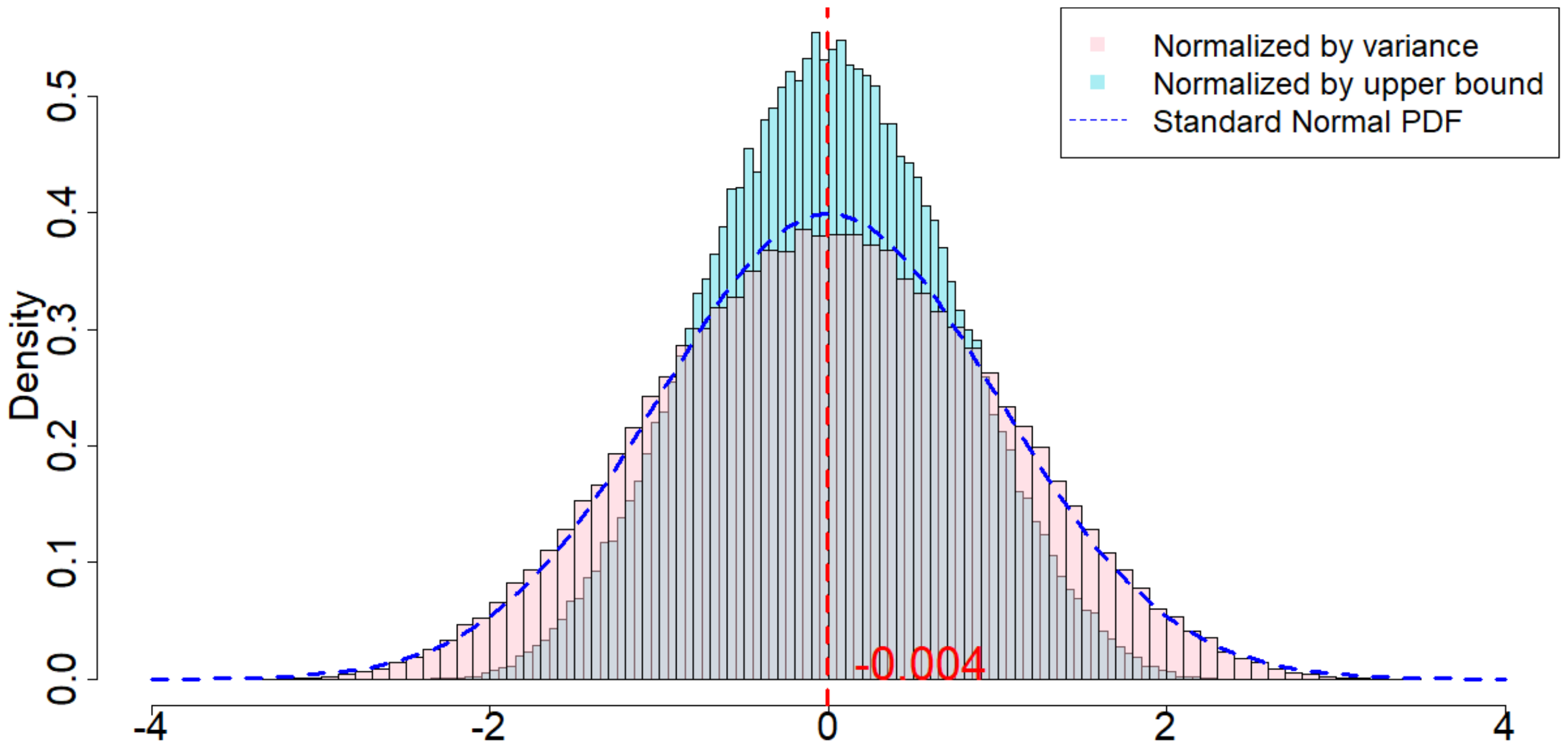
In this section we run simulations under almost the same setup as introduced in Section 5.2.1, with the only difference that we select each $\epsilon_t$ to be an i.i.d. Student's t-distribution with 1 degree of freedom. The purpose of this section is to verify our theory when $\epsilon_t$ are drawn from heavy tailed distributions.
When $m=2, p=2, \delta=1$, as we can see from Figure 5, the randomization distribution is significantly different from a standard normal distribution. This is because $T=120$ is too small. Alternatively, we increase $T=1200$ to see that the randomization distribution behaves like a normal distribution. In other words, when $\epsilon_t$ noises are heavy tailed, our Theorem 20 has a slower convergence rate to a normal distribution. We conduct extensive simulation study under other parameters, as we will show in Section 11.9 in the Appendix.
5.3 Rejection Rates
5.3.1 Simulation setup.
We run simulations based on the outcome model as in Equation 13. We vary $T \in {120, 240, ..., 1200}$. We consider $p=m=2$ where $m$ is correctly specified. Similar to Section 5.2, we consider the same parameterization and conduct experiments under $3$ different scenarios $\delta \in {1, 2, 3}$.
We simulate one assignment path at a time, and conduct experiments following this assignment path. We first calculate the observed outcomes and the Horvitz-Thompson estimator. Then we conduct the two inference methods as proposed in Section 4, and obtain two estimated $p$-values. For the asymptotic inference method, we plug in $\widehat{\sigma}^2_{\mathsf{U}}$, the conservative upper bound of the variance. We reject the corresponding null hypothesis when the $p$-value is smaller than $0.1$ (In Section 11.10 we run additional simulations by replacing such $0.1$ threshold by $0.05$ and $0.01$). By repeating the above procedure enough (in this simulation, 1000) times we obtain the frequency of a null hypothesis being rejected, which we refer to as the rejection rate.
5.3.2 Simulation Results.
We calculate the rejection rates via simulations and then plot Figure 7. The blue dots are rejection rates under exact inference; the red dots are under asymptotic inference. In all the simulations, $\delta \ne 0, \tau_p \ne 0$. So, ideally, we would wish to reject both the Fisher's null hypothesis Equation 8 and the Neyman's null hypothesis Equation 9.
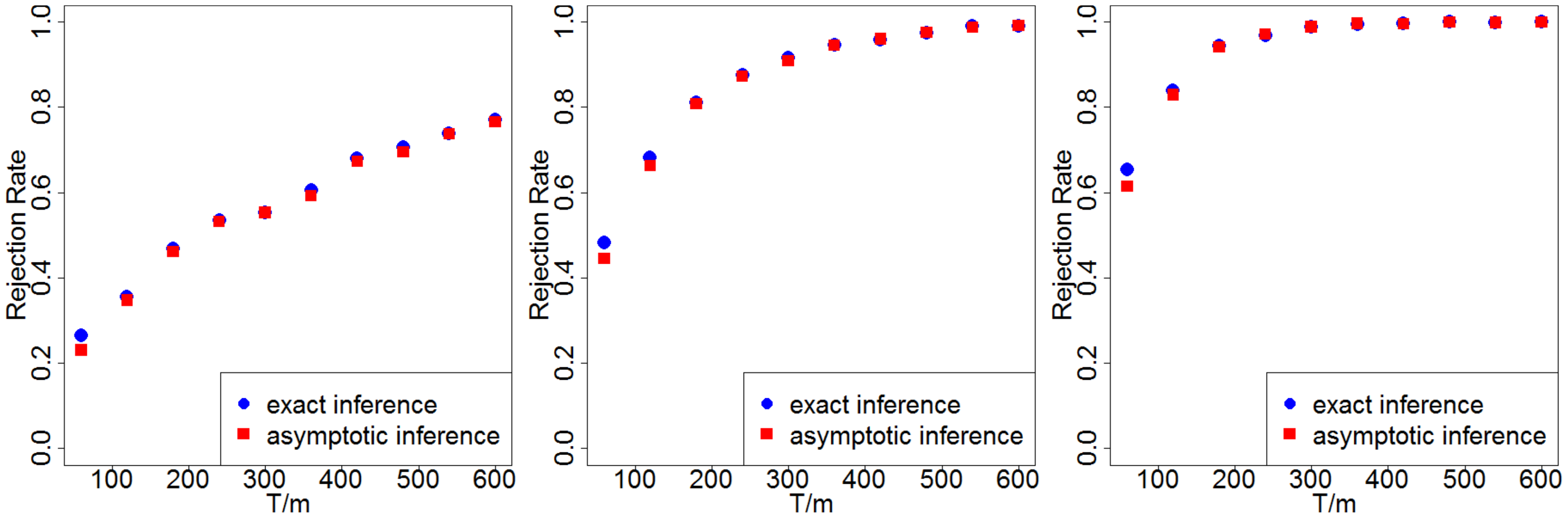
From Figure 7 we make the following three observations. (i) Dependence on $T/m$. The rejection rates increase as the length of the horizon increases – more specifically, as $T/m$ the total number of epochs increases. In practice, when firms have to capability to choose the length of $T$, they can refer to Figure 7 to choose $T$ properly. Also see discussion in Section 6. (ii) Between two inference methods. In all three cases, the rejection rate from testing a sharp null hypothesis Equation 8 is slightly higher than that from testing the Neyman's null Equation 9. This coincides with our intuition that a sharp null is more likely to be rejected. We discuss this in Section 5.5.2 together with the associated $p$-values. (iii) Dependence on the signal-to-noise ratio. The rejection rates all increase as $\delta$ increases from 1 to 3 (while holding the noise from the model fixed). This suggests that when the treatment effect is relatively larger, we do not require a long experimental horizon to achieve a desired rejection rate.
5.4 Comparison of the Type I and Type II Errors for Different Designs
5.4.1 Simulation setup.
We run simulations based on the outcome model as in Equation 13. We vary $T \in {120, 240, ..., 1200}$. We consider $p=m=2$ where $m$ is correctly specified. Similar to Section 5.2, we consider the same parameterization and conduct experiments under $3$ different scenarios $\delta \in {1, 2, 3}$. We compare three designs of experiments as described in Section 5.1: the optimal design $\mathbb{T}^*={1, 5, 7, ..., 117}$, which we refer to as Optimal Design as in Figure 8; the most commonly adopted heuristic $\mathbb{T}^\mathsf{H1}={1, 2, 3, ..., 120}$, which we refer to as Heuristic Design H1; and the so-called intuitive design $\mathbb{T}^\mathsf{H2}={1, 4, 7, ..., 118}$, which we refer to as Heuristic Design H2.
In this simulation, we first calculate the frequency of rejecting the Fisher's null hypothesis as in Equation 8 out of a total of 1000 repetitions. And then, we use the frequency to calculate the Type I and Type II errors. Type I error is the probability of rejecting the null hypothesis when there is no treatment effect, which we simulate the frequency of rejection using $\delta=0$ when there is no treatment effect. Type II error is the probability of not rejecting the null hypothesis when there is a treatment effect, which we simulate as $1$ minus the frequency of rejection using $\delta\in{1, 2, 3}$ when there is a non-negligible treatment effect.
5.4.2 Simulation results.
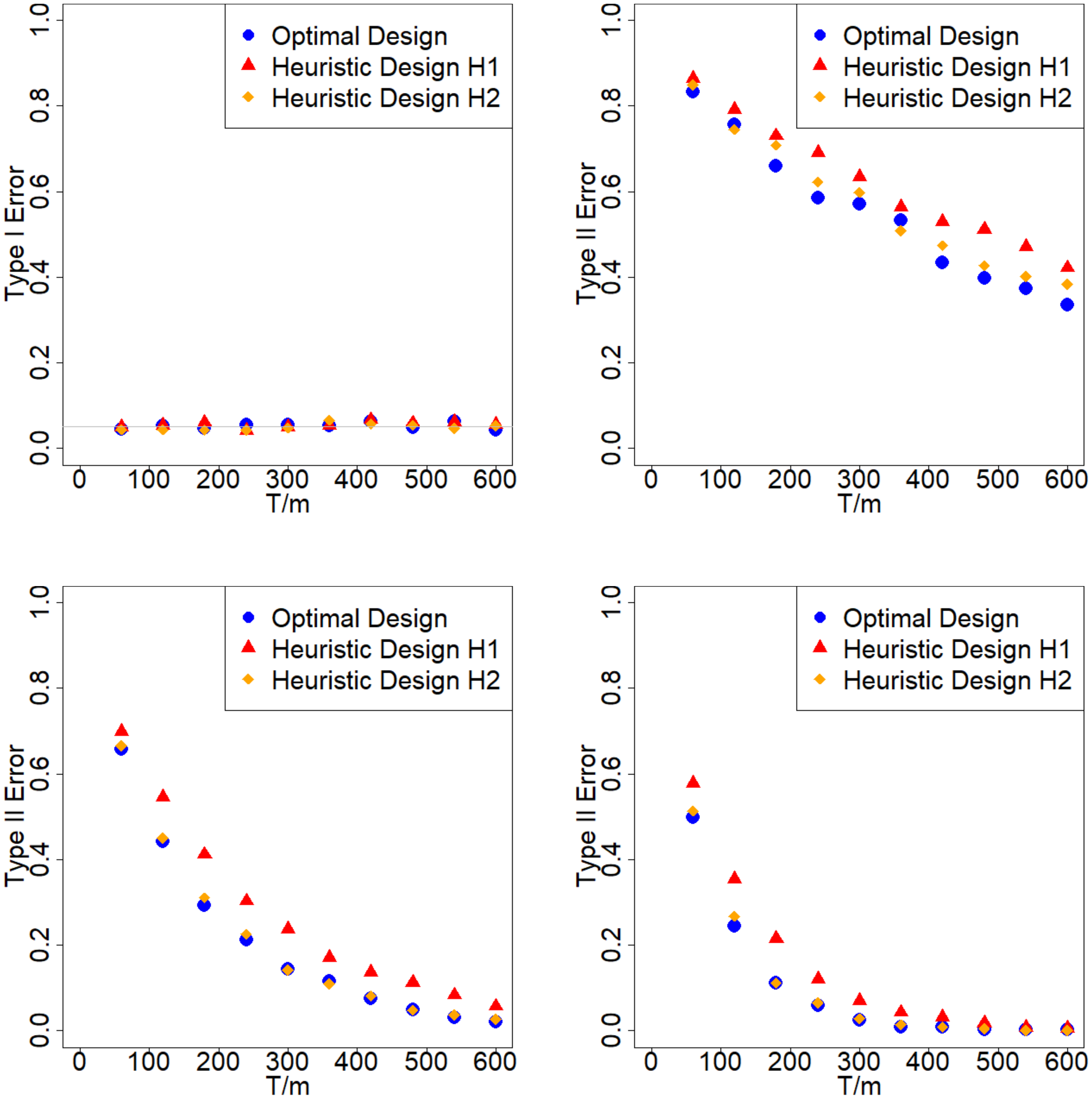
The simulation results are summarized in Figure 8. The blue dots are the Type I and Type II errors of the optimal design; the red dots are the Type I and Type II errors of the heuristic design $H1$; the yellow dots are the Type I and Type II errors of the heuristic design $H2$. The figure on the top-left corner reports the Type I error generated from $\delta=0$. The grey horizontal line in the top-left figure represents the $0.05$ nominal level. The other figures report the Type II errors generated from $\delta\in{1, 2, 3}$.
From Figure 8 we make the following observations. First, for Type I error, all the three designs have similar performance — all are very close to the $0.05$ nominal level. Second, the optimal design almost always has the smallest Type II error. This suggests that, even though we design our optimal experiment under the minimax criterion, the optimal design derived from this criterion outperforms the two heuristic benchmarks with respect to the Type II error. The Type II error becomes smaller when $T/m$, the effective experimental periods, increases. The gaps between the optimal design and the two heuristic designs also become smaller when $T/m$ increases.
5.5 Estimation under a Misspecified $m$
5.5.1 Simulation setup.
We run simulations whose setup are similar to Section 5.2.1; the only difference is that we only simulate one assignment path in this Section, and conduct hypothesis testing for this single run of the experiment.
The outcome model we consider is in Equation 13, and we consider the same parameterization as in Section 5.2.1, and conduct experiments under $3$ different scenarios $\delta \in {1, 2, 3}$. We consider three cases: (i) $m$ correctly specified so $p=2$; (ii) $p=3$, and we estimate the lag- $3$ causal estimand as in Equation 1; (iii) $p=1$, and we pretend as if we estimated the lag- $1$ causal estimand. However, the lag- $1$ causal estimand is not well defined. Instead, we estimate the $2$-misspecified lag- $1$ causal estimand as in Equation 24.
We only simulate one assignment path. Since the outcome model is prescribed, we calculate the observed outcomes. There is only one time series of such observed outcomes. We calculate the Horvitz-Thompson estimator based on the simulated assignment path and the simulated observed outcomes. We calculate the lag- $p$ causal estimand directly, and also the $m$-misspecified lag- $p$ causal estimand in conjunction with the simulated assignment path. Finally, we perform the two inference methods from Section 4, and report their associated estimated $p$-values. For the asymptotic inference method we plug in $\widehat{\sigma}^2_{\mathsf{U}}$ the conservative upper bound of the variance. We choose $I=100000$ to be the number of samples drawn in the exact inference method as shown in Algorithm 1.
5.5.2 Simulation results.
Notice this is only one experiment under one simulated experimental setup from one simulated assignment path. So the estimators $\widehat{\tau}_p$ we derive are different from $\tau_p$ (or $\tau_p^{(m)}$, which stands for the treatment effect when $m$ is misspecified; see Section 11.4 in the Appendix for more details). But they still follow the true causal effects which they estimate. See Table 5.
::: {caption="Table 5: Simulation results for correctly specified $m$ case, and two misspecified $m$ cases."}
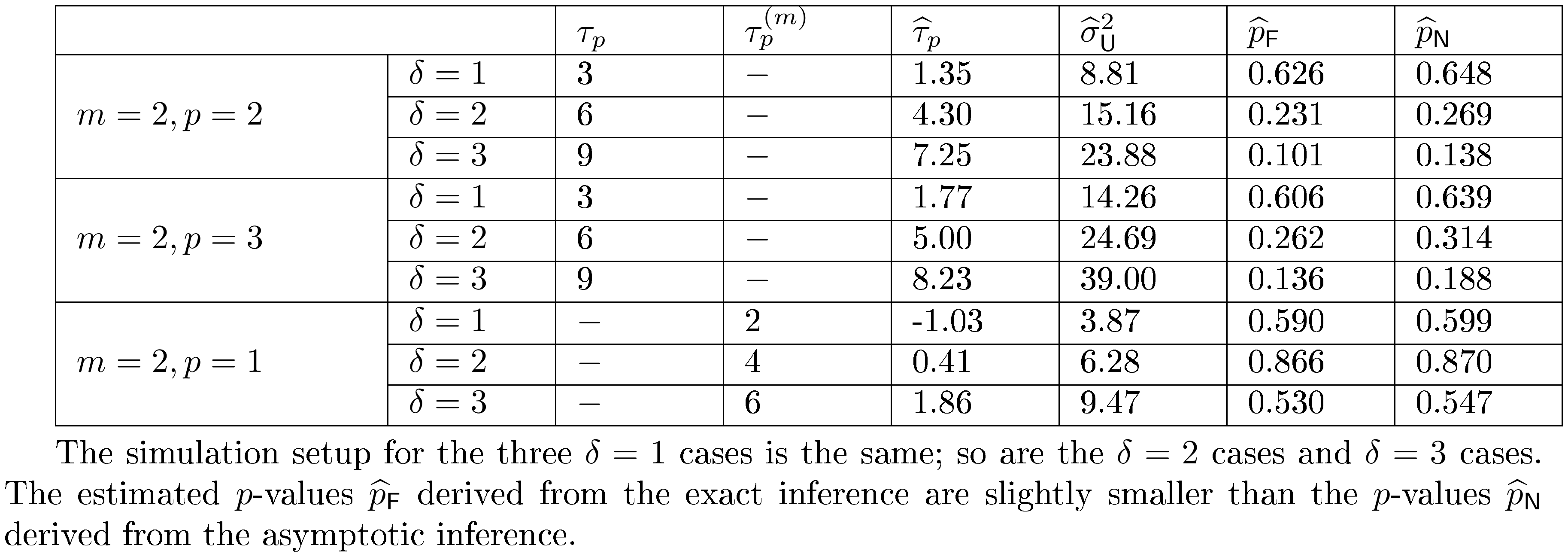
:::
From Table 5 we see that both our estimator and the estimated variance are well defined in all the cases when $p=m$, $p>m$, and $p<m$. In each case, as $\delta$ increases from 1 to 3, the associated $p$-values exhibit decreasing trends, suggesting a stronger rejection rate against the null hypothesis. Moreover, the $p$-values suggested by the exact inference are always slightly smaller than the $p$-values suggested by the asymptotic inference. This coincides with our intuition that: (i) the exact inference method possesses a stronger null hypothesis Equation 8 which implies the null hypothesis of Equation 9; (ii) in the asymptotic inference we replaced the true randomization variance by its conservative upper bound, which further leads to a larger $p$-value.
5.6 Estimation of $m$
We run simulations based on the outcome model as in Equation 13, to test the performance of the procedure described in Section 4.4. In this section we only focus on $\delta = 3$. Suppose we have narrowed down the range of the order of the carryover effect to be $m \leq 3$. In the first round, we use our procedure to test a null hypothesis $m \leq 2$. Then we would observe row 3 and 6 from Table 5, with $\widehat{\tau}2 = 7.25, \widehat{\sigma}^2{2} = 23.88; \widehat{\tau}3 = 8.23, \widehat{\sigma}^2{3} = 39.00$. So the estimated $p$-value for the null hypothesis $m \leq 2$ is estimated to be $\widehat{p} = 0.902$, which is too large to reject the null hypothesis. In the second round, we consult the procedure to test a null hypothesis $m \leq 1$. Then we would observe row 3 and 9 from Table 5, with $\widehat{\tau}1 = 1.86, \widehat{\sigma}^2{3} = 9.47; \widehat{\tau}2 = 7.25, \widehat{\sigma}^2{2} = 23.88$. The estimated $p$-value for the null hypothesis $m \leq 1$ is estimated to be $\widehat{p} = 0.350$. This is still rather large, yet a significant difference from $0.902$.
We conduct a few more numerical simulations with different time periods. The setup is the same as in Section 5.5, except that $T$ takes values in $T \in {210, 1020, 2010}$ [^6]. When $T=210$, in the first round the estimated $p$-value for the null hypothesis $m \leq 2$ is estimated to be $\widehat{p} = 0.956$; in the second round the estimated $p$-value for the null hypothesis $m \leq 1$ is estimated to be $\widehat{p} = 0.182$. When $T=1020$, in the first round the estimated $p$-value for the null hypothesis $m \leq 2$ is estimated to be $\widehat{p} = 0.869$; in the second round the estimated $p$-value for the null hypothesis $m \leq 1$ is estimated to be $\widehat{p} = 0.163$. When $T=2010$, in the first round the estimated $p$-value for the null hypothesis $m \leq 2$ is estimated to be $\widehat{p} = 0.760$; in the second round the estimated $p$-value for the null hypothesis $m \leq 1$ is estimated to be $\widehat{p} = 0.037$. In practice, we suggest increasing the horizon's length to a degree such that $T/p > 100$.
[^6]: The values of $T$ were selected such that they were both divisible by both 2 and 3, the possible values of the carryover effect.
6. Practical Implications, Limitations, and Concluding Remarks
Section Summary: When companies run switchback experiments to test new products, they need to carefully choose metrics that show the change's impact, set short time periods to avoid losing data accuracy due to lingering effects from the old setup, estimate how long those effects last to plan the experiment's length and structure, and randomize the switch points optimally for reliable results. After collecting data, firms can draw conclusions about the innovation's value, and running the design across multiple test groups boosts precision and reliability. However, the approach struggles with very long-lasting effects relative to the test duration, sticks to fixed randomization instead of adjusting on the fly, and focuses only on deciding permanent policy changes rather than other goals.
When a firm decides to use a switchback experiment to evaluate a new product or initiative, they have to make multiple decisions to ensure that the results are reliable, practical, and replicable. First, the firm must determine an appropriate outcome(s) that adequately captures the relative effectiveness of the change. In practice, this requires substantive domain knowledge combined with an understanding of the likely impact of the change; see [13] for an in-depth discussion of metric definition strategies.
Second, as part of the design of the experiment, the firm often has control over the granularity of one single experimental period. As we have shown in Example Section 3, as long as each time period is smaller than the length of the carryover effect and the length of the carryover effect is divisible by the length of one time unit, the selection of granularity makes no difference to the optimal design and analysis of switchback experiments. On the other hand, setting each period's length longer than the carryover effect will lead to a loss in precisions. Consider an extreme case where the carryover effect is 1 minute, while each period is selected to be an hour. Had we set each period to be a minute, we would have collected order of magnitude more useful data. Hence, we suggest that each period's length be smaller than the carryover effect duration.
Third, the firm must use prior knowledge to decide an appropriate value $p$ for the order of the carryover effect $m$. When a firm lacks such knowledge, we propose using the procedure outline in Section 4.4 to select an appropriate value of the order of the carryover effect. Practically, researchers should try to narrow down the set of possible values of $m$ as, when $m$ is relatively large compared to $T$, our procedure could fail to reject the null hypothesis simply due to insufficient statistical power. Also, it is important to keep in mind that each hypothesis test to identify Equation 12 needs to consume experimental resources at the scale of $T/m > 100$ to distinguish two candidate values, which could be over burdensome when the resource is scarce.
Fourth, when the firm has control over the experiment's horizon, the firm should set $p=m$ and control the overall duration of the experiment $n = T/p = T/m$. We suggest choosing $n$ by referring to the rejection rate curve, as shown in Section 5.3; intuitively, this procedure resembles a typical power analysis. We begin with selecting our inference method, as described in Section 4. We then use our domain knowledge to estimate the expected signal-to-noise ratio; this could be done by looking at historical experiments or through dummy experiments. Then, we choose the desired rejection rate and find out the length of the horizon required.
Finally, using the previous four points, the firm decides the randomization points and samples the assignment path from the appropriate randomization distribution. This final step has already been discussed at length, as we showed in Section 3 the optimal design is obtained from Theorem 13 and Theorem 14. In cases when the time horizon is pre-determined and when $T/p$ is not an integer, our optimization formulation as shown in Theorem 14 can always be used to find an optimal solution without discarding any periods. Just in the "imperfect cases, " we do not have closed-form solutions. Our suggestion is that if the experimental designer wishes not to discard any periods, then solve the optimal solution (using any commercial software); if the experimental designer wishes not to solve an optimization problem, then discard a few periods and consult the explicit solution suggested in Theorem 14.
After designing the experiment, the firm can use the data collected from the test to draw causal conclusions about the new innovation's performance using the two inferential methods as discussed in Section 4. As a more practical consideration, when the firm have the capability to run multiple experiments on multiple experimental units, we suggest the firm to run the optimal design on each of the experimental units and then combine them to increase both precision and power. See [34] for detailed discussions.
We point out three limitations of our paper. First, when $m$, the order of the carryover effect is as large as comparable to $T$ the horizon's length, our method, though still unbiased in theory, incurs a large variance that typically prohibits the firm from making meaningful inference. This is because our method is general and requires the minimum amount of modeling assumptions. If we have strong domain knowledge about the outcome model, we can incorporate it to improve the design. Second, our method only considers flipping independent coins before the experiment even begins. We do not consider adaptively changing the coin flip probabilities, as it requires further assumptions about the outcome model, e.g., some time-homogeneity of the data generating process. Third, in this paper, we have only considered the estimand as in Equation 1, which is motivated when firms want to decide whether to permanently adopt a policy. If the primary focus is on some other general causal estimands, our results do not directly apply. It remains open to derive new results for other estimands, using a similar strategy that we have employed.
Acknowledgment
Section Summary: The authors express gratitude to department editor George Shanthikumar, an anonymous associate editor, and three anonymous referees for their helpful comments that enhanced the manuscript. They also acknowledge the support provided by the MIT-IBM partnership in AI and the MIT Data Science Laboratory.
The authors thank the department editor George Shanthikumar, the anonymous associate editor, and three anonymous referees whose comments improved the manuscript. The authors also thank the MIT-IBM partnership in AI and the MIT Data Science Laboratory for support.
7. E-Companion
Section Summary: This section of the paper outlines the basic mathematical notations used throughout the document to keep things clear and consistent. It defines common sets, such as positive integers, non-negative integers, and ranges of numbers up to a certain value or between two points. Additionally, it explains symbols for vectors of all ones or zeros, probability (in parentheses), expected values (in brackets), indicators (in curly braces), and the positive part of a number, which is the maximum between that number and zero.
Within this paper, let $\mathbb{N}, \mathbb{N}0$ be the set of positive integers and non-negative integers, respectively. For any $T \in \mathbb{N}$, let $[T] = {1, ..., T}$ be the set of positive integers no larger than $T$. For any $t < t' \in \mathbb{N}$, let ${t:t'} = {t, t+1, ..., t'}$ be the set of integers between (including) $t$ and $t'$. For any $m \in \mathbb{N}$, let $\bm{1}{m} = (1, 1, ..., 1)$ be a vector of $m$ ones; let $\bm{0}_{m} = (0, 0, ..., 0)$ be a vector of $m$ zeros. We use parentheses for probabilities, i.e., $\Pr(\cdot)$; brackets for expectations, i.e., $\mathbb{E}[\cdot]$; and curly brackets for indicators, i.e., $\mathbf{1}{\cdot}$. For any $a \in \mathbb{R}$, let $(a)^+ = \max{a, 0}$.
8. Theorems Used
Section Summary: This section outlines key mathematical tools used in the paper's proofs, starting with a definition of φ-dependent random variables, which describes sequences where distant groups of variables are statistically independent if separated by more than a fixed gap φ. It then presents Lemma 23, a theorem showing that under specific conditions on variance and moments, sums of such zero-mean variables in a triangular array converge in distribution to a standard normal distribution, enabling probabilistic approximations. Finally, Lemma 24 proves that for any n probabilities between 0 and 1, the sum of the reciprocals of their product and the product of their complements is at least 2 raised to the power of n+1, with equality only when all probabilities are exactly 1/2, demonstrated through an elegant expansion and pairing of terms.
We summarize here the results that we have directly used in our proofs.
Definition 22: $\phi$-Dependent Random Variables, [75]
For any sequence ${X_1, X_2, ...}$, if there exists $\phi$ such that for any $s-r > \phi$, the two sets
$ (X_1, X_2, ..., X_r), \quad (X_s, X_{s+1}, ..., X_n) $
are independent, then the sequence is said to be $\phi$-dependent.
Lemma 23: [76], Theorem 2.1
Let $\left{X_{n, i}\right}$ be a triangular array of zero-mean random variables.
Let $\phi \in \mathbb{N}$ be a fixed constant.
For each $n=1, 2, ...$, let $d=d_n$, and suppose that $X_{n, 1}, X_{n, 2}, ..., X_{n, d}$ is an $\phi$-dependent sequence of random variables. Define
$ \begin{align*} B^2_{n, k, a} = \mathsf{Var}\left(\sum_{i=a}^{a+k-1} X_{n, i} \right), & & B^2_n = B^2_{n, d, 1} = \mathsf{Var}\left(\sum_{i=1}^{d} X_{n, i} \right) \end{align*} $
For some $\delta>0$ and $-1 \leq \gamma \leq 1$, if the following conditions hold:
- $\mathbb{E}\left| X_{n, i} \right|^{2+\delta} \leq \Delta_n$, for all $i$;
- $B^2_{n, k, a}/k^{1+\gamma} \leq K_n$, for all $a$ and $k \geq \phi$;
- $B^2_n / (d \phi^\gamma) \geq L_n$;
- $K_n / L_n = O(1)$;
- $\Delta / L_n^{(2+\delta)/2} = O(1)$,
then
$ \begin{align*} \frac{\sum_{i=1}^d X_{n, i}}{B_n} \xrightarrow{D} \mathcal{N}(0, 1). \end{align*} $
We explain Lemma 23. The $\xrightarrow{D}$ notation stands for convergence in distribution. The definition of a sequence of $\phi$-dependent random variables is given in Definition 22. To check if the conditions in Lemma 23 hold, we will first calculate $B^2_{n, k, a}$ for any $k$ and $a$, and then construct some proper $\Delta_n, K_n, $ and $L_n$.
Lemma 24
For any $n \in \mathbb{N}$ and $q_1, ..., q_n \in (0, 1)$, define
$ f(q_1, ..., q_n) = \frac{1}{\prod_{i=1}^n q_i} + \frac{1}{\prod_{i=1}^n (1-q_i)}. $
Then
$ f(q_1, ..., q_n) \geq 2^{n+1}, $
where equality holds if and only if $q_1=q_2=...=q_n=1/2$.
The proof of Lemma 24 is elegant and is of its own interests. We prove Lemma 24 below.
Proof of Lemma 24.: For all $i\in[n]$ denote $\bar{q}_i = 1-q_i$. We re-write our objective, such that we wish to find the minimum for
$ \frac{1}{\prod_{i=1}^n q_i} + \frac{1}{\prod_{i=1}^n \bar{q}_i}, $
under the constraints that $q_i+ \bar{q}i=1$ for all $i\in[n]$. Note that $\prod{i=1}^n (q_i+ \bar{q}_i) = 1$. By expanding expand the product term and we have
$ \begin{align*} \frac{1}{\prod_{i=1}^n q_i} = \frac{\prod_{i=1}^n (q_i+ \bar{q}i)}{\prod{i=1}^n q_i} = 1 + \left(\frac{\bar{q}_1}{q_1} + \frac{\bar{q}_2}{q_2} + \ldots + \frac{\bar{q}_n}{q_n} \right) + \left(\frac{\bar{q}_1 \bar{q}_2}{q_1q_2} + \frac{\bar{q}1 \bar{q}3}{q_1q_3} + \ldots + \frac{\bar{q}{n-1}\bar{q}n}{q{n-1}q_n} \right) + \ldots + \frac{\prod{i=1}^n \bar{q}i}{\prod{i=1}^n q_i} \end{align*} $
And similarly we can expand the product term for the second fractional expression. Putting them together we have:
$ \begin{align*} \frac{1}{\prod_{i=1}^n q_i} + \frac{1}{\prod_{i=1}^n \bar{q}_i} = & 1 + \left(\frac{\bar{q}_1}{q_1} + \frac{\bar{q}_2}{q_2} + \ldots + \frac{\bar{q}_n}{q_n} \right) + \left(\frac{\bar{q}_1 \bar{q}_2}{q_1q_2} + \frac{\bar{q}1 \bar{q}3}{q_1q_3} + \ldots + \frac{\bar{q}{n-1}\bar{q}n}{q{n-1}q_n} \right) + \ldots + \frac{\prod{i=1}^n \bar{q}i}{\prod{i=1}^n q_i} \ & \ + 1 + \left(\frac{q_1}{\bar{q}_1} + \frac{q_2}{\bar{q}_2} + \ldots + \frac{q_n}{\bar{q}_n} \right) + \left(\frac{q_1q_2}{\bar{q}_1 \bar{q}2} + \frac{q_1q_3}{\bar{q}1 \bar{q}3} + \ldots + \frac{q{n-1}q_n}{\bar{q}{n-1}\bar{q}n} \right) + \ldots + \frac{\prod{i=1}^n q_i}{\prod{i=1}^n \bar{q}_i} \end{align*} $
Now focus on the right hand side. There are a total of $2^{n+1}$ terms, and we match them into $2^n$ pairs. We match the first term in the first line with the first term in the second line, the second term in the first line with the second term in the second line, ..., the last term in the first line with the last term in the second line. For each pair indexed by subset $I \subseteq [T]$, we have that
$ \frac{\prod_{i \in I \subseteq [T]} \bar{q}i}{\prod{i \in I \subseteq [T]} q_i} + \frac{\prod_{i \in I \subseteq [T]} q_i}{\prod_{i \in I \subseteq [T]} \bar{q}_i} \geq 2, $
where equality holds if and only if $\prod_{i \in I \subseteq [T]} q_i = \prod_{i \in I \subseteq [T]} \bar{q}_i$. Putting all the $2^n$ pairs together we finish the proof. $\square$
9. Proof from Section 2
Section Summary: This section proves the unbiasedness of the Horvitz-Thompson estimator in switchback experiments by examining expectations. It shows that in these setups, there's a realistic chance of observing either full treatment or full control across a time window, and when you weight the observed outcomes by the inverse of these probabilities, the expected results exactly match the true effects under full treatment or control. Adding these weighted expectations together completes the proof for any relevant time period.
The only proof from Section 2 is the unbiasedness of the Horvitz-Thompson estimator. We prove by checking the expectations.
Proof of Proposition 9.: First observe that for regular switchback experiments, both $0 < \Pr(\bm{W}{t-p:t} = \bm{1}{p+1}), \Pr(\bm{W}{t-p:t} = \bm{0}{p+1}) < 1$. So for any $t \in {p+1:T}$, with probability $\Pr(\bm{W}{t-p:t} = \bm{1}{p+1}) \ne 0$, $\mathbf{1}{{\bm{W}{t-p:t} = \bm{1}{p+1}}} = 1$, and $Y_t^{\mathsf{obs}} = Y_t(\bm{1}{p+1})$. So $\mathbb{E}\left[Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{1}{p+1}}}}{\Pr(\bm{W}{t-p:t} = \bm{1}{p+1})} \right] = Y_t(\bm{1}{m+1})$. Similarly $\mathbb{E}\left[Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{0}{p+1}}}}{\Pr(\bm{W}{t-p:t} = \bm{0}{p+1})} \right] = Y_t(\bm{0}_{p+1})$. Sum them up for any $t \in {p+1:T}$ we finish the proof. $\square$
10. Proofs and Discussions from Section 3
Section Summary: This section of the appendix explains the proofs and supporting details for Section 3 of the paper, focusing on switchback experiments where the treatment probability equals the window size m. It introduces notations for randomization points that determine treatment assignments in single periods or sliding windows of m periods, including overlaps between windows and inverse propensity scores to adjust for randomization biases. Key results show that a treatment effect estimator is unbiased on average, with a lemma deriving the expected squared value of an indicator term involving potential outcomes to analyze variance.
In Section 3 we focus on the case when $p=m$. Throughout this section in the appendix, we use only $m$ instead of $p$.
10.1 Extra Notations Used in the Proofs from Section 3
Recall that any regular switchback experiment can be represented by $\mathbb{T} = {t_0, t_1, ..., t_K} \subseteq [T]$ and $\mathbb{Q} = (q_0, q_1, ..., q_K) \in (0, 1)^{K+1}$. We first focus on the dependence on $\mathbb{T}$, the randomization points. Define $f_\mathbb{T}: [T] \to \mathbb{T}$ to be the "determining randomization point of period $t$ ", i.e.,
$ f_\mathbb{T}(t) = \max \left{ j \left| j \in \mathbb{T}, j \leq t \right. \right} $
such that the coin flip in period $f_\mathbb{T}(t)$ uniquely determines the distribution of $W_t$, i.e., $W_t = W_{f_\mathbb{T}(t)}$. When $\mathbb{T}$ is clear from the context we also omit the subscript and use $f(t)$ for $f_\mathbb{T}(t)$.
Similarly, we define $f^m_\mathbb{T}(t): [T] \to {0, 1}^\mathbb{T}$, which maps a time period to a subset of $\mathbb{T}$, to be the "determining randomization points of periods ${t-m, t-m+1, ..., t}$ ", i.e.
$ f^m_\mathbb{T}(t) = \left{ j \left| \exists i \in {t-m, ..., t}, s.t. \ j = f_\mathbb{T}(i) \right. \right} $
such that $f^m_\mathbb{T}(t) \subseteq \mathbb{T} \subseteq [T]$. And $f^m_\mathbb{T}(t)$ contains all the time periods whose coin flips uniquely determine the distributions of $W_{t-m}, W_{t-m+1}, ..., W_t$. Denote $\left| f^m_\mathbb{T}(t) \right| = J$, the cardinality of set $f^m_\mathbb{T}(t)$. We keep in mind that $J$ depends on $m, t$ and $\mathbb{T}$, yet they are all omitted for brevity. Since the treatment assignments $\bm{W}{t-m:t}$ are determined by at least one randomization point $f(t-m)$, we know that $f^m\mathbb{T}(t) \ne \emptyset$ is non-empty, i.e.,
$ \begin{align} \left| f^m_\mathbb{T}(t) \right| = J \geq 1. \end{align}\tag{15} $
Let the elements be $f^m_\mathbb{T}(t) = {u_1, u_2, ..., u_J}$, and let $u_1 < u_2 < ... < u_J$.
Finally, define "overlapping randomization points of periods ${t-m, t-m+1, ..., t}$ and ${t'-m, t'-m+1, ..., t'}$ " to be
$ O_\mathbb{T}(t, t') = f^m_\mathbb{T}(t) \cap f^m_\mathbb{T}(t') $
Denote $\left| O_\mathbb{T}(t, t') \right| = J^\mathsf{o}$. We keep in mind that $J^\mathsf{o}$ depends on $m, t, t'$ and $\mathbb{T}$, yet they are all omitted for brevity.
Now we introduce an important short-hand notation. Recall that for any randomization point $t_k$, the associated $q_k$ is the probability that $W_{t_k}$ receives treatment, i.e., $q_k= \Pr(W_{t_k} = 1)$. And recall that $\bar{q}_k = 1 - q_k$. Now define for any $t \in {m+1:T}$,
$ \begin{split} \mathbf{1}t(\mathbb{T}, \mathbb{Q}, \mathbb{Y}) = Y_t(\bm{1}{m+1}) \left[\mathbf{1}{\bm{W}{t-m:t} = \bm{1}{m+1}} \prod_{j=1}^J {\frac{1}{q_{u_j}}} - 1 \right] \
- Y_t(\bm{0}{m+1}) \left[\mathbf{1}{\bm{W}{t-m:t} = \bm{0}{m+1}} \prod{j=1}^J {\frac{1}{\bar{q}_{u_j}}} - 1 \right] \end{split}\tag{16} $
where we use $\prod_{j=1}^J (1 / q_{u_j})$ and $\prod_{j=1}^J (1 / \bar{q}_{u_j})$ to calculate the inverse propensity scores. When $\mathbb{T}, \mathbb{Q}$ and $\mathbb{Y}$ are clear from the context we omit them and use $\mathbf{1}_t$ for $\mathbf{1}_t(\mathbb{T}, \mathbb{Q}, \mathbb{Y})$.
Using the above notation, we could re-write
$ \begin{align*} \widehat{\tau}m - \tau_m = \frac{1}{T-m} \sum{t=m+1}^T \mathbf{1}_t \end{align*} $
Similar to Proposition 9, we can check the expectation of $\mathbf{1}_t$ by expanding the probability governing $\bm{W}$ (the only source of randomness is our assignment path $\bm{W}$). For any $t \in {m+1, m+2, ..., T}$,
$ \begin{align} \mathbb{E}[\mathbf{1}_t] = 0. \end{align}\tag{17} $
10.2 Preliminary Results
In this section we introduce two Lemmas for the proof of Theorem 13 and proof of Lemma 12.
Lemma 25
Under Assumptions Assumption 2–Assumption 4, for any $t \in [T]$, let $\left| f^m_\mathbb{T}(t) \right| = J$.
$ \begin{align} \mathbb{E}[\mathbf{1}t^2] = & \left(\prod{j=1}^J \frac{1}{q_{u_j}} - 1\right) Y_t(\bm{1}{m+1})^2 + 2 Y_t(\bm{1}{m+1}) Y_t (\bm{0}{m+1}) + \left(\prod{j=1}^J \frac{1}{\bar{q}{u_j}} - 1\right) Y_t(\bm{0}{m+1})^2. \end{align}\tag{18} $
Proof of Lemma 25.: Denote $\left| f^m_\mathbb{T}(t) \right| = J$. Let the elements be $f^m_\mathbb{T}(t) = {u_1, u_2, ..., u_J}$. Let $u_1 < u_2 < ... < u_J$.
Using the notations defined earlier in Section 10.1 and, in particular, the definition of Equation 16, we can directly calculate the squared terms of $\mathbb{E}[\mathbf{1}_t^2]$ by consulting the law of total expectation.
$ \begin{align*} \mathbb{E}[\mathbf{1}t^2] = & \Pr\left(\bm{W}{t-m:t} = \bm{1}{m+1} \right) \cdot \mathbb{E}[\mathbf{1}t^2 \left| \bm{W}{t-m:t} = \bm{1}{m+1} \right.] \ & + \Pr\left(\bm{W}{t-m:t} = \bm{1}{m+1} \right) \cdot \mathbb{E}[\mathbf{1}t^2 \left| \bm{W}{t-m:t} = \bm{1}{m+1} \right.] \ & + \Pr\left(\bm{W}{t-m:t} = \bm{1}{m+1} \right) \cdot \mathbb{E}[\mathbf{1}t^2 \left| \bm{W}{t-m:t} = \bm{1}{m+1} \right.] \ = & \Pr\left(\bm{W}{t-m:t} = \bm{1}{m+1} \right) \cdot \left{ Y_t(\bm{1}{m+1}) \left(\prod{j=1}^J\frac{1}{q_{u_j}} - 1\right) - Y_t(\bm{0}{m+1}) (0 - 1)\right}^2 \ & + \Pr\left(\bm{W}{t-m:t} = \bm{0}{m+1} \right) \cdot \left{ Y_t(\bm{1}{m+1}) (0 - 1) - Y_t(\bm{0}{m+1}) \left(\prod{j=1}^J\frac{1}{\bar{q}{u_j}} - 1\right) \right}^2 \ & + \Pr\left(\bm{W}{t-m:t} \ne \bm{1}{m+1} \text{ \ or \ } \bm{0}{m+1} \right) \cdot \left{ Y_t(\bm{1}{m+1}) (0 - 1) - Y_t(\bm{0}{m+1}) (0 - 1) \right}^2 \ = & \Pr\left((W_{u_1}, ..., W_{u_J}) = \bm{1}J \right) \cdot \left{ \left(\prod{j=1}^J\frac{1}{q_{u_j}} - 1\right) Y_t(\bm{1}{m+1}) + Y_t(\bm{0}{m+1}) \right}^2 \ & + \Pr\left((W_{u_1}, ..., W_{u_J}) = \bm{0}J \right) \cdot \left{ - Y_t(\bm{1}{m+1}) - \left(\prod_{j=1}^J\frac{1}{\bar{q}{u_j}} - 1\right) Y_t(\bm{0}{m+1}) \right}^2 \ & + \Pr\left((W_{u_1}, ..., W_{u_J}) \ne \bm{1}J \text{ \ or \ } \bm{0}J \right) \cdot \left{ - Y_t(\bm{1}{m+1}) + Y_t(\bm{0}{m+1}) \right}^2 \ = & \prod_{j=1}^J q_{u_j} \cdot \left{ \prod_{j=1}^J\frac{1}{q_{u_j}} \cdot Y_t(\bm{1}{m+1}) - Y_t(\bm{1}{m+1}) + Y_t(\bm{0}{m+1}) \right}^2 \ & + \prod{j=1}^J \bar{q}{u_j} \cdot \left{ - \prod{j=1}^J\frac{1}{\bar{q}{u_j}} \cdot Y_t(\bm{0}{m+1}) - Y_t(\bm{1}{m+1}) + Y_t(\bm{0}{m+1}) \right}^2 \ & + \left(1 - \prod_{j=1}^J q_{u_j} - \prod_{j=1}^J \bar{q}{u_j} \right) \cdot \left{ - Y_t(\bm{1}{m+1}) + Y_t(\bm{0}{m+1}) \right}^2 \ = & \left(\prod{j=1}^J \frac{1}{q_{u_j}} - 1\right) Y_t(\bm{1}{m+1})^2 + 2 Y_t(\bm{1}{m+1}) Y_t (\bm{0}{m+1}) + \left(\prod{j=1}^J \frac{1}{\bar{q}{u_j}} - 1\right) Y_t(\bm{0}{m+1})^2 \end{align*} $
which finishes the proof. $\square$
Lemma 26
Under Assumptions Assumption 2–Assumption 4, for any $t < t' \in [T]$, when $\left| O_\mathbb{T}(t, t') \right| = J^\mathsf{o} = 0$,
$ \begin{align} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = & 0. \end{align}\tag{19} $
When $\left| O_\mathbb{T}(t, t') \right| = J^\mathsf{o} \geq 1$,
$ \begin{align} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = & (\prod_{j=1}^{J^\mathsf{o}} \frac{1}{q_{u^\mathsf{o}j}} - 1) Y_t(\bm{1}{m+1}) Y_{t'}(\bm{1}{m+1}) + Y_t(\bm{1}{m+1}) Y_{t'}(\bm{0}{m+1}) \nonumber \ & + Y_t(\bm{0}{m+1}) Y_{t'}(\bm{1}{m+1}) + (\prod{j=1}^{J^\mathsf{o}} \frac{1}{\bar{q}{u^\mathsf{o}j}} - 1) Y_t(\bm{0}{m+1}) Y{t'}(\bm{0}_{m+1}). \end{align}\tag{20} $
Proof of Lemma 26.: Denote $\left| f^m_\mathbb{T}(t) \right| = J$, $\left| f^m_\mathbb{T}(t') \right| = J'$, and $\left| O_\mathbb{T}(t, t') \right| = J^\mathsf{o}$. Let the elements be $f^m_\mathbb{T}(t) = {u_1, u_2, ..., u_J}$, $f^m_\mathbb{T}(t') = {u'1, u'2, ..., u'{J'}}$, and $O\mathbb{T}(t, t') = {u^\mathsf{o}_1, u^\mathsf{o}2, ..., u^\mathsf{o}{J^\mathsf{o}}}$. Let $u_1 < u_2 < ... < u_J$, $u'_1 < u'2 < ... < u'{J'}$, and $u^\mathsf{o}_1 < u^\mathsf{o}2 < ... < u^\mathsf{o}{J^\mathsf{o}}$.
One time period could have different numberings in $f_{\mathbb{T}}^m(t)$, $f_{\mathbb{T}}^m(t')$, and $O_{\mathbb{T}}(t, t')$. For example, $u_{J-J^\mathsf{o}+1} = u'1 = u^\mathsf{o}1$, and $u{J} = u'{J^\mathsf{o}} = u^\mathsf{o}_{J^\mathsf{o}}$. See Table 6 for an illustrator of the determining randomization points and the overlapping randomization points.
::: {caption="Table 6: Illustrator of the determining randomization points and the overlapping randomization points."}

:::
First, when $J^\mathsf{o} = 0$, this implies that $\mathbf{1}t$ and $\mathbf{1}{t'}$ are independent. Then $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = \mathbb{E}[\mathbf{1}t] \mathbb{E}[\mathbf{1}{t'}] = 0$, where the second equality is due to 17.
When $J^\mathsf{o} \geq 1$, this implies that $\mathbf{1}t$ and $\mathbf{1}{t'}$ are correlated. Using the notations defined above,
$ \begin{align} \mathbb{E}[\mathbf{1}{t} \mathbf{1}{t'}] = & \mathbb{E}{W{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}}} \left[\mathbb{E}\left[\mathbf{1}{t} \mathbf{1}{t'} \left| W_{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}} \right. \right] \right] \ = & \Pr\left((W_{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}}) = \bm{1}{J^\mathsf{o}} \right) \mathbb{E}\left[\mathbf{1}{t} \mathbf{1}{t'} \left| (W{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}}) = \bm{1}{J^\mathsf{o}} \right. \right] \nonumber \ & + \Pr\left((W{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}}) = \bm{0}{J^\mathsf{o}} \right) \mathbb{E}\left[\mathbf{1}{t} \mathbf{1}{t'} \left| (W{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}}) = \bm{0}{J^\mathsf{o}} \right. \right] \nonumber \ & + \Pr\left((W{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}}) \ne \bm{1}{J^\mathsf{o}} \text{\ or \ } \bm{0}{J^\mathsf{o}} \right) \mathbb{E}\left[\mathbf{1}{t} \mathbf{1}{t'} \left| (W_{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}}) \ne \bm{1}{J^\mathsf{o}} \text{\ or \ } \bm{0}{J^\mathsf{o}} \right. \right] \nonumber \end{align}\tag{21} $
Next we go over the three cases of $(W_{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}})$ as decomposed above. Note that conditional on $(W_{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}})$, $\mathbf{1}{t}$ and $\mathbf{1}{t'}$ are independent, i.e.,
$ \begin{align*} \mathbb{E}\left[\mathbf{1}t \mathbf{1}{t'} \left| W_{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}} \right. \right] = \mathbb{E}\left[\mathbf{1}t \left| W{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}} \right. \right] \mathbb{E}\left[\mathbf{1}{t'} \left| W{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}} \right. \right] \end{align*} $
(1) With probability $\prod_{j=1}^{J^\mathsf{o}} q_{u^\mathsf{o}j}$, $(W{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}}) = \bm{1}_{J^\mathsf{o}}$. In this case
$ \begin{align*} \mathbb{E}\left[\mathbf{1}t \left| W{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}} \right. \right] = & \Pr\left(\bm{W}{t-m:t} = \bm{1}{m+1} \right) \cdot \left{ Y_t(\bm{1}{m+1}) (\prod{j=1}^J \frac{1}{q_{u_j}} - 1) + Y_t(\bm{0}{m+1})\right} \ & + \Pr\left(\bm{W}{t-m:t} \ne \bm{1}{m+1} \right) \cdot \left{ Y_t(\bm{1}{m+1}) (0 - 1) + Y_t(\bm{0}{m+1})\right} \ = & \Pr\left((W{u_1}, W_{u_2}, ..., W_{u_{J-J^\mathsf{o}}}) = \bm{1}{J-J^\mathsf{o}} \right) \cdot \left{ Y_t(\bm{1}{m+1}) (\prod_{j=1}^J \frac{1}{q_{u_j}} - 1) + Y_t(\bm{0}{m+1})\right} \ & + \Pr\left((W{u_1}, W_{u_2}, ..., W_{u_{J-J^\mathsf{o}}}) \ne \bm{1}{J-J^\mathsf{o}} \right) \cdot \left{ - Y_t(\bm{1}{m+1}) + Y_t(\bm{0}{m+1})\right} \ = & \prod{j=1}^{J-J^\mathsf{o}} q_{u_j} \cdot \left{ Y_t(\bm{1}{m+1}) (\prod{j=1}^J \frac{1}{q_{u_j}} - 1) + Y_t(\bm{0}{m+1})\right} \ & + (1 - \prod{j=1}^{J-J^\mathsf{o}} q_{u_j}) \cdot \left{ - Y_t(\bm{1}{m+1}) + Y_t(\bm{0}{m+1})\right} \ = & (\prod_{j=1}^{J^\mathsf{o}} \frac{1}{q_{u^\mathsf{o}j}} - 1) Y_t(\bm{1}{m+1}) + Y_t(\bm{0}_{m+1}) \end{align*} $
where the third equality is due to 2. Similarly,
$ \begin{align*} \mathbb{E}\left[\mathbf{1}{t'} \left| W{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}} \right. \right] = & \Pr\left(\bm{W}{t'-m:t'} = \bm{1}{m+1} \right) \cdot \left{ Y_{t'}(\bm{1}{m+1}) (\prod{j=1}^{J'} \frac {1}{q_{u_j'}} - 1) + Y_{t'}(\bm{0}{m+1})\right} \ & + \Pr\left(\bm{W}{t'-m:t'} \ne \bm{1}{m+1} \right) \cdot \left{ Y{t'}(\bm{1}{m+1}) (0 - 1) + Y{t'}(\bm{0}{m+1})\right} \ = & \Pr\left((W{u'{J^\mathsf{o} + 1}}, W{u'{J^\mathsf{o} + 2}}, ..., W{u'{J'}}) = \bm{1}{J'-J^\mathsf{o}} \right) \cdot \left{ Y_{t'}(\bm{1}{m+1}) (\prod{j=1}^{J'} \frac {1}{q_{u'j}} - 1) + Y{t'}(\bm{0}{m+1})\right} \ & + \Pr\left((W{u'{J^\mathsf{o} + 1}}, W{u'{J^\mathsf{o} + 2}}, ..., W{u'{J'}}) \ne \bm{1}{J'-J^\mathsf{o}} \right) \cdot \left{ - Y_{t'}(\bm{1}{m+1}) + Y{t'}(\bm{0}{m+1})\right} \ = & \prod{j=J^\mathsf{o}+1}^{J'} q_{u'j} \cdot \left{ Y{t'}(\bm{1}{m+1}) (\prod{j=1}^{J'} \frac {1}{q_{u'j}} - 1) + Y{t'}(\bm{0}{m+1})\right} \ & + (1 - \prod{j = J^\mathsf{o} + 1}^{J'} q_{u'j}) \cdot \left{ - Y{t'}(\bm{1}{m+1}) + Y{t'}(\bm{0}{m+1})\right} \ = & (\prod{j=1}^{J^\mathsf{o}} \frac{1}{q_{u^\mathsf{o}j}} - 1) Y{t'}(\bm{1}{m+1}) + Y{t'}(\bm{0}_{m+1}) \end{align*} $
(2) With probability $\prod_{j=1}^{J^\mathsf{o}} \bar{q}{u^\mathsf{o}j}$, $(W{u_1^\mathsf{o}}, ..., W{u_{J^\mathsf{o}}^\mathsf{o}}) = \bm{0}_{J^\mathsf{o}}$. This case is similar to Case (1), and we can calculate the expectation similarly.
$ \begin{align*} \mathbb{E}\left[\mathbf{1}t \left| W{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}} \right. \right] = & \Pr\left(\bm{W}{t-m:t} = \bm{0}{m+1} \right) \cdot \left{ -Y_t(\bm{1}{m+1}) - Y_t(\bm{0}{m+1}) (\prod_{j=1}^J \frac{1}{\bar{q}{u_j}} - 1) \right} \ & + \Pr\left(\bm{W}{t-m:t} \ne \bm{0}{m+1} \right) \cdot \left{ - Y_t(\bm{1}{m+1}) - Y_t(\bm{0}{m+1}) (0 - 1) \right} \ = & \prod{j=1}^{J-J^\mathsf{o}} \bar{q}{u_j} \cdot \left{ - Y_t(\bm{1}{m+1}) - Y_t(\bm{0}{m+1}) (\prod{j=1}^J \frac{1}{\bar{q}{u_j}} - 1) \right} \ & + (1 - \prod{j=1}^{J-J^\mathsf{o}} \bar{q}{u_j}) \cdot \left{ - Y_t(\bm{1}{m+1}) + Y_t(\bm{0}{m+1})\right} \ = & - Y_t(\bm{1}{m+1}) - (\prod_{j=1}^{J^\mathsf{o}} \frac{1}{\bar{q}_{u^\mathsf{o}j}} - 1) Y_t(\bm{0}{m+1}) \end{align*} $
and again, similarly,
$ \begin{align*} \mathbb{E}\left[\mathbf{1}{t'} \left| W{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}} \right. \right] = & \Pr\left(\bm{W}{t'-m:t'} = \bm{0}{m+1} \right) \cdot \left{ -Y_{t'}(\bm{1}{m+1}) - Y{t'}(\bm{0}{m+1}) (\prod{j=1}^{J'}\frac{1}{\bar{q}{u'j}} - 1) \right} \ & + \Pr\left(\bm{W}{t'-m:t'} \ne \bm{0}{m+1} \right) \cdot \left{ - Y_{t'}(\bm{1}{m+1}) - Y{t'}(\bm{0}{m+1}) (0 - 1) \right} \ = & \prod{j=J^\mathsf{o}+1}^{J'} \bar{q}{u'j} \cdot \left{ - Y{t'}(\bm{1}{m+1}) - Y_{t'}(\bm{0}{m+1}) (\prod{j=1}^{J'}\frac{1}{\bar{q}{u'j}} - 1) \right} \ & + (1 - \prod{j=J^\mathsf{o}+1}^{J'} \bar{q}{u'j}) \cdot \left{ - Y{t'}(\bm{1}{m+1}) + Y{t'}(\bm{0}{m+1})\right} \ = & - Y{t'}(\bm{1}{m+1}) - (\prod{j=1}^{J^\mathsf{o}}\frac{1}{\bar{q}{u^\mathsf{o}j}} - 1) Y{t'}(\bm{0}{m+1}) \end{align*} $
(3) With probability $1 - 2 \cdot (1 / 2^{J^\mathsf{o}})$, $(W_{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}}) \ne \bm{1}{J^\mathsf{o}}$ or $\bm{0}{J^\mathsf{o}}$. In this case
$ \begin{align*} \mathbb{E}\left[\mathbf{1}t \left| W{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}} \right. \right] = & - Y_{t}(\bm{1}{m+1}) + Y{t}(\bm{0}{m+1}) \ \mathbb{E}\left[\mathbf{1}{t'} \left| W_{u_1^\mathsf{o}}, ..., W_{u_{J^\mathsf{o}}^\mathsf{o}} \right. \right] = & - Y_{t'}(\bm{1}{m+1}) + Y{t'}(\bm{0}_{m+1}) \end{align*} $
Finally, putting all above together into Equation 21, we have
$ \begin{align*} \mathbb{E}[\mathbf{1}{t} \mathbf{1}{t'}] = & \prod_{j=1}^{J^\mathsf{o}} q_{u^\mathsf{o}j} \cdot \left{ (\prod{j=1}^{J^\mathsf{o}} \frac{1}{q_{u^\mathsf{o}j}} - 1) Y_t(\bm{1}{m+1}) + Y_t(\bm{0}{m+1}) \right} \cdot \left{ (\prod{j=1}^{J^\mathsf{o}} \frac{1}{q_{u^\mathsf{o}j}} - 1) Y{t'}(\bm{1}{m+1}) + Y{t'}(\bm{0}{m+1}) \right} \ & + \prod{j=1}^{J^\mathsf{o}} \bar{q}{u^\mathsf{o}j} \cdot \left{ - Y_t(\bm{1}{m+1}) - (\prod{j=1}^{J^\mathsf{o}} \frac{1}{\bar{q}{u^\mathsf{o}j}} - 1) Y_t(\bm{0}{m+1}) \right} \cdot \left{ - Y{t'}(\bm{1}{m+1}) - (\prod{j=1}^{J^\mathsf{o}}\frac{1}{\bar{q}{u^\mathsf{o}j}} - 1) Y{t'}(\bm{0}{m+1}) \right} \ & + \left{ 1- \prod_{j=1}^{J^\mathsf{o}} q_{u^\mathsf{o}j} - \prod{j=1}^{J^\mathsf{o}} \bar{q}{u^\mathsf{o}j} \right} \cdot \left{ - Y{t}(\bm{1}{m+1}) + Y_{t}(\bm{0}{m+1}) \right} \cdot \left{ - Y{t'}(\bm{1}{m+1}) + Y{t'}(\bm{0}{m+1}) \right} \ = & (\prod{j=1}^{J^\mathsf{o}} \frac{1}{q_{u^\mathsf{o}j}} - 1) Y_t(\bm{1}{m+1}) Y_{t'}(\bm{1}{m+1}) + Y_t(\bm{1}{m+1}) Y_{t'}(\bm{0}{m+1}) \ & + Y_t(\bm{0}{m+1}) Y_{t'}(\bm{1}{m+1}) + (\prod{j=1}^{J^\mathsf{o}} \frac{1}{\bar{q}{u^\mathsf{o}j}} - 1) Y_t(\bm{0}{m+1}) Y{t'}(\bm{0}_{m+1}) \end{align*} $
which finishes the proof. $\square$
10.3 Lemma 12: Adversarial Selection of Potential Outcomes
In this section, we first prove Lemma 12, and then discuss the implications of Lemma 12.
10.3.1 Proof of
Lemma 12.
The proof of Lemma 12 is through careful expansion of the risk function, the expected square loss.
Proof of Lemma 12.: From Lemma 25 and Lemma 26, all the terms are quadratic, and all the coefficients are non-negative. After multiplying the constant $(T-m)^2$, we can expand, for any design of experiment $(\mathbb{T}, \mathbb{Q})$ and any potential outcomes $\mathbb{Y} \in \mathcal{Y}$, the following terms:
$ \begin{align*} & (T-m)^2 \cdot \mathbb{E}\left[\left(\widehat{\tau}m - \tau_m \right)^2 \right] \ = & \sum{t=m+1}^T \left{ \left(\prod_{j=1}^J \frac{1}{q_{u_j}} - 1\right) Y_t(\bm{1}{m+1})^2 + 2 Y_t(\bm{1}{m+1}) Y_t (\bm{0}{m+1}) + \left(\prod{j=1}^J \frac{1}{\bar{q}{u_j}} - 1\right) Y_t(\bm{0}{m+1})^2 \right} \ & + \sum_{\substack{m+1 \leq t<t' \leq T \ \left| O_\mathbb{T}(t, t') \right| \geq 1}} \left{\left(\prod_{j=1}^{J^\mathsf{o}} \frac{1}{q_{u^\mathsf{o}j}} - 1\right) Y_t(\bm{1}{m+1}) Y_{t'}(\bm{1}{m+1}) + Y_t(\bm{1}{m+1}) Y_{t'}(\bm{0}{m+1}) \right. \ & \left.\hphantom{+ \sum{\substack{m+1 \leq t<t' \leq T \ \left| O_\mathbb{T}(t, t') \right| \geq 1}}} + Y_t(\bm{0}{m+1}) Y{t'}(\bm{1}{m+1}) + \left(\prod{j=1}^{J^\mathsf{o}} \frac{1}{\bar{q}{u^\mathsf{o}j}} - 1\right) Y_t(\bm{0}{m+1}) Y{t'}(\bm{0}_{m+1}) \right} \end{align*} $
where the equality is due to Lemma 25 and Lemma 26. Notice that in the first summation, all the coefficients in the front of $Y_t(\bm{1}{m+1})^2$, $Y_t(\bm{1}{m+1}) Y_t (\bm{0}{m+1})$, and $Y_t(\bm{0}{m+1})^2$ are strictly positive, because $q_{u_j}$ are strictly between $(0, 1)$. In the second summation, for those periods such that $\left| O_\mathbb{T}(t, t') \right| \geq 1$, all the coefficients in the front of $Y_t(\bm{1}{m+1}) Y{t'}(\bm{1}{m+1})$, $Y_t(\bm{1}{m+1}) Y_{t'}(\bm{0}{m+1})$, $Y_t(\bm{0}{m+1}) Y_{t'}(\bm{1}{m+1})$, and $Y_t(\bm{0}{m+1}) Y_{t'}(\bm{0}{m+1})$ are strictly positive as well, because $q{u_j}$ are strictly between $(0, 1)$.
For the squared terms in the above expression, $Y_t(\bm{1}{m+1})^2 \leq B^2, Y_t(\bm{0}{m+1})^2 \leq B^2$ for any $t \in {m+1:T}$. This is because $f(y)=y^2$ attains maximum at the end points of the interval $[-B, B]$. For the cross-product terms in the above expression, no matter if $(y_1, y_2)$ takes $(Y_t(\bm{1}{m+1}), Y_t(\bm{0}{m+1}))$, $(Y_t(\bm{1}{m+1}), Y{t'}(\bm{1}{m+1}))$, $(Y_t(\bm{1}{m+1}), Y_{t'}(\bm{0}{m+1}))$, $(Y_t(\bm{0}{m+1}), Y_{t'}(\bm{1}{m+1}))$, or $(Y_t(\bm{0}{m+1}), Y_{t'}(\bm{0}{m+1}))}$, we have that $y_1 \cdot y_2 \leq (y_1^2 + y_2^2)/2 \leq B^2$ where the first inequality is due to Cauchy-Schwarz, and the second inequality is due to convexity. Combining that fact that all coefficients are positive, $r(\eta{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}) \leq r(\eta_{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}^{+}) = r(\eta_{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}^{-})$.
Moreover, for any $\mathbb{Y} \in \mathcal{Y}$ such that $\mathbb{Y} \ne \mathbb{Y}^{+}$ or $\mathbb{Y}^{-}$, if $\exists \ t \in {m+1, ..., T}$ such that $-B < Y_t(\bm{1}{m+1}) < B$. Then from inequality Equation 15, $\prod_{j=1}^J \frac{1}{q_{u_j}} - 1 > 0$, so the inequality is strict. Similarly, if $\exists t \in {m+1, ..., T}$ such that $-B < Y_t(\bm{0}{m+1}) < B$, then combine $\prod_{j=1}^J \frac{1}{\bar{q}_{u_j}} - 1 > 0$, so the inequality is strict. $\square$
10.3.2 Implications of
Lemma 12.
Lemma 12 simplifies the minimax problem in Equation 6. Instead of thinking it as a minimax problem, we can now replace $\mathbb{Y}$ by either $\mathbb{Y}^+$ or $\mathbb{Y}^-$, and solve only a minimization problem.
Here we state Lemma 27 that is a direct implication of Lemma 12. It will be frequently used later on.
Lemma 27
When $\mathbb{Y} = \mathbb{Y}^{+}$ or $\mathbb{Y} = \mathbb{Y}^{-}$, under Assumptions Assumption 2–Assumption 11, for any $t \in [T]$,
$ \begin{align*} \mathbb{E}[\mathbf{1}t^2] = & \left(\frac{1}{\prod{j=1}^J q_{u_j}} + \frac{1}{\prod_{j=1}^J \bar{q}_{u_j}} \right) B^2. \end{align*} $
For any $t < t' \in [T]$, when $\left| O_\mathbb{T}(t, t') \right| = J^\mathsf{o} = 0$,
$ \begin{align*} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = & 0 \end{align*} $
When $\left| O_\mathbb{T}(t, t') \right| = J^\mathsf{o} \geq 1$,
$ \begin{align*} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = & \left(\frac{1}{\prod_{j=1}^{J^\mathsf{o}} q_{u^\mathsf{o}j}} + \frac{1}{\prod{j=1}^{J^\mathsf{o}} \bar{q}_{u^\mathsf{o}_j}} \right) B^2 \end{align*} $
Proof of Lemma 27.: Replace $Y_t(\bm{1}{m+1}) = Y_t(\bm{0}{m+1})$ by $B$ or $-B$ into the expressions in Lemma 25 and Lemma 26. $\square$
10.4 Theorem 13: Optimality of Fair Coin Flipping
In this section, we first prove Theorem 13, and then discuss the implications of Theorem 13.
10.4.1 Proof of
Theorem 13.
The proof of Theorem 13 is through an elegant inequality that highlights the balance between treatment probabilities and control probabilities.
Proof of Theorem 13.: Similar to the proof of Lemma 12, we expand the quadratic terms using Lemma 27. After multiplying the constant $(T-m)^2$, we can expand, for any design of experiment $(\mathbb{T}, \mathbb{Q})$ and any potential outcomes $\mathbb{Y} \in \mathcal{Y}$, the following terms:
$ \begin{align*} (T-m)^2 \cdot \mathbb{E}\left[\left(\widehat{\tau}m - \tau_m \right)^2 \right] = & \sum{t=m+1}^T \left(\prod_{j=1}^J \frac{1}{q_{u_j}} + \prod_{j=1}^J \frac{1}{\bar{q}{u_j}} \right) \cdot B^2 + \sum{\substack{m+1 \leq t<t' \leq T \ \left| O_\mathbb{T}(t, t') \right| \geq 1}} \left(\prod_{j=1}^{J^\mathsf{o}} \frac{1}{q_{u^\mathsf{o}j}} + \prod{j=1}^{J^\mathsf{o}} \frac{1}{\bar{q}_{u^\mathsf{o}_j}} \right) \cdot B^2 \end{align*} $
For each of them, due to Lemma 24, the minimum is obtained at $q_0=q_1=...=q_K=1/2$. $\square$
10.4.2 Implications of
Theorem 13.
Theorem 13 further simplifies the minimax problem in Equation 6. Now that we have identified the optimal randomization probabilities, we can directly plug in the optimal probabilities being $1/2$. Here we state Lemma 28 that is a combination of Lemma 27 and Theorem 13. It will be frequently used later on.
Lemma 28
Under Assumptions Assumption 2–Assumption 11, when $\mathbb{Y} = \mathbb{Y}^{+}$ or $\mathbb{Y} = \mathbb{Y}^{-}$, and when $q_0=q_1=...=q_K=1/2$, for any $t \in [T]$,
$ \begin{align*} \mathbb{E}[\mathbf{1}_t^2] = & 2^{J+1} B^2. \end{align*} $
For any $t < t' \in [T]$, when $\left| O_\mathbb{T}(t, t') \right| = J^\mathsf{o} = 0$,
$ \begin{align*} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = & 0 \end{align*} $
When $\left| O_\mathbb{T}(t, t') \right| = J^\mathsf{o} \geq 1$,
$ \begin{align*} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = & 2^{J^\mathsf{o}+1} B^2 \end{align*} $
Proof of Lemma 28.: Simply replace $q_0=q_1=...=q_K=1/2$ into Lemma 27. $\square$
10.5 Structural Results of the Optimal Design
Using Lemma 12, we now establish two structural results that further characterize the class of optimal designs of regular switchback experiments. Lemma 29 states the optimal starting and ending structure; Lemma 30 states the optimal middle-case structure. The proofs to Lemma 29 and Lemma 30 are deferred to Section 10.5.1 and Section 10.5.2, respectively.
Lemma 29
When $\mathbb{Y} = \mathbb{Y}^{+}$ or $\mathbb{Y} = \mathbb{Y}^{-}$, under Assumptions Assumption 2–Assumption 11, any optimal design of experiment $\mathbb{T}$ must satisfy
$ \begin{align*} t_1 \geq m+2, & & \text{and} & & t_K \leq T-m. \end{align*} $
Lemma 29 states that the first randomization point on period $1$ should be followed by at least $m$ periods that do not flip a coin, and that the last randomization point should be followed by at least $m$ periods that do not flip a coin. This guarantees that the assignments during ${1:m+1}$ and during ${T-m:T}$ both produce observed data that can be used to estimate the lag- $m$ effect.
Lemma 30
When $\mathbb{Y} = \mathbb{Y}^{+}$ or $\mathbb{Y} = \mathbb{Y}^{-}$, under Assumptions Assumption 2–Assumption 11, any optimal design of experiment $\mathbb{T}$ must satisfy
$ \begin{align*} t_{k+1} - t_{k-1} \geq m, \ \forall k \in [K]. \end{align*} $
Lemma 30 suggests that in every consecutive $m+1$ periods, there could be at most $3$ randomization points. Intuitively, too many randomization points in every consecutive $m+1$ periods decreases the chance of observing a useful assignment path of $\bm{1}{m+1}$ or $\bm{0}{m+1}$. Lemma 30 formalizes such intuition, and suggests that as the persistence of the carryover effect increases, the optimal design randomizes less often.
Lemma 29 and Lemma 30 restrict the space of possible optimal regular switchback experiment to a smaller class of switchback experiments. Under such a smaller class of switchback experiments, we can explicitly express the risk function in closed form, which we define below.
Lemma 31: Risk Function
When $\mathbb{Y} = \mathbb{Y}^{+}$ or $\mathbb{Y} = \mathbb{Y}^{-}$, under Assumptions Assumption 2–Assumption 11, as long as the following three conditions are satisfied,
$ \begin{align*} t_1 \geq m+2; & & t_K \leq T-m; & & t_{k+1} - t_{k-1} \geq m, \ \forall k \in [K], \end{align*} $
the risk function for any switchback experiment is given by
$ \begin{split} r(\eta_{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}) = \frac{1}{(T-m)^2} \left{ 4 \sum_{k=1}^{K+1} (t_{k} - t_{k-1})^2 + 8 m (t_K - t_1) + 4 m^2 K - 4 m^2 \right.\ \left. + 4 \sum_{k=2}^{K} [(m-t_k+t_{k-1})^+]^2\right} B^2 \end{split}\tag{22} $
Lemma 31 explicitly describes the risk function of any optimal design of regular switchback experiments, which lies in the optimal sub-class of switchback experiments. The proof of Lemma 31 is deferred to Section 10.5.3 in the appendix.
To understand the risk function in Lemma 31, we separately examine each term in Equation 22. The first summation of the squares $\sum_{k=1}^{K+1} (t_{k} - t_{k-1})^2$ suggests that the gap between two consecutive randomization points should not be too large. The middle term $8m(t_K-t_1)$ formalizes Lemma 29, suggesting that the second randomization point on period $t_1$ should not be too early and the last randomization point on period $t_K$ should not be too late. The last summation of the squares $\sum_{k=2}^{K} [(m-t_k+t_{k-1})^+]^2$ suggests that the gap should not be too small. Equation 22 formalizes the trade-off that we have described earlier in this section. First note that when we focus on the optimal design, we treat $T$ and $m$ both as constants. So the constant of $1/(T-m)$ in the expression of the risk function does not affect the optimal design.
10.5.1 Proof of
Lemma 29.
Proof of Lemma 29.: We prove the two parts separately, both by contradiction.
(1) Suppose there exists an optimal design $\mathbb{T} = {t_0=1, t_1, t_2, ..., t_K}$ such that $t_1 \leq m+1$. Then we try to construct another design $\tilde{\mathbb{T}}$, such that $\left| \tilde{\mathbb{T}} \right| = K = \left| \mathbb{T} \right| -1$. And the $K$ elements are $\tilde{\mathbb{T}} = {\tilde{t}_0=1, \tilde{t}_1 = t_2, \tilde{t}2 = t_3, ..., \tilde{t}{K-1} = t_K}$.
::: {caption="Table 7: An example of two regular switchback experiments $\mathbb{T}$ and $\tilde{\mathbb{T}}$ when $m=4$ and $t_1=3$."}

:::
Next we argue that when $\mathbb{Y} = \mathbb{Y}^{+}$ or $\mathbb{Y} = \mathbb{Y}^{-}$,
$ r(\mathbb{T}, \mathbb{Y}) > r(\tilde{\mathbb{T}}, \mathbb{Y}), $
which suggests that $\mathbb{T}$ is not the optimal design.
First, focus on the squared terms. For any $m+1 \leq t \leq t_1+m-1$, $t_1 \in f^m_{\mathbb{T}}(t), t_1 \ne f^m_{\tilde{\mathbb{T}}}(t)$. Moreover, $t-m \leq t_1 - 1$, so that $t_0 \in f^m_{\tilde{\mathbb{T}}}(t)$. So $f^m_{\mathbb{T}}(t) - {t_1} = f^m_{\tilde{\mathbb{T}}}(t)$, and $\left| f^m_{\tilde{\mathbb{T}}}(t) \right| \geq 1$. As a result,
$ \mathbb{E}[\mathbf{1}_t(\mathbb{T})^2] - \mathbb{E}[\mathbf{1}_t(\tilde{\mathbb{T}})^2] \geq (2^{2+1} - 2^{1+1}) B^2 = 4B^2. $
For any $t \geq t_1 + m$, either (i) $f_{\mathbb{T}}(t-m) = t_1$, in which case $f_{\tilde{\mathbb{T}}}(t-m) = t_0$. This is the only difference between $f^m_{\mathbb{T}}(t)$ and $f^m_{\tilde{\mathbb{T}}}(t)$, i.e., $f^m_{\mathbb{T}}(t) - {t_1} = f^m_{\tilde{\mathbb{T}}}(t) - {t_0}$. So $\left| f^m_{\mathbb{T}}(t) \right| = \left| f^m_{\tilde{\mathbb{T}}}(t) \right|$. The second case is (ii) $f_{\mathbb{T}}(t-m) \geq t_2$, in which case $f^m_{\mathbb{T}}(t) = f^m_{\tilde{\mathbb{T}}}(t)$. Both cases suggest that
$ \mathbb{E}[\mathbf{1}_t(\mathbb{T})^2] - \mathbb{E}[\mathbf{1}_t(\tilde{\mathbb{T}})^2] = 0. $
So we have
$ \begin{align*} \sum_{t=m+1}^T \mathbb{E}\left[\mathbf{1}t(\mathbb{T})^2 \right] - \sum{t=m+1}^T \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})^2 \right] = & \sum{t=m+1}^{t_1+m-1} \left(\mathbb{E}\left[\mathbf{1}_t(\mathbb{T})^2 \right] - \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})^2 \right] \right) + \sum{t=t_1+m}^{T} \left(\mathbb{E}\left[\mathbf{1}_t(\mathbb{T})^2 \right] - \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})^2 \right] \right) \ \geq & \sum{t=m+1}^{t_1+m-1} (4B^2) + 0 \ = & 4(t_1-1)B^2 \
& 0 \end{align*} $
Second, focus on the cross product terms. For any $t$ and $t'$ such that $m+1 \leq t < t' \leq t_1+m-1$, $t_1 \in O_{\mathbb{T}}(t, t'), t_1 \ne O_{\tilde{\mathbb{T}}}(t, t')$. Moreover, $t-m \leq t_1 - 1$, so that $t_0 \in O_{\mathbb{T}}(t, t')$. So $O_{\mathbb{T}}(t, t') - {t_1} = O_{\tilde{\mathbb{T}}}(t, t')$, and $\left| O_{\tilde{\mathbb{T}}}(t, t') \right| \geq 1$. As a result,
$ \mathbb{E}[\mathbf{1}t(\mathbb{T})\mathbf{1}{t'}(\mathbb{T})] - \mathbb{E}[\mathbf{1}t(\tilde{\mathbb{T}})\mathbf{1}{t'}(\tilde{\mathbb{T}})] \geq (2^{2+1} - 2^{1+1}) B^2 = 4B^2 > 0. $
For any $m+1 \leq t < t' \leq T$ such that $t' \geq t_1 + m$, either (i) $f_{\mathbb{T}}(t'-m) = t_1$, in which case $f_{\tilde{\mathbb{T}}}(t'-m) = t_0$. So $O_{\mathbb{T}}(t, t') - {t_1} = O_{\tilde{\mathbb{T}}}(t, t') - {t_0}$. So $\left| O_{\mathbb{T}}(t, t') \right| = \left| O_{\tilde{\mathbb{T}}}(t, t') \right|$. The second case is (ii) $f_{\mathbb{T}}(t'-m) \geq t_2$, in which case $O_{\mathbb{T}}(t, t') = O_{\tilde{\mathbb{T}}}(t, t')$. Both cases suggest that
$ \mathbb{E}[\mathbf{1}t(\mathbb{T})\mathbf{1}{t'}(\mathbb{T})] - \mathbb{E}[\mathbf{1}t(\tilde{\mathbb{T}})\mathbf{1}{t'}(\tilde{\mathbb{T}})] = 0. $
So we have
$ \begin{align*} & \sum_{m+1 \leq t < t' \leq T} \mathbb{E}\left[\mathbf{1}t(\mathbb{T})\mathbf{1}{t'}(\mathbb{T}) \right] - \sum_{m+1 \leq t < t' \leq T} \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})\mathbf{1}{t'}(\tilde{\mathbb{T}}) \right] \ = & \sum_{m+1 \leq t < t' \leq t_1+m-1} \left(\mathbb{E}\left[\mathbf{1}t(\mathbb{T})\mathbf{1}{t'}(\mathbb{T}) \right] - \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})\mathbf{1}{t'}(\tilde{\mathbb{T}}) \right] \right) + \sum_{\substack{m+1 \leq t < t' \leq T \ t' \geq t_1+m}} \left(\mathbb{E}\left[\mathbf{1}t(\mathbb{T})\mathbf{1}{t'}(\mathbb{T}) \right] - \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})\mathbf{1}{t'}(\tilde{\mathbb{T}}) \right] \right) \ \geq & 0 \end{align*} $
Combine both square terms and cross-product terms we know that
$ r(\mathbb{T}, \mathbb{Y}) > r(\tilde{\mathbb{T}}, \mathbb{Y}). $
(2) Suppose there exists an optimal design $\mathbb{T} = {t_0=1, t_1, t_2, ..., t_K}$ such that $t_K \geq T-m+1$. Then we try to construct another design $\tilde{\mathbb{T}}$, such that $\left| \tilde{\mathbb{T}} \right| = K = \left| \mathbb{T} \right| - 1$. And the $K$ elements are $\tilde{\mathbb{T}} = {\tilde{t}_0=1, \tilde{t}1 = t_1, \tilde{t}2 = t_2, ..., \tilde{t}{K-1} = t{K-1}}$.
::: {caption="Table 8: An example of two regular switchback experiments $\mathbb{T}$ and $\tilde{\mathbb{T}}$ when $m=4$ and $t_K=T-2$."}

:::
Next we argue that when $\mathbb{Y} = \mathbb{Y}^{+}$ or $\mathbb{Y} = \mathbb{Y}^{-}$,
$ r(\mathbb{T}, \mathbb{Y}) > r(\tilde{\mathbb{T}}, \mathbb{Y}), $
which suggests that $\mathbb{T}$ is not the optimal design.
First focus on the squared terms. For any $m+1 \leq t \leq t_K-1$, $f^m_{\mathbb{T}}(t) = f^m_{\tilde{\mathbb{T}}}(t)$ is totally unchanged.
$ \mathbb{E}[\mathbf{1}_t(\mathbb{T})^2] - \mathbb{E}[\mathbf{1}_t(\tilde{\mathbb{T}})^2] = 0. $
For any $t_K \leq t \leq T$, $t_K \notin f^m_{\tilde{\mathbb{T}}}(t), t_K \in f^m_{\mathbb{T}}(t)$. And all the other determining randomization points are unchanged. So $f^m_{\tilde{\mathbb{T}}}(t) \subset f^m_{\mathbb{T}}(t)$ and $f^m_{\mathbb{T}}(t) - {t_K} = f^m_{\tilde{\mathbb{T}}}(t)$ and $\left| f^m_{\tilde{\mathbb{T}}}(t) \right| \geq 1$.
$ \mathbb{E}[\mathbf{1}_t(\mathbb{T})^2] - \mathbb{E}[\mathbf{1}_t(\tilde{\mathbb{T}})^2] \geq (2^{2+1} - 2^{1+1}) B^2 = 4B^2. $
So we have
$ \begin{align*} \sum_{t=m+1}^T \mathbb{E}\left[\mathbf{1}t(\mathbb{T})^2 \right] - \sum{t=m+1}^T \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})^2 \right] = & \sum{t=m+1}^{t_K-1} \left(\mathbb{E}\left[\mathbf{1}_t(\mathbb{T})^2 \right] - \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})^2 \right] \right) + \sum{t=t_K}^{T} \left(\mathbb{E}\left[\mathbf{1}_t(\mathbb{T})^2 \right] - \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})^2 \right] \right) \ \geq & \sum{t=t_K}^{T} (4B^2) + 0 \ = & 4(T-t_K+1)B^2 \
& 0 \end{align*} $
Next we focus on the cross-product terms. For any $m+1 \leq t < t' \leq T$ such that $t \leq t_K-1$, $O_{\mathbb{T}}(t, t') = O_{\tilde{\mathbb{T}}}(t, t')$ is totally unchanged.
$ \mathbb{E}[\mathbf{1}t(\mathbb{T}) \mathbf{1}{t'}(\mathbb{T})] - \mathbb{E}[\mathbf{1}t(\tilde{\mathbb{T}}) \mathbf{1}{t'}(\tilde{\mathbb{T}})] = 0. $
For any $t_K \leq t < t' \leq T$, since $t' - m \leq T-m \leq t_K-1$, so $f_{\tilde{\mathbb{T}}}(t'-m) < t_{K}$ and $\left| O_{\tilde{\mathbb{T}}}(t, t') \right| \geq 1$ must contain an element. Moreover, $O_{\tilde{\mathbb{T}}}(t, t') \subset O_{\mathbb{T}}(t, t')$. So
$ \mathbb{E}[\mathbf{1}t(\mathbb{T}) \mathbf{1}{t'}(\mathbb{T})] - \mathbb{E}[\mathbf{1}t(\tilde{\mathbb{T}}) \mathbf{1}{t'}(\tilde{\mathbb{T}})] \geq (2^{2+1} - 2^{1+1}) B^2 \geq 4B^2 > 0. $
So we have
$ \begin{align*} & \sum_{m+1 \leq t < t' \leq T} \mathbb{E}\left[\mathbf{1}t(\mathbb{T})\mathbf{1}{t'}(\mathbb{T}) \right] - \sum_{m+1 \leq t < t' \leq T} \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})\mathbf{1}{t'}(\tilde{\mathbb{T}}) \right] \ = & \sum_{\substack{m+1 \leq t < t' \leq T \ t \leq t_K-1}} \left(\mathbb{E}\left[\mathbf{1}t(\mathbb{T})\mathbf{1}{t'}(\mathbb{T}) \right] - \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})\mathbf{1}{t'}(\tilde{\mathbb{T}}) \right] \right) + \sum_{t_K \leq t < t' \leq T} \left(\mathbb{E}\left[\mathbf{1}t(\mathbb{T})\mathbf{1}{t'}(\mathbb{T}) \right] - \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})\mathbf{1}{t'}(\tilde{\mathbb{T}}) \right] \right) \ \geq & 0 \end{align*} $
Combine both square terms and cross-product terms we know that
$ r(\mathbb{T}, \mathbb{Y}) > r(\tilde{\mathbb{T}}, \mathbb{Y}). $
$\square$
10.5.2 Proof of
Lemma 30.
Proof of Lemma 30.: Recall that we denote $t_0 = 1$ and $t_{K+1} = T+1$. First, from Lemma 29, $t_1 \geq m+2, t_K \leq T-m$. So $k=1$ and $k=K$ cases both hold. Next, when $2 \leq k \leq K-1$, we prove by contradiction.
Suppose there exists some optimal design $\mathbb{T}$, such that $\exists 2 \leq k \leq K-1, s.t. \ t_{k+1} - t_{k-1} \leq m-1.$ Denote
$ \mathbb{K} = {k \in{2:K-1} \left| t_{k+1} - t_{k-1} \leq m-1 \right.}. $
Since $\mathbb{K} \ne \emptyset$, pick $j = \max \mathbb{K}$ to be the largest element in $\mathbb{K}$. Apparently $j \leq K-1$ since $j \in {2:K-1}$. We also know that $t_{j+2} \geq t_j + m, $ because otherwise $j+1 \in \mathbb{K}$, which contradicts the maximality of $j$.
We now construct another design $\tilde{\mathbb{T}}$ such that $\left| \tilde{\mathbb{T}} \right| = K = \left| \mathbb{T} \right| -1$, and the $K$ elements are $\tilde{\mathbb{T}} = {\tilde{t}0 = 1, \tilde{t}1 = t_1, ..., \tilde{t}{j-1}= t{j-1}, \tilde{t}{j} = t{j+1}, ..., \tilde{t}_{K-1} = t_K}$.
::: {caption="Table 9: An example of two regular switchback experiments $\mathbb{T}$ and $\tilde{\mathbb{T}}$ when $m=4$ and $t_j = t_{j+1} - 1 = t_{j-1} + 2$."}

:::
Next we argue that when $\mathbb{Y} = \mathbb{Y}^{+}$ or $\mathbb{Y} = \mathbb{Y}^{-}$,
$ r(\mathbb{T}, \mathbb{Y}) > r(\tilde{\mathbb{T}}, \mathbb{Y}), $
which suggests that $\mathbb{T}$ is not the optimal design.
First focus on the squared terms. When $t \leq t_j - 1$, $f^m_{\mathbb{T}}(t) = f^m_{\tilde{\mathbb{T}}}(t)$ is totally unchanged.
$ \mathbb{E}[\mathbf{1}_t(\mathbb{T})^2] - \mathbb{E}[\mathbf{1}_t(\tilde{\mathbb{T}})^2] = 0. $
When $t_j \leq t \leq t_j+m-1$, this suggests that $t-m \leq t_J-1$ so that $f_{\tilde{\mathbb{T}}} \leq t_j-1$. So $t_j \notin f^m_{\tilde{\mathbb{T}}}(t), t_j \in f^m_{\mathbb{T}}(t)$. And all the other determining randomization points are unchanged. So $f^m_{\tilde{\mathbb{T}}}(t) \subset f^m_{\mathbb{T}}(t)$ and $f^m_{\mathbb{T}}(t) - {t_j} = f^m_{\tilde{\mathbb{T}}}(t)$ and $\left| f^m_{\tilde{\mathbb{T}}}(t) \right| \geq 1$.
$ \mathbb{E}[\mathbf{1}_t(\mathbb{T})^2] - \mathbb{E}[\mathbf{1}_t(\tilde{\mathbb{T}})^2] \geq (2^{2+1} - 2^{1+1}) B^2 = 4B^2. $
When $t_j +m \leq t \leq T$, either (i) $f_{\mathbb{T}}(t-m) = t_j$, in which case $f_{\tilde{\mathbb{T}}}(t-m) = t_{j-1}$. This is the only difference between $f^m_{\mathbb{T}}(t)$ and $f^m_{\tilde{\mathbb{T}}}(t)$, i.e., $f^m_{\mathbb{T}}(t) - {t_j} = f^m_{\tilde{\mathbb{T}}}(t) - {t_{j-1}}$. So $\left| f^m_{\mathbb{T}}(t) \right| = \left| f^m_{\tilde{\mathbb{T}}}(t) \right|$. The second case is (ii) $f_{\mathbb{T}}(t-m) \geq t_{j+1}$, in which case $f^m_{\mathbb{T}}(t) = f^m_{\tilde{\mathbb{T}}}(t)$. Both cases suggest that
$ \mathbb{E}[\mathbf{1}_t(\mathbb{T})^2] - \mathbb{E}[\mathbf{1}_t(\tilde{\mathbb{T}})^2] = 0. $
So we have
$ \begin{align*} & \sum_{t=m+1}^T \mathbb{E}\left[\mathbf{1}t(\mathbb{T})^2 \right] - \sum{t=m+1}^T \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})^2 \right] \ = & \sum{t=m+1}^{t_j-1} \left(\mathbb{E}\left[\mathbf{1}_t(\mathbb{T})^2 \right] - \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})^2 \right] \right) + \sum{t=t_j}^{t_j+m-1} \left(\mathbb{E}\left[\mathbf{1}_t(\mathbb{T})^2 \right] - \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})^2 \right] \right) + \sum{t=t_j+m}^{T} \left(\mathbb{E}\left[\mathbf{1}_t(\mathbb{T})^2 \right] - \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})^2 \right] \right) \ \geq & 0 + \sum{t=t_j}^{t_j+m-1} (4B^2) + 0\ = & 4(m-1)B^2 \
& 0 \end{align*} $
Next we focus on the cross-product terms. Let $m+1 \leq t < t' \leq T$. There are many cases which we summarize in Table 10
::: {caption="Table 10: Summary of the differences between cross-product terms under two regular switchback experiments $\mathbb{T}$ and $\tilde{\mathbb{T}}$."}
:::
We explain Table 10.
When $m+1 \leq t \leq t_{j-1}, t < t' \leq T$, all the overlapping randomization points are earlier than $t_{j-1}-1$, i.e., $\forall a \in O_{\mathbb{T}}(t, t'), a \leq t_{j-1}-1; \forall a \in O_{\tilde{\mathbb{T}}}(t, t'), a \leq t_{j-1}-1$. So $t_j \notin O_{\mathbb{T}}(t, t')$, and the overlapping randomization points are unchanged, i.e., $O_{\mathbb{T}}(t, t') = O_{\tilde{\mathbb{T}}}(t, t')$.
When $t_{j-1} \leq t \leq t_j-1, t < t' \leq t_j+m-1$, all the overlapping randomization points are earlier than $t_{j-1}$, i.e., $\forall a \in O_{\mathbb{T}}(t, t'), a \leq t_{j-1}; \forall a \in O_{\tilde{\mathbb{T}}}(t, t'), a \leq t_{j-1}$. So $t_j \notin O_{\mathbb{T}}(t, t')$, and the overlapping randomization points are unchanged, i.e., $O_{\mathbb{T}}(t, t') = O_{\tilde{\mathbb{T}}}(t, t')$.
When $t_{j-1} \leq t \leq t_j-1, t_j +m \leq t' \leq t_{j+1}+m-1$, changing from $\mathbb{T}$ to $\tilde{\mathbb{T}}$ increases the expected values. This is because $t'-m \geq t_j > t$. So first, $O_{\mathbb{T}}(t, t') = \emptyset$. But $f_{\tilde{\mathbb{T}}}(t'-m) = t_{j-1}$ and $t_{j-1} \in f^m_{\tilde{\mathbb{T}}}(t)$, which suggests that $t_{j-1} \in O_{\tilde{\mathbb{T}}}(t, t').$ Also, $\forall a \in f^m_{\tilde{\mathbb{T}}}(t'), a \geq t_{j-1}; \forall a \in f^m_{\mathbb{T}}(t), a \leq t_{j-1}$, which suggests that $t_{j-1}$ is the only overlapping element. So, $O_{\tilde{\mathbb{T}}}(t, t') = {t_{j-1}}$. In this case,
$ \mathbb{E}[\mathbf{1}t(\mathbb{T}) \mathbf{1}{t'}(\mathbb{T})] - \mathbb{E}[\mathbf{1}t(\tilde{\mathbb{T}}) \mathbf{1}{t'}(\tilde{\mathbb{T}})] = (0 - 2^{1+1}) B^2 = -4B^2. $
When $t_{j-1} \leq t \leq t_{j}-1, t_{j+1}+m \leq t' \leq T$, since $t'-m \geq t_{j+1} > t_j > t$, $O_{\mathbb{T}}(t, t') = O_{\tilde{\mathbb{T}}}(t, t') = \emptyset.$
When $t_j \leq t < t' \leq t_j+m-1$, $t_j \in O_{\mathbb{T}}(t, t')$ and $t_j \notin O_{\tilde{\mathbb{T}}}(t, t')$. And all the other overlapping randomization points are unchanged, so $O_{\mathbb{T}}(t, t') - {t_j} = O_{\tilde{\mathbb{T}}}(t, t')$ and $\left| O_{\tilde{\mathbb{T}}}(t, t') \right| \geq 1.$ In this case,
$ \mathbb{E}[\mathbf{1}t(\mathbb{T}) \mathbf{1}{t'}(\mathbb{T})] - \mathbb{E}[\mathbf{1}t(\tilde{\mathbb{T}}) \mathbf{1}{t'}(\tilde{\mathbb{T}})] \geq (2^{2+1} - 2^{1+1}) B^2 = 4B^2. $
When $t_j \leq t \leq t_j+m-1, t_j+m \leq t' \leq T$, either (i) $f^m_{\mathbb{T}}(t'-m) = t_j$, in which case $f_{\tilde{\mathbb{T}}}(t'-m) = t_{j-1}$. This is the only difference between $O_{\mathbb{T}}(t, t')$ and $O_{\tilde{\mathbb{T}}}(t, t')$, i.e., $O_{\mathbb{T}}(t, t') - {t_j} = O_{\tilde{\mathbb{T}}}(t, t') - {t_{j-1}}$. $\left| O_{\mathbb{T}}(t, t') \right| = \left| O_{\tilde{\mathbb{T}}}(t, t') \right|$. The second case is (ii) $f_{\mathbb{T}}(t'-m) \geq t_{j+1}$, in which case $O_{\mathbb{T}}(t, t') = O_{\tilde{\mathbb{T}}}(t, t')$ is unchanged. Both cases suggest that $\mathbb{E}[\mathbf{1}t(\mathbb{T}) \mathbf{1}{t'}(\mathbb{T})] - \mathbb{E}[\mathbf{1}t(\tilde{\mathbb{T}}) \mathbf{1}{t'}(\tilde{\mathbb{T}})]=0$.
When $t_j + m \leq t < t' \leq T$, either (i) $f^m_{\mathbb{T}}(t'-m) = t_j$, in which case $f_{\tilde{\mathbb{T}}}(t'-m) = t_{j-1}$. This is the only difference between $O_{\mathbb{T}}(t, t')$ and $O_{\tilde{\mathbb{T}}}(t, t')$, i.e., $O_{\mathbb{T}}(t, t') - {t_j} = O_{\tilde{\mathbb{T}}}(t, t') - {t_{j-1}}$. $\left| O_{\mathbb{T}}(t, t') \right| = \left| O_{\tilde{\mathbb{T}}}(t, t') \right|$. The second case is (ii) $f_{\mathbb{T}}(t'-m) \geq t_{j+1}$, in which case $O_{\mathbb{T}}(t, t') = O_{\tilde{\mathbb{T}}}(t, t')$ is unchanged. Both cases suggest that $\mathbb{E}[\mathbf{1}t(\mathbb{T}) \mathbf{1}{t'}(\mathbb{T})] - \mathbb{E}[\mathbf{1}t(\tilde{\mathbb{T}}) \mathbf{1}{t'}(\tilde{\mathbb{T}})]=0$.
So we have
$ \begin{align*} & \sum_{m+1 \leq t < t' \leq T} \mathbb{E}\left[\mathbf{1}t(\mathbb{T})\mathbf{1}{t'}(\mathbb{T}) \right] - \sum_{m+1 \leq t < t' \leq T} \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})\mathbf{1}{t'}(\tilde{\mathbb{T}}) \right] \ = & \sum_{\substack{t_{j-1} \leq t \leq t_j-1 \ t_j +m \leq t' \leq t_{j+1}+m-1}} \left(\mathbb{E}\left[\mathbf{1}t(\mathbb{T})\mathbf{1}{t'}(\mathbb{T}) \right] - \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})\mathbf{1}{t'}(\tilde{\mathbb{T}}) \right] \right) + \sum_{t_j \leq t < t' \leq t_j+m-1} \left(\mathbb{E}\left[\mathbf{1}t(\mathbb{T})\mathbf{1}{t'}(\mathbb{T}) \right] - \mathbb{E}\left[\mathbf{1}t(\tilde{\mathbb{T}})\mathbf{1}{t'}(\tilde{\mathbb{T}}) \right] \right) \ \geq & \sum_{\substack{t_{j-1} \leq t \leq t_j-1 \ t_j +m \leq t' \leq t_{j+1}+m-1}} \left(-4B^2 \right) + \sum_{t_j \leq t < t' \leq t_j+m-1} \left(4B^2 \right) \ = & - (t_j - t_{j-1})(t_{j+1} - t_j) 4B^2 + \frac{m(m-1)}{2} 4B^2 \ \geq & 0 \end{align*} $
where the last inequality is because $j \in \mathbb{K}$, $t_{j+1} - t_{j-1} \leq m-1$, so $(t_j - t_{j-1})(t_{j+1} - t_j) \leq \frac{(m-1)^2}{4} \leq \frac{m(m-1)}{2}$.
Combine both square terms and cross-product terms we know that
$ r(\mathbb{T}, \mathbb{Y}) > r(\tilde{\mathbb{T}}, \mathbb{Y}). $
$\square$
10.5.3 Proof of
Lemma 31.
Proof of Lemma 31.: Think of $\mathbb{E}[\mathbf{1}t^2]$ as $\mathbb{E}[\mathbf{1}t \mathbf{1}t]$, so that $r(\eta{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}) = \sum{t=m+1}^T \sum{t'=m+1}^T \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}]$. Then we can decompose the risk function to be
$ \begin{align} (T-m)^2 \cdot r(\eta_{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}) & = \sum_{\substack{m+1 \leq t, t' \leq T \ \min{t, t'} \leq t_1-1}} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] + \sum_{k=1}^{K-1} \left(\sum_{\substack{t_k \leq t, t' \leq T \ \min{t, t'} \leq t_{k+1}-1}} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] \right) + \sum_{t_K \leq t, t' \leq T} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] \end{align}\tag{23} $
The core of this proof is to carefully count how many values can each $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}], \forall t, t' \in {m+1:T}$ take. See Table 11 for an illustration.
::: {caption="Table 11: Illustrator of the different values of $\mathbb{E}[\mathbf{1}_t \mathbf{1}_t]$, when $T=17, m=4, \mathbb{T}={1, 6, 8, 13}$."}
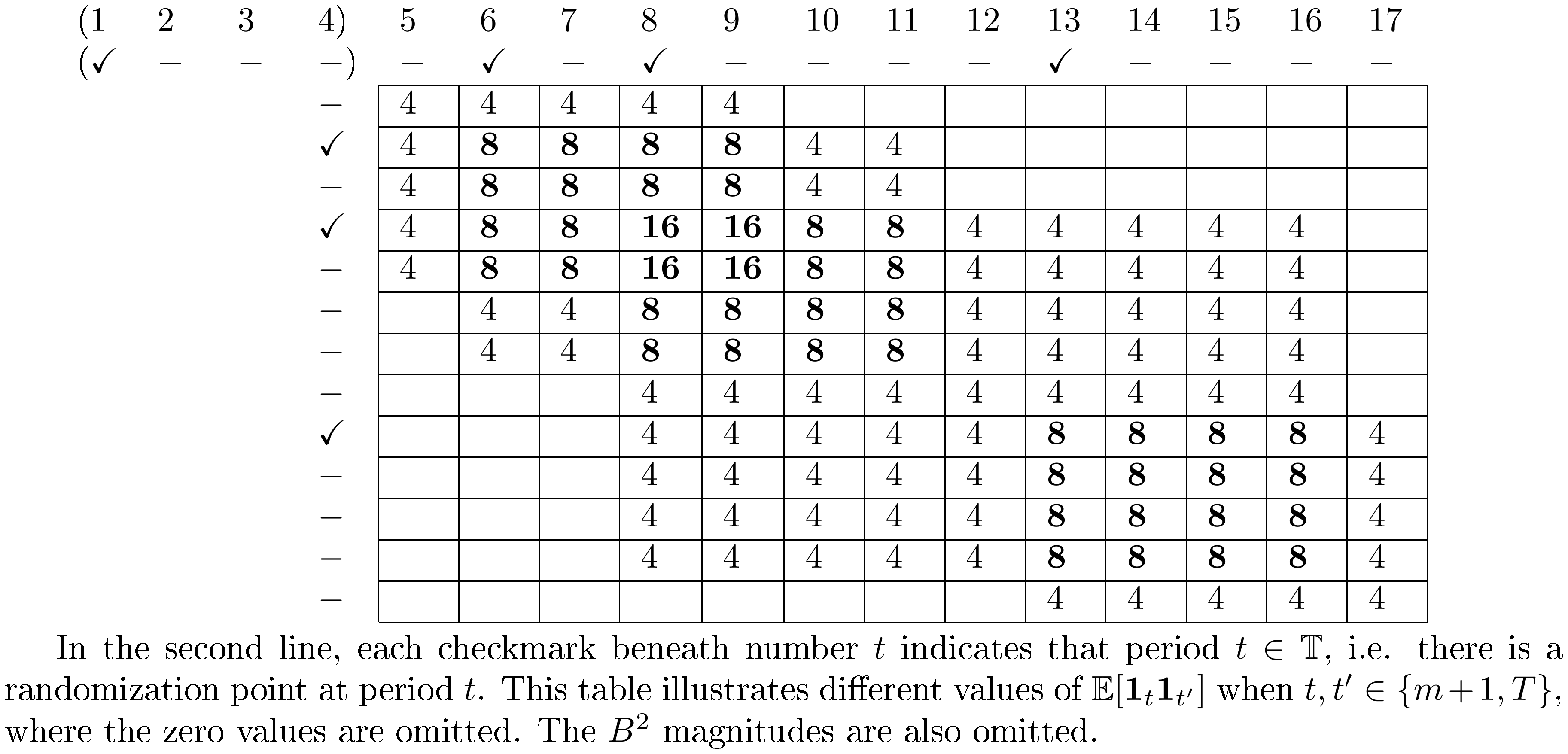
:::
First we calculate the first block from equation 23. Because $t_1 \geq m+2$, for any $t, t'$ such that $m+1 \leq \min{t, t'} \leq t_1 - 1$, $m+1 \leq \max{t, t'} \leq t_1+m-1$, we know that the only overlapping randomization point is $t_0$. So $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 4B^2.$ For any $t, t'$ such that $m+1 \leq \min{t, t'} \leq t_1 - 1$, $t_1+m \leq \max{t, t'} \leq T$, there is no overlapping randomization point so $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 0.$
$ \begin{align*} \sum_{\substack{m+1 \leq t, t' \leq T \ \min{t, t'} \leq t_1-1}} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = B^2 \left(4 \cdot ((t_{1} - 1)^2 - m^2) \right) \end{align*} $
Then we calculate the second block from equation 23. For any $k \in [K-1]$, consider $t_{k} - t_{k-1}$ and $t_{k+1} - t_{k}$, which jointly determine the values of $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}]$ for any $t, t'$, such that $t_k \leq \min{t, t'} \leq t_{k+1}-1$ and $t_k \leq \max{t, t'} \leq T$. We will go over each of the four cases below.
(1) When $t_{k} - t_{k-1} \geq m, t_{k+1} - t_{k} \geq m$. Due to Lemma 28, for all $t, t' \in {t_k : t_k+m-1}$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 8B^2$, because both $t_{k-1} \leq t-m \leq t_k-1$ and $t_{k-1} \leq t'-m \leq t_k-1$, and both $t_{k-1}$ and $t_k$ are overlapping randomization points. For all $t, t'$ such that $t_k \leq \min{t, t'} \leq t_{k+1}-1$ and $t_k+m \leq \max{t, t'} \leq t_{k+1}+m-1$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 4B^2$, because $t_k \leq \min{t, t'} \leq t_{k+1}-1$ and $t_k \leq \max{t, t'}-m \leq t_{k+1}-1$ so only $t_k$ is the overlapping randomization point. For all $t, t'$ such that $t_k \leq \min{t, t'} \leq t_{k+1}-1$ and $t_{k+1}+m \leq \max{t, t'} \leq T$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 0$.
In this case,
$ \begin{align*} \sum_{\substack{t_k \leq t, t' \leq T \ \min{t, t'} \leq t_{k+1}-1}} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = B^2 \left(8 \cdot m^2 + 4 \cdot ((m+t_{k+1} - t_k)^2 - 2m^2) \right) \end{align*} $
(2) When $t_{k} - t_{k-1} \geq m, t_{k+1} - t_{k} < m$. Due to Lemma 28, for all t, $t'$ such that $t_k \leq \min{t, t'} \leq t_{k+1}-1$, $t_k \leq \max{t, t'} \leq t_k+m-1$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 8B^2$, because both $t, t' \leq t_k+m-1$, so $t_{k-1} \leq t-m \leq t_k-1$ and $t_{k-1} \leq t'-m \leq t_k-1$, and both $t_{k-1}$ and $t_k$ are overlapping randomization points. For all $t, t'$ such that $t_k \leq \min{t, t'} \leq t_{k+1}-1$ and $t_k+m \leq \max{t, t'} \leq t_{k+1}+m-1$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 4B^2$, because $t_k \leq \min{t, t'} \leq t_{k+1}-1$ and $t_k \leq \max{t, t'}-m \leq t_{k+1}-1$ so only $t_k$ is the overlapping randomization point. For all $t, t'$ such that $t_k \leq \min{t, t'} \leq t_{k+1}-1$ and $t_{k+1}+m \leq \max{t, t'} \leq T$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 0$.
In this case,
$ \begin{align*} \sum_{\substack{t_k \leq t, t' \leq T \ \min{t, t'} \leq t_{k+1}-1}} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = B^2 \left(8 \cdot (m^2 - (m-t_{k+1}+t_k)^2) + 4 \cdot ((m+t_{k+1} - t_k)^2 - 2m^2 + (m-t_{k+1}-t_k)^2) \right) \end{align*} $
(3) When $t_{k} - t_{k-1} < m, t_{k+1} - t_{k} \geq m$. Due to Lemma 28, for all $t, t' \in {t_k:t_{k-1}+m-1}$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 16B^2$, because $t-m \leq t_{k-1}-1 \leq t_k \leq t$ and $t'-m \leq t_{k-1}-1 \leq t_k \leq t'$ so $t_{k-2}, t_{k-1}, t_k$ are three determining randomization points. Also $t_k - t_{k-2} \geq m$ so $t_{k-2} \leq \min{t, t'}-m$ and $t_{k-3}$ is not a determining randomization point. For all $t, t'$ such that $t_k \leq \min{t, t'} \leq t_k+m-1, t_{k-1}+m \leq \max{t, t'} \leq t_k+m-1$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 8B^2$, because $\min{t, t'} -m \leq t_k-1$ and $t_{k-1} \leq \max{t, t'}-m \leq t_k-1$ so $t_{k-1}$ and $t_k$ are two determining randomization point. For all $t, t'$ such that $t_k \leq \min{t, t'} \leq t_{k+1}-1, t_k+m \leq \max{t, t'} \leq t_{k+1}+m-1$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 4B^2$, because $t_k \leq \max{t, t'}-m$ so $t_k$ is the only determining randomization point. For all $t, t'$ such that $t_k \leq \min{t, t'} \leq t_{k+1}-1, t_{k+1}+m \leq \max{t, t'} \leq T$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 0.$
In this case,
$ \begin{align*} \sum_{\substack{t_k \leq t, t' \leq T \ \min{t, t'} \leq t_{k+1}-1}} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = & B^2 \left(16 \cdot (m-t_k+t_{k-1})^2 + 8 \cdot (m^2 - (m-t_{k}+t_{k-1})^2) \right. \ & \qquad \left. + 4 \cdot ((m+t_{k+1} - t_k)^2 - 2m^2) \right) \end{align*} $
(4) When $t_{k} - t_{k-1} < m, t_{k+1} - t_{k} < m$. Due to Lemma 28, for all $t, t' \in {t_k:t_{k-1}+m-1}$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 16B^2$, because $t-m \leq t_{k-1}-1 \leq t_k \leq t$ and $t'-m \leq t_{k-1}-1 \leq t_k \leq t'$ so $t_{k-2}, t_{k-1}, t_k$ are three determining randomization points. Also $t_k - t_{k-2} \geq m$ so $t_{k-2} \leq \min{t, t'}-m$ and $t_{k-3}$ is not a determining randomization point. For all $t, t'$ such that $t_k \leq \min{t, t'} \leq t_{k+1}-1, t_{k-1}+m \leq \max{t, t'} \leq t_k+m-1$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 8B^2$, because $\min{t, t'} -m < t_k-1$ and $t_{k-1} \leq \max{t, t'}-m \leq t_k-1$ so $t_{k-1}$ and $t_k$ are two determining randomization points. For all $t, t'$ such that $t_k \leq \min{t, t'} \leq t_{k+1}-1, t_k+m \leq \max{t, t'} \leq t_{k+1}+m-1$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 4B^2$, because $t_k \leq \max{t, t'}-m$ so $t_k$ is the only determining randomization point. For all $t, t'$ such that $t_k \leq \min{t, t'} \leq t_{k+1}-1, t_{k+1}+m \leq \max{t, t'} \leq T$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 0.$
In this case,
$ \begin{align*} \sum_{\substack{t_k \leq t, t' \leq T \ \min{t, t'} \leq t_{k+1}-1}} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = & B^2 \left(16 \cdot (m-t_k+t_{k-1})^2 + 8 \cdot (m^2 - (m-t_{k}+t_{k-1})^2 - (m-t_{k+1}+t_k)^2) \right. \ & \qquad \left. + 4 \cdot ((m+t_{k+1} - t_k)^2 - 2m^2 + (m-t_{k+1}+t_k)^2) \right) \end{align*} $
Finally we calculate the third block from equation 23. Observe that $T - t_{K} \geq m$. (1) When $t_{K} - t_{K-1} \geq m$. Due to Lemma 28, for all $t, t' \in {t_K : t_K+m-1}$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 8B^2$, because both $t_{K-1} \leq t-m \leq t_K-1$ and $t_{K-1} \leq t'-m \leq t_K-1$, and both $t_{K-1}$ and $t_K$ are overlapping randomization points. For all $t, t'$ such that $t_K \leq \min{t, t'} \leq T, t_K+m \leq \max{t, t'} \leq T$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 4B^2$, because $t_K \leq \max{t, t'}-m$ so $t_K$ is the only determining randomization point.
In this case,
$ \begin{align*} \sum_{t_K \leq t, t' \leq T} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = B^2 \left(8 \cdot m^2 + 4 \cdot ((T+1 - t_K)^2 - m^2) \right) \end{align*} $
(2) When $t_{K} - t_{K-1} < m$. Due to Lemma 28, for all $t, t' \in {t_K:t_{K-1}+m-1}$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 16B^2$, because $t-m \leq t_{K-1}-1 \leq t_K \leq t$ and $t'-m \leq t_{K-1}-1 \leq t_K \leq t'$ so $t_{K-2}, t_{K-1}, t_K$ are three determining randomization points. Also $t_K - t_{K-2} \geq m$ so $t_{K-2} \leq \min{t, t'}-m$ and $t_{K-3}$ is not a determining randomization point. For all $t, t'$ such that $t_K \leq \min{t, t'} \leq t_K+m-1, t_{K-1}+m \leq \max{t, t'} \leq t_K+m-1$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 8B^2$, because $\min{t, t'} -m \leq t_K-1$ and $t_{K-1} \leq \max{t, t'}-m \leq t_K-1$ so $t_{K-1}$ and $t_K$ are two determining randomization points. For all $t, t'$ such that $t_K \leq \min{t, t'} \leq T, t_K+m \leq \max{t, t'} \leq T$, $\mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = 4B^2$, because $t_K \leq \max{t, t'}-m$ so $t_K$ is the only determining randomization point.
In this case,
$ \begin{align*} \sum_{t_K \leq t, t' \leq T} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] = & B^2 \left(16 \cdot (m-t_K+t_{K-1})^2 + 8 \cdot (m^2 - (m-t_{K}+t_{K-1})^2) + 4 \cdot ((T+1 - t_K)^2 - m^2) \right) \end{align*} $
Now we combine all above together.
Note that whenever there exists $k \in {2:K}$ such that $(t_{k} - t_{k-1}) < m$, this suggests that in $\sum_{\substack{t_k \leq t, t' \leq T \ \min{t, t'} \leq t_{k+1}-1}} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}]$ there is a $16 (m-t_k+t_{k-1})^2$; but in $\sum_{\substack{t_{k-1} \leq t, t' \leq T \ \min{t, t'} \leq t_{k}-1}} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}]$ there is a $8 (-(m-t_k+t_{k-1})^2)$. So when we sum them up, we break $16 (m-t_k+t_{k-1})^2$ into two $8 (m-t_k+t_{k-1})^2$, which cancels in two sumations. By telescoping,
$ \begin{align*} (T-m)^2 \cdot r(\eta_{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}) & = \sum_{\substack{m+1 \leq t, t' \leq T \ \min{t, t'} \leq t_1-1}} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] + \sum_{k=1}^{K-1} \left(\sum_{\substack{t_k \leq t, t' \leq T \ \min{t, t'} \leq t_{k+1}-1}} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] \right) + \sum_{t_K \leq t, t' \leq T} \mathbb{E}[\mathbf{1}t \mathbf{1}{t'}] \ & = 4B^2 \cdot \left((t_1-1)^2-m^2 \right) + \sum_{k=1}^{K-1} B^2 \cdot \left(8 m^2 + 4\left((m+t_{k+1}-t_k)^2 - 2m^2 + \left((m-t_{k+1}+t_k)^+ \right)^2 \right) \right) \ & \qquad + B^2 \cdot \left(8 m^2 + 4\left((T+1-t_K)^2 - m^2 \right) \right) \ & = B^2 \cdot \left{ 4 \sum_{k=0}^{K} (t_{k+1} - t_{k})^2 + 8 m (t_K - t_1) + 4 m^2 K - 4 m^2 + 4 \sum_{k=1}^{K-1} [(m-t_{k+1}+t_{k})^+]^2\right} \end{align*} $
which finishes the proof. $\square$
10.6 Optimal Solutions to the Subset Selection Problem in
Theorem 14
10.6.1 Proof of
Theorem 14.
Proof of Theorem 14.: Consider the problem as we have introduced in Equation 6. Due to Lemma 12, $\mathbb{Y}^{+} = \left{Y_t(\bm{1}{m+1}) = Y_t(\bm{0}{m+1}) = B \right}{t \in {m+1:T}}$ and $\mathbb{Y}^{-} = \left{Y_t(\bm{1}{m+1}) = Y_t(\bm{0}{m+1}) = -B \right}{t \in {m+1:T}}$ are the only two dominating strategies for the adversarial selection of potential outcomes.
Then due to Lemma 29 and Lemma 30, the optimal design of switchback experiment must satisfy the following three conditions.
$ \begin{align*} t_1 \geq m+2, & & t_K \leq T-m & & t_{k+1} - t_{k-1} \geq m, \ \forall k \in [K]. \end{align*} $
Due to Lemma 31, the risk function of the optimal design of experiment is given by
$ \begin{align*} r(\eta_{\mathbb{T}, \mathbb{Q}}, \mathbb{Y}) = \frac{1}{(T-m)^2}\left{ 4 \sum_{k=1}^{K+1} (t_{k} - t_{k-1})^2 + 8 m (t_K - t_1) + 4 m^2 K - 4 m^2 + 4 \sum_{k=2}^{K} [(m-t_k+t_{k-1})^+]^2\right} B^2 \end{align*} $
So if we further take minimum over $\mathbb{T} \subset [T]$ in the above risk function, we find the optimal solution to the original problem introduced in Equation 6. Note that $B^2$ is a constant and irrelevant to our decisions, and that $T$ and $m$ are inputs. So we solve, for any given $T$ and $m$, the following subset selection problem:
$ \begin{align*} \min_{\mathbb{T} \subset [T]} \left{ 4 \sum_{k=0}^{K} (t_{k+1} - t_{k})^2 + 8 m (t_K - t_1) + 4 m^2 K - 4 m^2 + 4 \sum_{k=1}^{K-1} [(m-t_{k+1}+t_{k})^+]^2\right}, \end{align*} $
as stated in Equation 7.
In particular, if there exists some constant $n \in \mathbb{N}, n \geq 4$, such that $T = n m$, we can explicitly find the optimal design of experiment. Take the continuous relaxation of this problem, such that for any $K$, ${1<t_1<t_2<...<t_K<T+1} \in [1, T+1]^K$.
$ \begin{align*} \min_{\substack{K \in \mathbb{N}, \ {1<t_1<t_2<...<t_K<T+1} \in [1, T+1]^K}} \left{ 4 \sum_{k=0}^{K} (t_{k+1} - t_{k})^2 + 8 m (t_K - t_1) + 4 m^2 K - 4 m^2 + 4 \sum_{k=1}^{K-1} [(m-t_{k+1}+t_{k})^+]^2\right} \end{align*} $
The relaxed problem provides a lower bound to the original subset selection problem as stated in Equation 7. We will argue later that it is a lucky coincidence that the optimal solution to this relaxed problem is also an integer solution.
First we argue that $t_1-t_0=t_{K+1}-t_K$. This is because otherwise if $t_1-t_0 \ne t_{K+1}-t_K$ then denote $a = \frac{t_1-t_0+t_{K+1}-t_K}{2}$. We could always pick for any $k \in {1:K}$, $\tilde{t}k = t_k + a - t_1 + 1$, such that $t{k+1} - t_k$ is unchanged for any $k \in {1:K-1}$. The only change in the objective value comes from
$ \left(2a^2\right) - \left((t_1 - t_0)^2 + (t_{K+1}-t_K)^2 \right) < 0, $
which suggests that $t_1-t_0 \ne t_{K+1}-t_K$ is not optimal.
Second, similarly, we argue that for any $k' < k'' \in [K-1]$, $t_{k'+1} - t_{k'} = t_{k''+1} - t_{k''}$ This is because otherwise if $t_{k'+1}-t_{k'} \ne t_{k''+1}-t_{k''}$ then denote $b = \frac{t_{k'+1}-t_{k'}+t_{k''+1}-t_{k''}}{2}$. We could always pick for any $k \in {k'+1:k''}$, $\tilde{t}k = t_k + b - (t{k'+1} - t_{k'})$, such that $t_{k+1} - t_k$ is unchanged for any $k \in {k'+1:k''-1}$. The only change in the objective value comes from
$ \left(2b^2 + 2((m-b)^+)^2\right) - \left((t_{k'+1}-t_{k'})^2 + (t_{k''+1}-t_{k''})^2 + ((m-t_{k'+1}+t_{k'})^+)^2 + ((m-t_{k''+1}+t_{k''})^+)^2 \right) < 0, $
where $x^2+((m-x)^+)^2$ is convex and the inequality holds due to Jensen's Inequality. This inequality suggests that $t_{k'+1}-t_{k'} \ne t_{k''+1}-t_{k''}$ is not optimal.
With the above two structural results, we can assume that there exists $a, b > 0$, such that $t_1-t_0 = t_{K+1}-t_K = a$, and $t_{k+1}-t_{k} = b, \forall k \in [K-1]$ Also, it must be satisfied that $2a+(K-1)b = T$. Next we replace $K-1=\frac{T-2a}{b}$ into the relaxed problem, to have
$ \begin{align*} \min_{a, b>0} & \left{ 4 (2 a^2 + (K-1)b^2) + 8 m (K-1) b + 4 m^2 (K-1) + 4 (K-1) ((m-b)^+)^2\right} \ = \min_{a, b>0} & \left{ 8 a^2 + 4 (T-2a)b + 8 m (T-2a) + 4 m^2 \frac{T-2a}{b} + 4 \frac{T-2a}{b} ((m-b)^+)^2\right} \end{align*} $
Either when $b \geq m$, the above is to minimize
$ \begin{align*} \min_{a, b>0} & \left{ 8 a^2 + 4 (T-2a)b + 8 m (T-2a) + 4 m^2 \frac{T-2a}{b} \right} \end{align*} $
Note that
$ \begin{align*} 8 a^2 + 4 (T-2a)b + 8 m (T-2a) + 4 m^2 \frac{T-2a}{b} = & 8 a^2 + 8 m (T-2a) + 4 (T-2a) \left(b+ \frac{m^2}{b}\right) \ \geq & 8 a^2 + 16 m (T-2a) \ = & 8 (a-2m)^2 +16mT -32m^2 \ \geq & 16mT -32m^2 \end{align*} $
where the first inequality takes equality if and only if $b = \frac{m^2}{b}$, which suggests $b=m$; the second inequality takes equality if and only if $a=2m$.
Or when $b \leq m$, the above is to minimize
$ \begin{align*} \min_{a, b>0} & \left{ 8 a^2 + 4 (T-2a)b + 8 m (T-2a) + 4 m^2 \frac{T-2a}{b} + 4 \frac{T-2a}{b} (m-b)^2 \right} \end{align*} $
Note that
$ \begin{align*} 8 a^2 + 4 (T-2a)b + 8 m (T-2a) + 4 m^2 \frac{T-2a}{b} + 4 \frac{T-2a}{b} (m-b)^2 = & 8 a^2 + 8 (T-2a) \left(b + \frac{m^2}{b} \right) \ \geq & 8 a^2 + 16 m (T-2a) \ = & 8 (a-2m)^2 +16mT -32m^2 \ \geq & 16mT -32m^2 \end{align*} $
where the first inequality takes equality if and only if $b = \frac{m^2}{b}$, which suggests $b=m$; the second inequality takes equality if and only if $a=2m$.
Combining both cases, the optimal solution is when $a=2m$ and $b=m$, which happens to be an integer solution, thus optimal for the subset selection problem. Translating into $t_1, ..., t_K$ this suggests that $t_1 = 2m+1, t_2 = 3m+1, ..., t_K = (n-2)m+1$. $\square$
10.6.2 Solutions in the Imperfect Cases.
It is always worth noting that we are taking a design of experiments perspective. So when practically we have control of $T$, we can pick $T$ to be some multiples of $m$, which fits our Theorem 14 perfectly. If we do not have control of $T$, we can always pick a smaller $T'$ such that $T' = \lfloor T/m \rfloor \cdot m$ is some multiples of $m$.
Nonetheless, from an optimization perspective, we establish the following optimal structure for the subset selection problem as in Equation 7. Recall that $t_{K+1}=T+1$.
Lemma 32
Under Assumptions Assumption 2–Assumption 11, the optimal design of regular switchback experiment must satisfy the following two conditions,
$ \begin{align*} \left| (t_1-t_0) - (t_{K+1}-t_K) \right| \leq 1, & & \left| (t_{j+1}-t_j) - (t_{j'+1}-t_{j'}) \right| \leq 1, \forall 1 \leq j, j' \leq K-1. \end{align*} $
Proof of Lemma 32.: Prove by contradiction.
Case 1. Suppose there exists some optimal design $\mathbb{T}$, such that $(t_1-t_0) - (t_{K+1}-t_K) \geq 2$. We now construct another design $\tilde{\mathbb{T}}$, such that $\left| \tilde{\mathbb{T}} \right| = K = \left| \mathbb{T} \right|$, and the $K$ elements are $\tilde{\mathbb{T}} = {\tilde{t}_0 = 1, \tilde{t}_1 = t_1-1, \tilde{t}_2 = t_2-1, ..., \tilde{t}K = t_K-1}$. Now check the expression as in Equation 7. Note that $\tilde{t}{k+1} - \tilde{t}k = t{k+1} - t_k$ is unchanged for any $k\in[K-1]$; $\tilde{t}K - \tilde{t}1 = t_K - t_1$ is unchanged; and $m- \tilde{t}{k+1} - \tilde{t}k = m- t{k+1} - t_k$ in unchanged for any $k\in[K-1]$. But $(\tilde{t}1 - \tilde{t}0)^2 + (\tilde{t}{K+1} - \tilde{t}K)^2 = (t_1 - t_0 - 1)^2 + (t{K+1} - t_K + 1)^2 \leq (t_1 - t_0)^2 + (t{K+1} - t_K)^2$, because $(t_1 - t_0) - (t{K+1} - t_K) \geq 2$ and due to convexity.
Similarly, if there exists some optimal design $\mathbb{T}$, such that $(t_{K+1}-t_K) - (t_1-t_0) \geq 2$, then construct another design $\tilde{\mathbb{T}} = {\tilde{t}_0 = 1, \tilde{t}_1 = t_1+1, \tilde{t}_2 = t_2+1, ..., \tilde{t}_K = t_K+1}$.
Case 2. Suppose there exists some optimal design $\mathbb{T}$, and there exists $1 \leq j < j' \leq K-1$ such that $(t_{j+1}-t_j) - (t_{j'+1}-t_{j'}) \geq 2$. We now construct another design $\tilde{\mathbb{T}}$, such that $\left| \tilde{\mathbb{T}} \right| = K = \left| \mathbb{T} \right|$, and the $K$ elements are $\tilde{\mathbb{T}} = {\tilde{t}0 = 1, \tilde{t}1 = t_1, ..., \tilde{t}j = t_j, \tilde{t}{j+1} = t{j+1}-1, ..., \tilde{t}{j'} = t_{j'}-1, \tilde{t}{j'+1} = t{j'+1}, ..., \tilde{t}K = t_K}$. Now check the expression as in Equation 7. Note that $\tilde{t}{k+1} - \tilde{t}k = t{k+1} - t_k$ is unchanged for any $k\in{0:K}$ except $j$ and $j'$; $\tilde{t}_K - \tilde{t}1 = t_K - t_1$ is unchanged; and $m- \tilde{t}{k+1} - \tilde{t}k = m- t{k+1} - t_k$ in unchanged for any $k\in[K-1]$ except $j$ and $j'$. Now focus on $j$ and $j'$.
$ \begin{align*} & (\tilde{t}{j+1} - \tilde{t}j)^2 + (\tilde{t}{j'+1} - \tilde{t}{j'})^2 + [(m - \tilde{t}{j+1} + \tilde{t}{j})^+]^2 + [(m - \tilde{t}{j'+1} + \tilde{t}{j'})^+]^2 \ = & (t_{j+1} - t_j - 1)^2 + (t_{j'+1} - t_{j'} + 1)^2 + [(m - t_{j+1} + t_{j} + 1)^+]^2 + [(m - t_{j'+1} + t_{j'} - 1)^+]^2 \ \leq & (t_{j+1} - t_j)^2 + (t_{j'+1} - t_{j'})^2 + [(m - t_{j+1} + t_{j})^+]^2 + [(m - t_{j'+1} + t_{j'})^+]^2 \end{align*} $
To see why this inequality holds, define $g(x)=x^2+[(m-x)^+]^2$ and note that $g(x)$ is a univariate convex function. The inequality holds due to $(t_{j+1}-t_j) - (t_{j'+1}-t_{j'}) \geq 2$ and convexity.
Similarly, if there exists some optimal design $\mathbb{T}$, and there exists $1 \leq j < j' \leq K-1$ such that $(t_{j'+1}-t_{j'}) - (t_{j+1}-t_j) \geq 2$. Then construct another design $\tilde{\mathbb{T}} = {\tilde{t}0 = 1, \tilde{t}1 = t_1, ..., \tilde{t}j = t_j, \tilde{t}{j+1} = t{j+1}+1, ..., \tilde{t}{j'} = t_{j'}+1, \tilde{t}{j'+1} = t{j'+1}, ..., \tilde{t}_K = t_K}$.
Combine both cases we finish the proof. $\square$
11. Proofs and Discussions from Section 4
Section Summary: This section offers detailed mathematical proofs and explanations supporting the findings in Section 4 of the paper, focusing initially on scenarios where the carryover effect's order matches the experimenter's prior knowledge. It introduces simplified notations to group indicator variables into blocks spanning multiple time periods, which helps express the treatment effect estimator and its variance more manageably. The core proof for Lemma 17 decomposes the variance into terms for individual blocks and pairwise interactions between adjacent ones, deriving specific formulas by considering the probabilities of various randomization outcomes.
In the first two sub-Sections of Section 4 we focus on the case when $p=m$. In Section 11.1–Section 11.4 in the appendix, we also focus on the case when $p=m$, and use only $m$ instead of $p$. In Section 11.4–Section 11.6, we will use both $p$ and $m$. Recall that $m$ is the order of the carryover effect, and $p$ is the experimenter's knowledge of $m$.
11.1 Extra Notations Used in the Proofs from Section 4
For any $t \in {m+1:T}$, we use the notations of $\mathbf{1}_t$ as defined in Equation 16. Denote
$ \begin{align*} \bar{\mathbf{1}}0 = & \sum{t=m+1}^{2m} \mathbf{1}t & & \ \bar{\mathbf{1}}k = & \sum{t=(k+1)m+1}^{(k+2)m} \mathbf{1}t, & & \forall k \in [K] \ \bar{\mathbf{1}}{K+1} = & \sum{t=(K+2)m+1}^{(K+3)m} \mathbf{1}_t & & \end{align*} $
It is worth noting that under the optimal design as suggested by Theorem 14, when $T/m = n \in \mathbb{N}$ is an integer, we have $K = n-3$. So $(K+3)m = T$. See Example Section 11.1 below.
Example 33: An Optimal Design and Its $\bar{\mathbf{1}}_k$ Notations
When $T=12$, $p=m=2$, the optimal design of regular switchback experiment is $\mathbb{T}^*={1, 5, 7, 9}$, and $K=3$.
The $\bar{\mathbf{1}}_k$ notations are defined below.
Each $\bar{\mathbf{1}}_k$ spans $m=2$ periods.
See Table 12.
::: {caption="Table 12: An example of the optimal design $\mathbb{T}^*$ and its $\bar{\mathbf{1}}_k$ notations when $T=12$ and $p=m=2$."}

:::
$\square$ Using the above notation, we could write
$ \begin{align*} \widehat{\tau}m - \tau_m = \frac{1}{T-m} \sum{k=0}^{K+1} \bar{\mathbf{1}}_k, \end{align*} $
and so
$ \begin{align*} \mathsf{Var}(\widehat{\tau}m) = \frac{1}{(T-m)^2} \mathsf{Var} \left(\sum{k=0}^{K+1} \bar{\mathbf{1}}_k \right). \end{align*} $
11.2 Proof of
Lemma 17
The proof of Lemma 17 resembles the proof of Lemma 25 and Lemma 26. The trick here is to observe that for any $k \in [K]$, the values of all the variables $\mathbf{1}_t$, where $(k+1)m+1 \leq t \leq (k+2)m$, are all determined by the randomization at time $km+1$ and $(k+1)m+1$. Since they are all correlated, we can use $\bar{\mathbf{1}}k$ to stand for $\sum{t=(k+1)m+1}^{(k+2)m} \mathbf{1}_t$ for short.
Proof of Lemma 17.: First observe that $\bar{\mathbf{1}}_k$ has zero mean for each $k \in {0:K+1}$. So we can decompose the variance into squared terms and cross-product terms,
$ \begin{align*} (T-m)^2 \mathsf{Var}(\widehat{\tau}m) = \mathsf{Var} \left(\sum{k=0}^{K+1} \bar{\mathbf{1}}k \right) = \sum{k=0}^{K+1} \mathbb{E}\left[\bar{\mathbf{1}}k^2\right] + \sum{0 \leq k < k' \leq K+1} 2 \mathbb{E}\left[\bar{\mathbf{1}}k \bar{\mathbf{1}}{k'}\right]. \end{align*} $
We focus on the variance of the squared terms first,
$ \begin{align*} \mathbb{E}\left[\bar{\mathbf{1}}k^2\right] = \left{ \begin{aligned} & \bar{Y}0(\bm{1}{m+1})^2 + \bar{Y}0(\bm{0}{m+1})^2 + 2 \bar{Y}0(\bm{1}{m+1}) \bar{Y}0(\bm{0}{m+1}), & & \text{if \ } k=0 \ & 3 \bar{Y}k(\bm{1}{m+1})^2 + 3 \bar{Y}k(\bm{0}{m+1})^2 + 2 \bar{Y}k(\bm{1}{m+1}) \bar{Y}k(\bm{0}{m+1}), & & \text{if \ } 1 \leq k \leq K \ & \bar{Y}{K+1}(\bm{1}{m+1})^2 + \bar{Y}{K+1}(\bm{0}{m+1})^2 + 2 \bar{Y}{K+1}(\bm{1}{m+1}) \bar{Y}{K+1}(\bm{0}_{m+1}), & & \text{if \ } k=K+1 \ \end{aligned} \right. \end{align*} $
This is because when $k=0$ or $k=K+1$, then with probability $1/2$, $\bar{\mathbf{1}}_k = \bar{Y}0(\bm{1}{m+1}) + \bar{Y}0(\bm{0}{m+1})$; with probability $1/2$, $\bar{\mathbf{1}}_k = - \bar{Y}0(\bm{1}{m+1}) - \bar{Y}0(\bm{0}{m+1})$. When $k\in[K]$, with probability $1/4$, $\bar{\mathbf{1}}_k = 3 \bar{Y}0(\bm{1}{m+1}) + \bar{Y}0(\bm{0}{m+1})$; with probability $1/2$, $\bar{\mathbf{1}}_k = - \bar{Y}0(\bm{1}{m+1}) + \bar{Y}0(\bm{0}{m+1})$; with probability $1/4$, $\bar{\mathbf{1}}_k = - \bar{Y}0(\bm{1}{m+1}) -3 \bar{Y}0(\bm{0}{m+1})$.
Then for the cross-product terms, if $k' - k \geq 2$, then $\bar{\mathbf{1}}k$ and $\bar{\mathbf{1}}{k'}$ are independent, i.e., $\mathbb{E}\left[\bar{\mathbf{1}}k \bar{\mathbf{1}}{k'}\right] = 0$. If $k' - k = 1$, then
$ \begin{align*} \mathbb{E}\left[\bar{\mathbf{1}}k \bar{\mathbf{1}}{k+1}\right] = (\bar{Y}{k}(\bm{1}{m+1}) + \bar{Y}{k}(\bm{0}{m+1})) \cdot (\bar{Y}{k+1}(\bm{1}{m+1}) + \bar{Y}{k+1}(\bm{0}{m+1})) \end{align*} $
This is because the values of $\bar{\mathbf{1}}k$ and $\bar{\mathbf{1}}{k+1}$ are determined by the realization at $3$ randomization points, $W_{km+1}, W_{(k+1)m+1}, W_{(k+2)m+1}$. With probability $1/8$, $\bar{\mathbf{1}}k \bar{\mathbf{1}}{k+1} = (3 \bar{Y}{k}(\bm{1}{m+1}) + \bar{Y}{k}(\bm{0}{m+1})) \cdot (3 \bar{Y}{k+1}(\bm{1}{m+1}) + \bar{Y}{k+1}(\bm{0}{m+1}))$; with probability $1/8$, $\bar{\mathbf{1}}k \bar{\mathbf{1}}{k+1} = (3 \bar{Y}{k}(\bm{1}{m+1}) + \bar{Y}{k}(\bm{0}{m+1})) \cdot (- \bar{Y}{k+1}(\bm{1}{m+1}) + \bar{Y}{k+1}(\bm{0}{m+1}))$; with probability $1/8$, $\bar{\mathbf{1}}k \bar{\mathbf{1}}{k+1} = (- \bar{Y}{k}(\bm{1}{m+1}) + \bar{Y}{k}(\bm{0}{m+1})) \cdot (3 \bar{Y}{k+1}(\bm{1}{m+1}) + \bar{Y}{k+1}(\bm{0}{m+1}))$; with probability $1/8$, $\bar{\mathbf{1}}k \bar{\mathbf{1}}{k+1} = (- \bar{Y}{k}(\bm{1}{m+1}) + \bar{Y}{k}(\bm{0}{m+1})) \cdot (- \bar{Y}{k+1}(\bm{1}{m+1}) + \bar{Y}{k+1}(\bm{0}{m+1}))$; with probability $1/8$, $\bar{\mathbf{1}}k \bar{\mathbf{1}}{k+1} = (- \bar{Y}{k}(\bm{1}{m+1}) + \bar{Y}{k}(\bm{0}{m+1})) \cdot (- \bar{Y}{k+1}(\bm{1}{m+1}) + \bar{Y}{k+1}(\bm{0}{m+1}))$; with probability $1/8$, $\bar{\mathbf{1}}k \bar{\mathbf{1}}{k+1} = (- \bar{Y}{k}(\bm{1}{m+1}) + \bar{Y}{k}(\bm{0}{m+1})) \cdot (- \bar{Y}{k+1}(\bm{1}{m+1}) -3 \bar{Y}{k+1}(\bm{0}{m+1}))$; with probability $1/8$, $\bar{\mathbf{1}}k \bar{\mathbf{1}}{k+1} = (- \bar{Y}{k}(\bm{1}{m+1}) -3 \bar{Y}{k}(\bm{0}{m+1})) \cdot (- \bar{Y}{k+1}(\bm{1}{m+1}) + \bar{Y}{k+1}(\bm{0}{m+1}))$; with probability $1/8$, $\bar{\mathbf{1}}k \bar{\mathbf{1}}{k+1} = (- \bar{Y}{k}(\bm{1}{m+1}) -3 \bar{Y}{k}(\bm{0}{m+1})) \cdot (- \bar{Y}{k+1}(\bm{1}{m+1}) -3 \bar{Y}{k+1}(\bm{0}{m+1}))$.
Combining the squared terms and the cross-product terms we finish the proof. $\square$
11.3 Discssions and proof of
Corollary 18
We first provide the details of the two variance upper bounds here.
$ \begin{split} \mathsf{Var}^\mathsf{U1}(\widehat{\tau}m) = \frac{1}{(T-m)^2} \left{ 3 \left[\bar{Y}0(\bm{1}{m+1})^2 + \bar{Y}0(\bm{0}{m+1})^2 \right] + \sum{k=1}^{n-3} 6 \left[\bar{Y}k(\bm{1}{m+1})^2 + \bar{Y}k(\bm{0}{m+1})^2 \right] \right.\
- \left. 4 \left[\bar{Y}{n-2}(\bm{1}{m+1})^2 + \bar{Y}{n-2}(\bm{0}{m+1})^2 \right] + \sum_{k=0}^{n-3} 2 \left[\bar{Y}k(\bm{1}{m+1}) \cdot \bar{Y}{k+1}(\bm{1}{m+1}) + \bar{Y}k(\bm{0}{m+1}) \cdot \bar{Y}{k+1}(\bm{0}{m+1}) \right] \right}, \end{split} $
and
$ \begin{split} \mathsf{Var}^\mathsf{U2}(\widehat{\tau}m) = \frac{1}{(T-m)^2} \left{ 4 \left[\bar{Y}0(\bm{1}{m+1})^2 + \bar{Y}0(\bm{0}{m+1})^2 \right] + \sum{k=1}^{n-3} 8 \left[\bar{Y}k(\bm{1}{m+1})^2 + \bar{Y}k(\bm{0}{m+1})^2 \right] \right. \
- \left. 4 \left[\bar{Y}{n-2}(\bm{1}{m+1})^2 + \bar{Y}{n-2}(\bm{0}{m+1})^2 \right] \vphantom{\sum_{k=1}^{n-3}} \right}. \end{split} $
We prove Corollary 18 using the basic inequality that $2 x y \leq x^2 + y^2$. Such an inequality is commonly used to find a conservative upper bound of the variance.
Proof of Corollary 18.: From Lemma 17, the variance of the estimator is given by
$ \begin{align*} & (T-m)^2 \mathsf{Var}(\widehat{\tau}m) \ \leq & 2 \left{ \bar{Y}0(\bm{1}{m+1})^2 + \bar{Y}0(\bm{0}{m+1})^2 \right} + \sum{k=1}^{n-3} 4 \left{ \bar{Y}k(\bm{1}{m+1})^2 + \bar{Y}k(\bm{0}{m+1})^2 \right} + 2 \left{ \bar{Y}{n-2}(\bm{1}{m+1})^2 + \bar{Y}{n-2}(\bm{0}{m+1})^2 \right} \ & + \sum_{k=0}^{n-3} 2 \left[\bar{Y}k(\bm{1}{m+1}) + \bar{Y}k(\bm{0}{m+1}) \right] \cdot \left[\bar{Y}{k+1}(\bm{1}{m+1}) + \bar{Y}{k+1}(\bm{0}{m+1})\right] \ \leq & 2 \left{ \bar{Y}0(\bm{1}{m+1})^2 + \bar{Y}0(\bm{0}{m+1})^2 \right} + \sum_{k=1}^{n-3} 4 \left{ \bar{Y}k(\bm{1}{m+1})^2 + \bar{Y}k(\bm{0}{m+1})^2 \right} + 2 \left{ \bar{Y}{n-2}(\bm{1}{m+1})^2 + \bar{Y}{n-2}(\bm{0}{m+1})^2 \right} \ & + \sum_{k=0}^{n-3} \left{ 2 \bar{Y}k(\bm{1}{m+1})\bar{Y}{k+1}(\bm{1}{m+1}) + 2 \bar{Y}k(\bm{0}{m+1})\bar{Y}{k+1}(\bm{0}{m+1}) + \bar{Y}k(\bm{1}{m+1})^2 + \bar{Y}k(\bm{0}{m+1})^2 + \bar{Y}{k+1}(\bm{1}{m+1})^2 + \bar{Y}{k+1}(\bm{0}{m+1})^2 \right} \ \leq & 3 \left{ \bar{Y}0(\bm{1}{m+1})^2 + \bar{Y}0(\bm{0}{m+1})^2 \right} + \sum_{k=1}^{n-3} 6 \left{ \bar{Y}k(\bm{1}{m+1})^2 + \bar{Y}k(\bm{0}{m+1})^2 \right} + 3 \left{ \bar{Y}{n-2}(\bm{1}{m+1})^2 + \bar{Y}{n-2}(\bm{0}{m+1})^2 \right} \ & + \sum_{k=0}^{n-3} \left{ \bar{Y}k(\bm{1}{m+1})^2 + \bar{Y}k(\bm{0}{m+1})^2 + \bar{Y}{k+1}(\bm{1}{m+1})^2 + \bar{Y}{k+1}(\bm{0}{m+1})^2 \right} \ = & 4 \left{ \bar{Y}0(\bm{1}{m+1})^2 + \bar{Y}0(\bm{0}{m+1})^2 \right} + \sum_{k=1}^{n-3} 8 \left{ \bar{Y}k(\bm{1}{m+1})^2 + \bar{Y}k(\bm{0}{m+1})^2 \right} + 4 \left{ \bar{Y}{n-2}(\bm{1}{m+1})^2 + \bar{Y}{n-2}(\bm{0}{m+1})^2 \right} \end{align*} $
where the first inequality suggests $\mathsf{Var}(\widehat{\tau}_m) \leq \mathsf{Var}^{\mathsf{U1}}(\widehat{\tau}_m)$, and the last inequality suggests $\mathsf{Var}^{\mathsf{U1}}(\widehat{\tau}_m) \leq \mathsf{Var}^{\mathsf{U2}}(\widehat{\tau}_m)$.
The unbiasedness part is due to the estimator of the variances being Horvitz-Thompson type estimators. $\square$
11.4 Proof of
Theorem 20
We prove Theorem 20 by using Lemma 23. In particular, we derive $B_{n, k, a}^2$, and then construct some proper $\Delta_n, K_n$, and $L_n$.
Proof of Theorem 20.: In the $n$-replica experiment, $\widehat{\tau}m - \tau_m = \frac{1}{(n-1)m} \sum{k=0}^{n-2} \bar{\mathbf{1}}k$, and $\mathsf{Var}(\widehat{\tau}m) = \frac{1}{(n-1)^2m^2} \mathsf{Var}\left(\sum{k=0}^{n-2} \bar{\mathbf{1}}k \right)$. To use the language from Lemma 23, denote $d=n-1$. Denote for any $i \in [n-1]$, $X{n, i} = \frac{1}{(n-1)m} \bar{\mathbf{1}}{i-1}$ so we know that $\phi = 1$, i.e., ${X_{n, 1}, X_{n, 2}, ...}$ is a sequence of $1$-dependent random variables.
First note that $B_{n}^2 = \mathsf{Var}(\widehat{\tau}m)$, and we calculate $B{n, k, a}^2$ as follows.
$ \begin{align*} B^2_{n, k, a} & = \frac{1}{(n-1)^2 m^2} \mathsf{Var}\left(\sum_{i=a}^{a+k-1} \bar{\mathbf{1}}{i-1} \right) \ & \leq \frac{1}{(n-1)^2 m^2} \left{ \sum{i=a}^{a+k-1} \left[3 \bar{Y}{i-1}(\bm{1}{m+1})^2 + 3 \bar{Y}{i-1}(\bm{0}{m+1})^2 + 2 \bar{Y}{i-1}(\bm{1}{m+1}) \bar{Y}{i-1}(\bm{0}{m+1}) \right]\right. \ & \qquad \qquad \qquad \quad + \left. \sum_{i=a}^{a+k-2} 2 [\bar{Y}{i-1}(\bm{1}{m+1}) + \bar{Y}{i-1}(\bm{0}{m+1})] \cdot [\bar{Y}{i}(\bm{1}{m+1}) + \bar{Y}{i}(\bm{0}{m+1})] \right} \ & \leq \frac{8 k m^2 B^2 + 8 (k-1) m^2 B^2}{(n-1)^2 m^2} \ & \leq \frac{16 k B^2}{(n-1)^2} \end{align*} $
Pick $\gamma = 0, \delta = 1$, then $\Delta_n = B^3 / (n-1)^3$, $K_n = 16B^2 / (n-1)^2$, and $L_n = \mathsf{Var}(\widehat{\tau}_m) / (n-1)$.
We check that all the five conditions from Lemma 23 are satisfied.
- $\mathbb{E}\left| X_{n, i} \right|^3 \leq \Delta_n = B^3 / (n-1)^3$, because all the potential outcomes are bounded by $B$, so that $X_{n, i} \leq B/(n-1)$.
- $B^2_{n, k, a}/ k \leq K_n = 16B^2 / (n-1)^2$.
- $B_n^2/(n-1) \geq L_n = \mathsf{Var}(\widehat{\tau}_m) / (n-1)$.
- $K_n / L_n = 16B^2 / (n-1) \mathsf{Var}(\widehat{\tau}_m) = O(1)$, where the last equality is due to Assumption 19.
- $\Delta_n / L_n^{3/2} = B^3 / (n-1)^{3/2} \mathsf{Var}(\widehat{\tau}_m)^{3/2} = O(1)$, where the last equality is due to Assumption 19.
Due to Lemma 23,
$ \begin{align*} \frac{\widehat{\tau}_m - \tau_m}{\sqrt{\mathsf{Var}(\widehat{\tau}_m)}} \xrightarrow[]{D} \mathcal{N}(0, 1). \end{align*} $
$\square$ ### Interpretation for the Horvitz-Thompson Estimator under Misspecified $m$ Case
For the remainder of this section, we discuss the cases when $m$ is misspecified. Throughout this section in the appendix, we use both $p$ and $m$. Recall that $m$ is the order of the carryover effect, and $p$ is the experimenter's knowledge of $m$.
As we have discussed in Section 4.3, all our estimation and inference methods will hold when $p \geq m$. When $p<m$, the Horvitz-Thompson estimator as we defined in Equation 4 will no longer be unbiased in estimating the lag- $p$ causal estimand as we defined in Equation 1. However, we can still interpret the Horvitz-Thompson estimator as we defined in Equation 4.
When $p<m$, the lag- $p$ effect in Equation 1 is not well defined. Instead, we define the $m$-misspecified lag- $p$ causal effect that pads the $p+1$ assignments with the earlier observed treatments.
$ \begin{split} \tau_p^{(m)}(\mathbb{Y}) = \frac{1}{T-p} \left{\sum_{t=p+1}^m \left[Y_t(\bm{w}^\mathsf{obs}{1:t-p-1}, \bm{1}{p+1}) - Y_t(\bm{w}^\mathsf{obs}{1:t-p-1}, \bm{0}{p+1}) \right] + \right. \ \left. \sum_{t=m+1}^{T} \left[Y_t(\bm{w}{t-m:t-p-1}^{\mathsf{obs}}, \bm{1}{p+1}) - Y_t(\bm{w}{t-m:t-p-1}^{\mathsf{obs}}, \bm{0}{p+1}) \right] \right}. \end{split}\tag{24} $
This is a special case of the weighted lag- $p$ causal effect introduced in [34]. Similarly to the average lag- $p$ causal effect, $\tau_p^{(m)}(\mathbb{Y})$ captures how administering $p+1$ consecutive treatments as opposed to $p+1$ consecutive controls impact the outcomes at time $t$, conditional on the observed assignment path up to time $t-p-1$.[^7] See Section 5.5 for numerical results.
[^7]: See ([34], Section 3) for an extended discussion.
When $p>m$, Proposition 9 still holds, i.e., $\mathbb{E}[\widehat{\tau}_p] = \tau_p(\mathbb{Y}) = \tau_m(\mathbb{Y})$. When $p<m$, sometimes we have to slightly augment the results and study the conditional expectation.
Define $f_\mathbb{T}: [T] \to \mathbb{T}$ to be the "determining randomization point of period $t$, "
$ f_\mathbb{T}(t) = \max \left{ j \left| j \in \mathbb{T}, j \leq t \right. \right} $
such that, it is the realization at time $f_\mathbb{T}(t)$ that uniquely determines the assignment at time $t$, i.e. $W_t = W_{f_\mathbb{T}(t)}, \forall t \in [T]$. See Example Section 4.3 for an illustration of $f_\mathbb{T}(\cdot)$. When $\mathbb{T}$ is clear from the context we drop the subscript and use $f(\cdot) = f_{\mathbb{T}}(\cdot)$. Depending on if $f(t-p) \leq t-m$, we establish an analogy of Proposition 9 for the $p<m$ case.
Proposition 34: Conditional Unbiasedness of the Estimator when $m$ is Misspecified
Under Assumptions Assumption 2 and Assumption 4, for $p<m$, at each time $t \geq m+1$, the Horvitz-Thompson estimator is either unbiased for the lag- $m$ causal effect when $f(t-p) \leq t-m$, or conditionally unbiased for the $m$-misspecified lag- $p$ causal effect when $f(t-p) > t-m$.
When $p+1 \leq t \leq m$, the Horvitz-Thompson estimator is either unbiased for the lag- $t$ causal effect when $f(t-p) = 1$, or conditionally unbiased for the $m$-misspecified lag- $t$ causal effect when $f(t-p) > 1$.
To remove the conditional expectation, we can further take an outer loop of expectation averaged over the past assignment paths. Although this is somewhat different from the average lag- $p$ effect introduced earlier in Equation 1, it does capture the impact of a sequence of treatment relative to a sequence of controls.
All the mathematical expressions of Proposition 34, as well its proof, are stated in Section 11.5 in the Appendix. See Example Section 4.3 below for a specific illustration of Proposition 34. For a numerical illustration of the estimand and estimator in more general setups, see Section 5.5.
Example 35: Misspecified $m$
Suppose $T=4, m=2, p=1, \mathbb{T}={1, 3}$. Then the determining randomization points are $f_\mathbb{T}(1) = 1, f_\mathbb{T}(2) = 1, f_\mathbb{T}(3) = 3, f_\mathbb{T}(4) = 3$, and
$ \begin{align*} \mathbb{E}\left[Y_2^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{1:2} = (1, 1)}}}{\Pr(\bm{W}{1:2} = (1, 1))} - Y_2^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{1:2} = (0, 0)}}}{{\Pr(\bm{W}{1:2} = (0, 0))}} \right] & = Y_2(1, 1) - Y_2(0, 0) \ \mathbb{E}\left[Y_3^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{2:3} = (1, 1)}}}{\Pr(\bm{W}{2:3} = (1, 1))} - Y_3^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{2:3} = (0, 0)}}}{{\Pr(\bm{W}{2:3} = (0, 0))}} \right] & = Y_3(1, 1, 1) - Y_3(0, 0, 0) \ \mathbb{E}\left[Y_4^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{3:4} = (1, 1)}}}{\Pr(\bm{W}{3:4} = (1, 1))} - Y_4^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{3:4} = (0, 0)}}}{{\Pr(\bm{W}{3:4} = (0, 0))}} \right] & = \frac{1}{2}\left[Y_4(1, 1, 1) + Y_4(0, 1, 1) - Y_4(0, 0, 0) - Y_4(1, 0, 0) \right] \end{align*} $
Note that this is the $2$-misspecified lag- $1$ causal effect. $\square$
11.5 Unbiasedness of the Horvitz-Thompson Estimator when $m$ is Misspecified
We state here the omitted mathematics in Proposition 34.
Under Assumptions Assumption 2 and Assumption 4, for $p<m$, at each time $t \geq m+1$, the Horvitz-Thompson estimator is either unbiased for the lag- $m$ causal effect when $f(t-p) \leq t-m$, i.e.,
$ \begin{align*} \mathbb{E}{\bm{W}{1:T} \sim \eta_{\mathbb{T}, \mathbb{Q}}}\left[Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{1}{p+1}}}}{\Pr(\bm{W}{t-p:t} = \bm{1}{p+1})} - Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{0}{p+1}}}}{{\Pr(\bm{W}{t-p:t} = \bm{0}{p+1})}} \right] = Y_t(\bm{1}{m+1}) - Y_t(\bm{0}{m+1}), \end{align*} $
or conditionally unbiased for the $m$-misspecified lag- $p$ causal effect when $f(t-p) > t-m$, i.e.,
$ \begin{split} \mathbb{E}{\bm{W}{1:T} \sim \eta_{\mathbb{T}, \mathbb{Q}}}\left[\left{Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{1}{p+1}}}}{\Pr(\bm{W}{t-p:t} = \bm{1}{p+1})} - Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{0}{p+1}}}}{{\Pr(\bm{W}{t-p:t} = \bm{0}{p+1})}} \right} - \right. \ \left. \left{ Y_t(\bm{w}{t-m:f(t-p)-1}^{\mathsf{obs}}, \bm{1}{t-f(t-p)+1}) - Y_t(\bm{w}{t-m:f(t-p)-1}^{\mathsf{obs}}, \bm{0}{t-f(t-p)+1}) \right} \left| \bm{W}{t-m:f(t-p)-1} = \bm{w}^{\mathsf{obs}}{t-m:f(t-p)-1} \vphantom{\frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{1}{p+1}}}}{\Pr(\bm{W}{t-p:t} = \bm{1}{p+1})}} \right. \right] = 0. \end{split} $
When $p+1 \leq t \leq m$, the Horvitz-Thompson estimator is either unbiased for the lag- $t$ causal effect when $f(t-p) = 1$, i.e.,
$ \begin{align*} \mathbb{E}{\bm{W}{1:T} \sim \eta_{\mathbb{T}, \mathbb{Q}}}\left[Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{1}{p+1}}}}{\Pr(\bm{W}{t-p:t} = \bm{1}{p+1})} - Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{0}{p+1}}}}{{\Pr(\bm{W}{t-p:t} = \bm{0}{p+1})}} \right] = Y_t(\bm{1}{t}) - Y_t(\bm{0}{t}), \end{align*} $
or conditionally unbiased for the $m$-misspecified lag- $t$ causal effect when $f(t-p) > 1$, i.e.,
$ \begin{split} \mathbb{E}{\bm{W}{1:T} \sim \eta_{\mathbb{T}, \mathbb{Q}}}\left[\left{Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{1}{p+1}}}}{\Pr(\bm{W}{t-p:t} = \bm{1}{p+1})} - Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{0}{p+1}}}}{{\Pr(\bm{W}{t-p:t} = \bm{0}{p+1})}} \right} - \right. \ \left. \left{ Y_t(\bm{w}{1:f(t-p)-1}^{\mathsf{obs}}, \bm{1}{t-f(t-p)+1}) - Y_t(\bm{w}{1:f(t-p)-1}^{\mathsf{obs}}, \bm{0}{t-f(t-p)+1}) \right} \left| \bm{W}{1:f(t-p)-1} = \bm{w}^{\mathsf{obs}}{1:f(t-p)-1} \vphantom{\frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{1}{p+1}}}}{\Pr(\bm{W}{t-p:t} = \bm{1}{p+1})}} \right. \right] = 0. \end{split} $
To remove the conditional expectation, we can further take an outer loop of expectation averaged over the past assignment paths. So the estimator is estimating a weighted average of lag- $p$ effects. When $t \geq m+1$,
$ \begin{align*} \sum_{\bm{w}{t-m:f(t-p)-1}} \Pr(\bm{W}{t-m:f(t-p)-1} = \bm{w}{t-m:f(t-p)-1}) (Y_t(\bm{w}{t-m:f(t-p)-1}, \bm{1}{t-f(t-p)+1}) - Y_t(\bm{w}{t-m:f(t-p)-1}, \bm{0}_{t-f(t-p)+1})), \end{align*} $
and when $p+1 \leq t \leq m$,
$ \begin{align*} \sum_{\bm{w}{1:f(t-p)-1}} \Pr(\bm{W}{1:f(t-p)-1} = \bm{w}{1:f(t-p)-1}) (Y_t(\bm{w}{1:f(t-p)-1}, \bm{1}{t-f(t-p)+1}) - Y_t(\bm{w}{1:f(t-p)-1}, \bm{0}_{t-f(t-p)+1})). \end{align*} $
We prove Proposition 34 as follows.
Proof of Proposition 34.: Focus on any specific $t \in {m+1:T}$.
When $f(t-p) \leq t-m$, both $0 < \Pr(\bm{W}{t-p:t} = \bm{1}{p+1}), \Pr(\bm{W}{t-p:t} = \bm{0}{p+1}) < 1$. With probability $\Pr(\bm{W}{t-p:t} = \bm{1}{p+1}) \ne 0$, $\mathbf{1}{{\bm{W}{t-p:t} = \bm{1}{p+1}}} = 1$, and $Y_t^{\mathsf{obs}} = Y_t(\bm{1}{m+1})$. So $\mathbb{E}\left[Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{1}{p+1}}}}{\Pr(\bm{W}{t-p:t} = \bm{1}{p+1})} \right] = Y_t(\bm{1}{m+1})$. Similarly $\mathbb{E}\left[Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{0}{p+1}}}}{\Pr(\bm{W}{t-p:t} = \bm{0}{p+1})} \right] = Y_t(\bm{0}_{m+1})$. So
$ \begin{align*} \mathbb{E}{\bm{W}{1:T} \sim \eta_{\mathbb{T}, \mathbb{Q}}}\left[\left{Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{1}{p+1}}}}{\Pr(\bm{W}{t-p:t} = \bm{1}{p+1})} - Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{0}{p+1}}}}{{\Pr(\bm{W}{t-p:t} = \bm{0}{p+1})}} \right} \right] = Y_t(\bm{1}{m+1}) - Y_t(\bm{0}{m+1}). \end{align*} $
When $f(t-p) > t-m$, both $0 < \Pr\left(\bm{W}{t-p:t} = \bm{1}{p+1} \left| \bm{W}{t-m:f(t-p)-1} = \bm{w}^{\mathsf{obs}}{t-m:f(t-p)-1} \right. \right) < 1$ and $0 < \Pr\left(\bm{W}{t-p:t} = \bm{0}{p+1} \left| \bm{W}{t-m:f(t-p)-1} = \bm{w}^{\mathsf{obs}}{t-m:f(t-p)-1} \right.\right) < 1$. Conditional on $\bm{W}{t-m:f(t-p)-1} = \bm{w}^{\mathsf{obs}}{t-m:f(t-p)-1}$, we know that with probability $\Pr\left(\bm{W}{t-p:t} = \bm{1}{p+1} \left| \bm{W}{t-m:f(t-p)-1} = \bm{w}^{\mathsf{obs}}{t-m:f(t-p)-1} \right. \right) \ne 0$, $\mathbf{1}{{\bm{W}{t-p:t} = \bm{1}{p+1}}} = 1$, and $Y_t^{\mathsf{obs}} = Y_t(\bm{w}^{\mathsf{obs}}{t-m:f(t-p)-1}, \bm{1}{t-f(t-p)+1})$. So
$ \mathbb{E}{\bm{W}{1:T} \sim \eta_{\mathbb{T}, \mathbb{Q}}} \left[Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{1}{p+1}}}}{\Pr(\bm{W}{t-p:t} = \bm{1}{p+1})} - Y_t(\bm{w}{t-m:f(t-p)-1}^{\mathsf{obs}}, \bm{1}{t-f(t-p)+1}) \left| \bm{W}{t-m:f(t-p)-1} = \bm{w}^{\mathsf{obs}}{t-m:f(t-p)-1} \right. \right] = 0. $
Similarly, we have
$ \mathbb{E}{\bm{W}{1:T} \sim \eta_{\mathbb{T}, \mathbb{Q}}} \left[Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{W}{t-p:t} = \bm{0}{p+1}}}}{\Pr(\bm{W}{t-p:t} = \bm{0}{p+1})} - Y_t(\bm{w}{t-m:f(t-p)-1}^{\mathsf{obs}}, \bm{0}{t-f(t-p)+1}) \left| \bm{W}{t-m:f(t-p)-1} = \bm{w}^{\mathsf{obs}}{t-m:f(t-p)-1} \right. \right] = 0, $
which finishes the proof. $\square$
11.6 Asymptotic Normality when $m$ is Misspecified
The proof of Corollary 21 consists of two parts: $p>m$ and $p<m$. When $p>m$ we consult Lemma 17 and Theorem 20. When $p<m$ we prove Corollary 21 by using Lemma 23. In particular, we derive $B_{n, k, a}^2$, and then construct some proper $\Delta_n, K_n$, and $L_n$.
Proof of Corollary 21.: The proof consists of two parts: $p>m$ and $p<m$. First, when $p>m$, we know that $\widehat{\tau}_p = \widehat{\tau}_m, \tau_p = \tau_m, \mathsf{Var}(\widehat{\tau}_p) = \mathsf{Var}(\widehat{\tau}_m)$. Due to Lemma 17 we prove part (i) the expression in Equation 10. Due to Theorem 20 we know that
$ \begin{align*} \frac{\widehat{\tau}_p - \tau_p}{\sqrt{\mathsf{Var}(\widehat{\tau}_p)}} = \frac{\widehat{\tau}_m - \tau_m}{\sqrt{\mathsf{Var}(\widehat{\tau}_m)}} \xrightarrow[]{D} \mathcal{N}(0, 1). \end{align*} $
Second, when $p<m$, then we follow the same trick as in Theorem 20. In the $n$-replica experiment, $\widehat{\tau}p - \mathbb{E}[\tau^{[m]}p] = \frac{1}{(n-1)p} \sum{k=0}^{n-2} \bar{\mathbf{1}}k$, and $\mathsf{Var}(\widehat{\tau}p) = \frac{1}{(n-1)^2p^2} \mathsf{Var}\left(\sum{k=0}^{n-2} \bar{\mathbf{1}}k \right)$. To use the language from Lemma 23, denote $d=n-1$. Denote for any $i \in [n-1]$, $X{n, i} = \frac{1}{(n-1)p} \bar{\mathbf{1}}{i-1}$. We know that $\phi = \lceil \frac{m}{p} \rceil$, so that ${X{n, 1}, X_{n, 2}, ...}$ is a sequence of $\phi$-dependent random variables. See Table 13 for an illustration of $\phi$.
::: {caption="Table 13: An illustration of $\phi$ when $m=5, p=3$."}

:::
First note that $B_{n}^2 = \mathsf{Var}(\widehat{\tau}p)$, and we calculate $B{n, k, a}^2$ as follows. Note that $k \geq \phi+1$.
$ \begin{align*} B^2_{n, k, a} & = \frac{1}{(n-1)^2 p^2} \mathsf{Var}\left(\sum_{i=a}^{a+k-1} \bar{\mathbf{1}}{i-1} \right) \ & \leq \frac{1}{(n-1)^2 p^2} \left(\sum{i=a}^{a+k-1} \mathbb{E}[\bar{\mathbf{1}}{i-1}^2] + \sum{i=a}^{a+k-2} 2 \mathbb{E}[\bar{\mathbf{1}}{i-1}\bar{\mathbf{1}}{i}] + ... + \sum_{i=a}^{a+k-1+\phi} 2 \mathbb{E}[\bar{\mathbf{1}}{i-1}\bar{\mathbf{1}}{i-1+\phi}] \right)\ & \leq \frac{C p^2 B^2}{(n-1)^2 p^2} \cdot \left(k+(k-1)+...+(k-\phi) \right)\ & \leq \frac{(\phi+1) C k B^2}{(n-1)^2} \end{align*} $
where $C$ is some constant bounding the number of terms in each cross-product expectation $2 \mathbb{E}[\bar{\mathbf{1}}{i-1}\bar{\mathbf{1}}{i}], ..., 2 \mathbb{E}[\bar{\mathbf{1}}{i-1}\bar{\mathbf{1}}{i-1+\phi}]$; and $\phi+1$ is a constant as well.
Pick $\gamma = 0, \delta = 1$, then $\Delta_n = B^3 / (n-1)^3$, $K_n = (\phi+1) C B^2 / (n-1)^2$, and $L_n = \mathsf{Var}(\widehat{\tau}_m) / (n-1)$.
We check that all the five conditions from Lemma 23 are satisfied.
- $\mathbb{E}\left| X_{n, i} \right|^3 \leq \Delta_n = B^3 / (n-1)^3$, because all the potential outcomes are bounded by $B$, so that $X_{n, i} \leq B/(n-1)$.
- $B^2_{n, k, a}/ k \leq K_n = (\phi+1) C B^2 / (n-1)^2$.
- $B_n^2/(n-1) \geq L_n = \mathsf{Var}(\widehat{\tau}_m) / (n-1)$.
- $K_n / L_n = (\phi+1) C B^2 / (n-1) \mathsf{Var}(\widehat{\tau}_m) = O(1)$, where the last equality is due to Assumption 19.
- $\Delta_n / L_n^{3/2} = B^3 / (n-1)^{3/2} \mathsf{Var}(\widehat{\tau}_m)^{3/2} = O(1)$, where the last equality is due to Assumption 19.
Due to Lemma 23,
$ \begin{align*} \frac{\widehat{\tau}_p - \tau_p}{\sqrt{\mathsf{Var}(\widehat{\tau}_p)}} \xrightarrow[]{D} \mathcal{N}(0, 1). \end{align*} $
$\square$ ## Additional Simulation Results
11.7 Flexibility of the Outcome Models
As we will see below, it is easy to use the potential outcome framework to describe many complex relationships between assignments and outcomes.
We start with a simple model which originates from [72]:
$ \begin{align} Y_t(\bm{w}{1:t}) = \mu + \alpha_t + \delta w_t + \gamma w{t-1} + \epsilon_t \end{align}\tag{25} $
where $\mu$ is a fixed effect; $\alpha_t$ is a fixed effect associated to period $t$; $\delta w_t$ is the contemporaneous effect, and $\gamma w_{t-1}$ is the carryover effect from period $t-1$; $\epsilon_t$ is the random noise in period $t$. Such a model as well as a few very similar ones are widely used in the literature ([73, 74]).
A more general variant from the above model is to consider carryover effects of any arbitrary order, which we have defined in Equation 13 in the main body of the paper.
$ \begin{align*} Y_t(\bm{w}{1:t}) = \mu + \alpha_t + \delta^{(1)} w_t + \delta^{(2)} w{t-1} + ... + \delta^{(t)} w_1 + \epsilon_t \end{align*} $
where $\delta^{(1)}, \delta^{(2)}, ..., \delta^{(t)}$ are non-stochastic coefficients. The dotted terms are carryover effects of higher orders. And all the other parameters are as defined in Equation 25. We will run simulations based on this more general model, which enables us to test the performance of our proposed optimal design under a misspecified $m$.
The autoregressive model ([77]) is even more general: $Y_1(w_{1}) = \delta_{1, 1} w_1 + \epsilon_1$ and $\forall t > 1$
$ \begin{split} Y_t(\bm{w}{1:t}) = \phi{t, t-1} Y_{t-1}(\bm{w}{1:t-1}) + \phi{t, t-2} Y_{t-2}(\bm{w}{1:t-2}) + ... + \phi{t, 1} Y_{1}(w_{1}) + \ \delta_{t, t} w_t + \delta_{t, t-1} w_{t-1} + ... + \delta_{t, 1} w_1 + \epsilon_t \end{split}\tag{26} $
where $\phi_{t, \tilde{t}}$ and $\delta_{t, \tilde{t}}$ are non-stochastic coefficients; the dotted terms are carryover effects of higher orders; $\epsilon_t$ is the random noise in period $t$. We can iteratively replace $Y_t(w_{t})$ using a linear combination of $w_t, w_{t-1}, ..., w_1$. So the autoregressive model in Equation 26 can be written in a similar form of Equation 13. The only difference is that the coefficients are different and dependent on $t$.
11.8 Comparison of Different Designs when Estimating Instantaneous Effects and Other Lag Effects
11.8.1 Simulation setup.
We consider a similar setup as in Section 5.1. We run simulations based on the outcome model as in Equation 13. We consider $T=120, p=m=2$ where $m$ is correctly identified. For the outcome model, we consider $\mu = 0$, $\alpha_t = \log{(t)}$, and $\epsilon_t \sim N(0, 1)$ are i.i.d. standard normal distributions. For any $t >3$, let $\delta^{(t)} = 0$. We will vary the values of $\delta^{(1)}, \delta^{(2)}, \delta^{(3)} \in {1, 2}$ and conduct experiments under $2^3=8$ different scenarios.
Different from Section 5.1, instead of estimating the average lag-p causal effect as defined in Equation 1, we estimate the following family of causal effects. For any non-negative integers $p, q$, define
$ \begin{align} \tau_{p, q}(\mathbb{Y}) = \frac{1}{T-p} \sum_{t=p+1}^{T} [Y_t(\bm{0}{p-q}, \bm{1}{q+1}) - Y_t(\bm{0}_{p+1})]. \end{align}\tag{27} $
Such a family of causal effects are already studied in the literature ([78]). When $q=0$, $\tau_{p, 0}(\mathbb{Y})$ is also known as the instantaneous treatment effect. When $q=p$, $\tau_{p, p}(\mathbb{Y})$ is the average lag-p causal effect as defined in Equation 1. Since our belief is that the carryover effect is of order $p$, there is no reason we would like to estimate $\tau_{p, q}$ when $q>p$.
Similar to Section 5.1, we compare the same three different designs of switchback experiments. $\mathbb{T}^*={1, 5, 7, ..., 117}, \mathbb{T}^\mathsf{H1}={1, 2, 3, ..., 120}$, and $\mathbb{T}^\mathsf{H2}={1, 4, 7, ..., 118}$. Although the primary purpose of running any of these three experiments is to estimate the average lag-p causal effect as defined in Equation 1, after running the experiment we can use the observed data to estimate the causal effects as defined in Equation 27.
In order to estimate such a family of causal effects, we again use the Horvitz-Thompson estimator. However, when we use the optimal design as suggested by Theorem 14, on some periods we would have zero probability to observe $Y_t(\bm{1}{p-q}, \bm{1}{q+1})$. This is because due to Theorem 14, we only randomize every $p$ periods. Therefore, we define
$ \begin{align*} \mathcal{T}{p, q}(\eta{\mathbb{T}, \mathbb{Q}}) = \left{ t \left| \Pr(\bm{W}{t-p:t} = (\bm{0}{p-q}, \bm{1}_{q+1})) \ne 0 \right.\right} \end{align*} $
and then use the set $\mathcal{T}{p, q}(\eta{\mathbb{T}, \mathbb{Q}})$ to define the Horvitz-Thompson estimator,
$ \begin{split} \widehat{\tau}{p, q} (\eta{\mathbb{T}, \mathbb{Q}}, \bm{w}{1:T}, \mathbb{Y}) = \ \frac{1}{T-p} \sum{\substack{{p+1\leq t \leq T} \ t \in \mathcal{T}{p, q}(\eta{\mathbb{T}, \mathbb{Q}})}} \left{ Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{w}{t-p:t} = (\bm{0}{p-q}, \bm{1}{q+1})}}}{\Pr(\bm{W}{t-p:t} = (\bm{0}{p-q}, \bm{1}{q+1}))} - Y_t^{\mathsf{obs}} \frac{\mathbf{1}{{\bm{w}{t-p:t} = \bm{0}{p+1}}}}{{\Pr(\bm{W}{t-p:t} = \bm{0}{p+1})}} \right}. \end{split}\tag{28} $
We simulate one assignment path at a time, and conduct an experiment following this assignment path. Since the outcome model is prescribed, we can calculate both the causal estimand and and the observed outcomes (along the simulated assignment path). Then, we calculate the Horvitz-Thompson estimator based on the simulated assignment path and the simulated observed outcomes. With both the estimand and estimator, we can calculate the loss function. We repeat the above procedure enough ($100000$) times to obtain an accurate approximation of the risk function.
::: {caption="Table 14: Simulation results for the risk function when estimating instantaneous effects and other lag effects."}
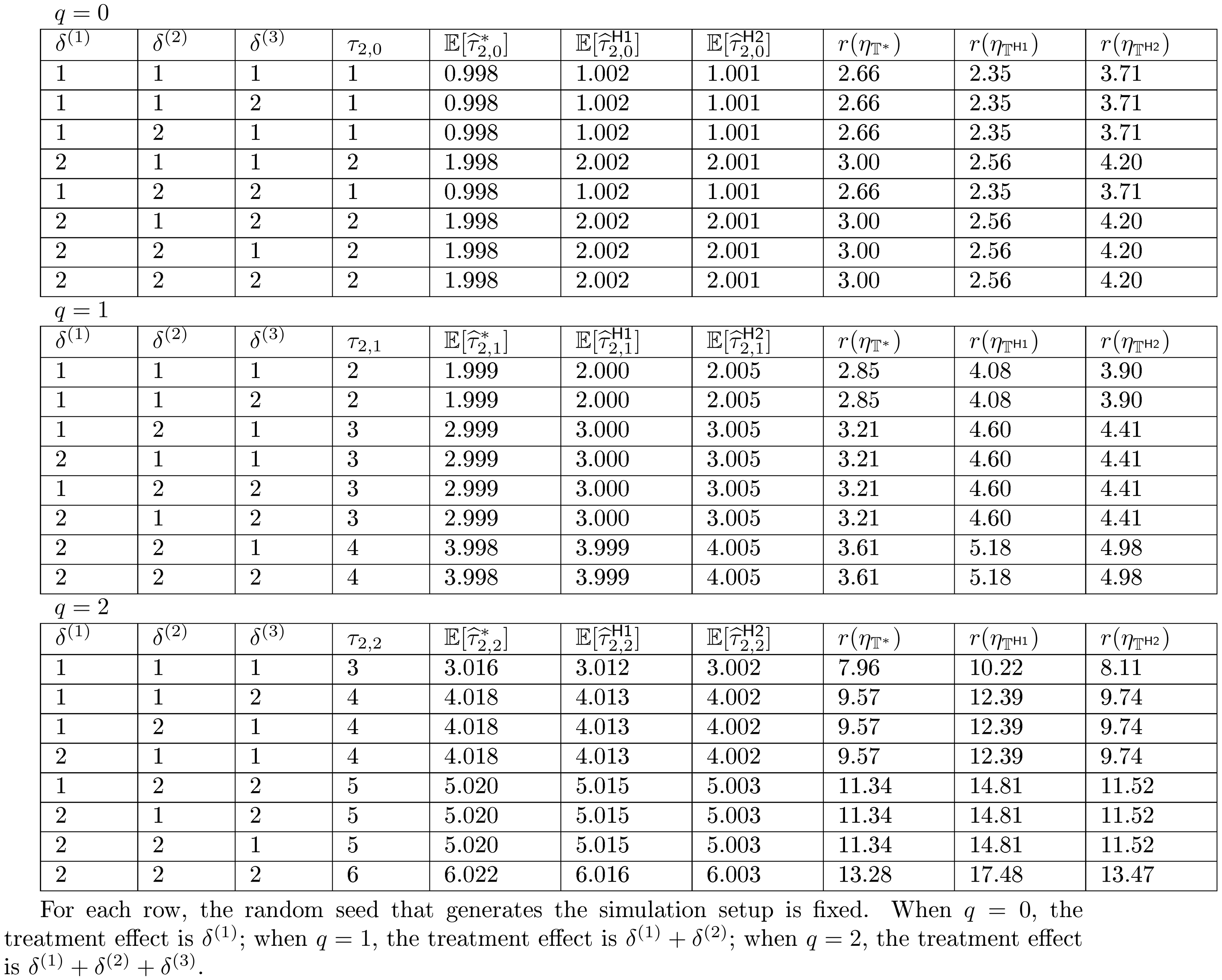
:::
11.8.2 Simulation results.
We calculate the risk functions based on the outcome model in Equation 13. See Table 14. For each $q$, as we vary the values of $\delta^{(1)}$, $\delta^{(2)}$ and $\delta^{(3)}$, the causal estimand is being changed. For each $q$, all three estimators are able to reflect the change as the estimand changes. This is because the Horvitz-Thompson estimator is unbiased.
Moving on to the risk function, we discuss $q=0, 1, 2$ separately. When $q=0$, we see that the risk function associated with the first benchmark $\mathbb{T}^\mathsf{H1}$ is smaller than the optimal design; and the second benchmark $\mathbb{T}^\mathsf{H2}$ is much larger than the optimal design. This is because the Horvitz-Thompson estimator as we defined in Equation 28 does not use all the data, if there are periods that have zero probability to observe $Y_t(\bm{1}{p-q}, \bm{1}{q+1})$, such as when we are using $\mathbb{T}^*$ or $\mathbb{T}^\mathsf{H2}$. When $q=1$, despite the fact that the Horvitz-Thompson estimator does not use all the data when we are using $\mathbb{T}^*$ or $\mathbb{T}^\mathsf{H2}$, we can see that the risk function associated with the first benchmark $\mathbb{T}^\mathsf{H1}$ is larger than the optimal design; and the second benchmark $\mathbb{T}^\mathsf{H2}$ is also larger. Our proposed optimal design have the smallest risk. When $q=2$, the table exactly recovers Table 3. Again our proposed optimal design have the smallest risk
The simulation results across $q=0, 1, 2$ suggest that, whenever the primary interest is in estimating the instantaneous effects, we recommend to use a design of experiment that randomizes more frequently. Whenever the primary interest is in estimating the lag effects, we recommend to use our optimal design as proposed in Theorem 14. If the primary interest is undetermined or subject to future changes, our optimal design, combined with the proper Horvitz-Thompson estimator, still provides unbiased estimation whenever the causal estimand is specified.
11.9 Additional Simulation Results for Section 5.2 Asymptotic Normality
In Section 5.2 we have only shown simulation results for the variance distribution, when $m$ is correctly specified and under $\delta=3$, see asymptotic normality. In this section we provide additional simulation results under $\delta=1$ and $\delta=2$.
See Figure 9–Figure 11 for simulation results under $\delta=1$; See Figure 12–Figure 14 for simulation results under $\delta=2$. See Figure 15–Figure 16 for simulation results under $\delta=3$.
By comparing all the results, we see that in all cases, the pink histograms approximately follow the standard normal distribution; whereas the light blue histograms, since the distributions are induced by normalizing the expectation of the conservative upper bound, are more concentrated around zero. Furthermore, as $\delta$ increases, the light blue histograms become even more concentrated around zero, i.e., the distances between the light blue histograms and the pink histograms grow larger.
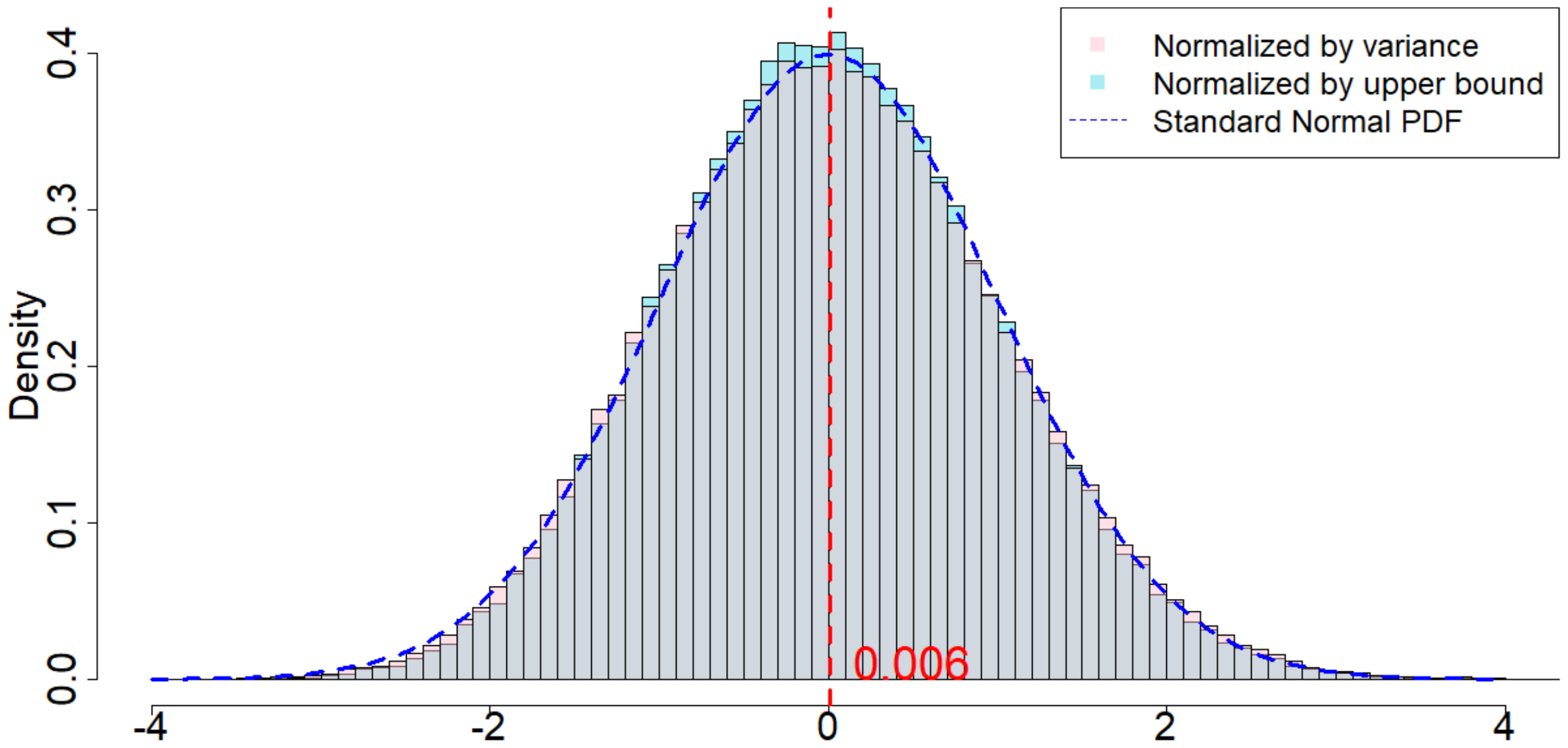
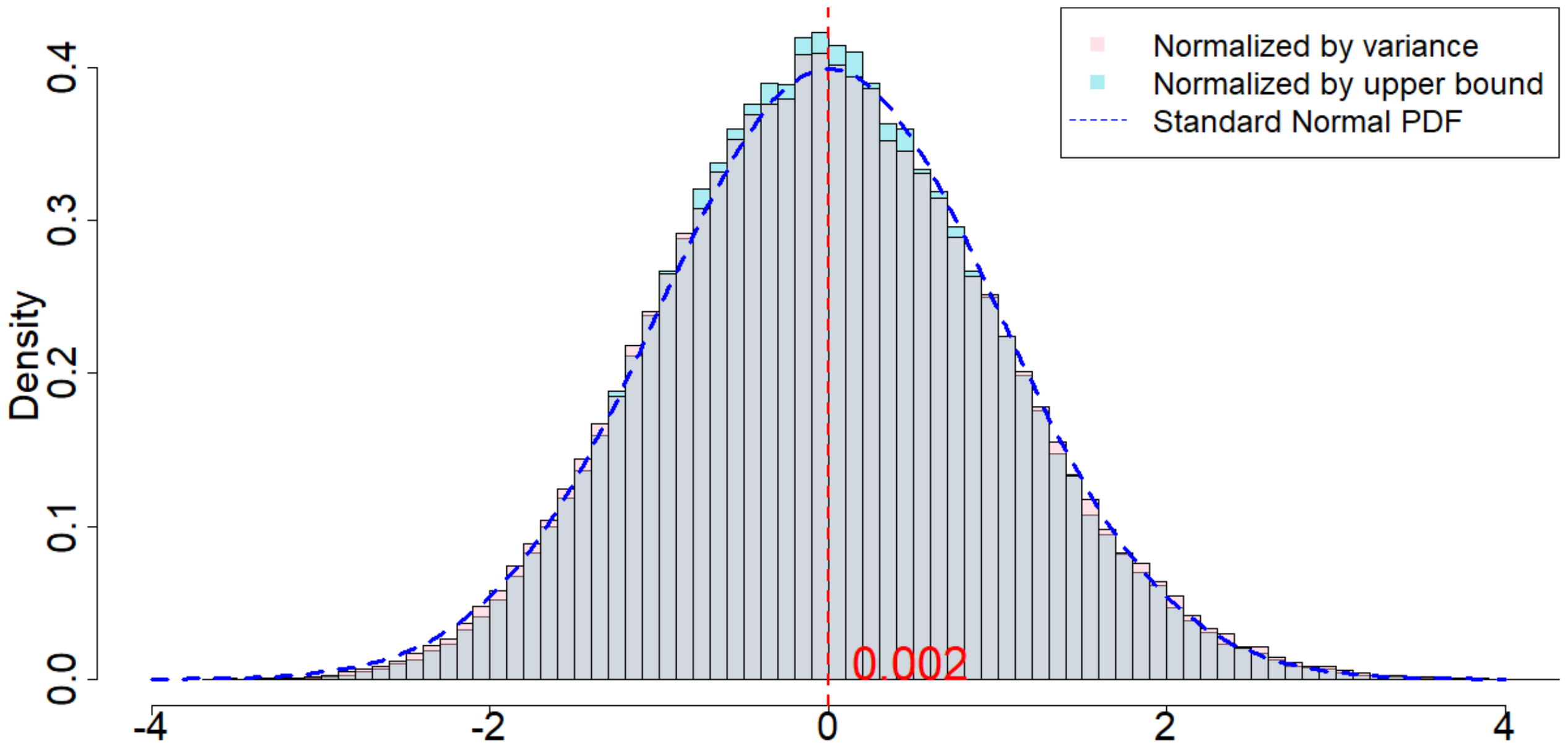
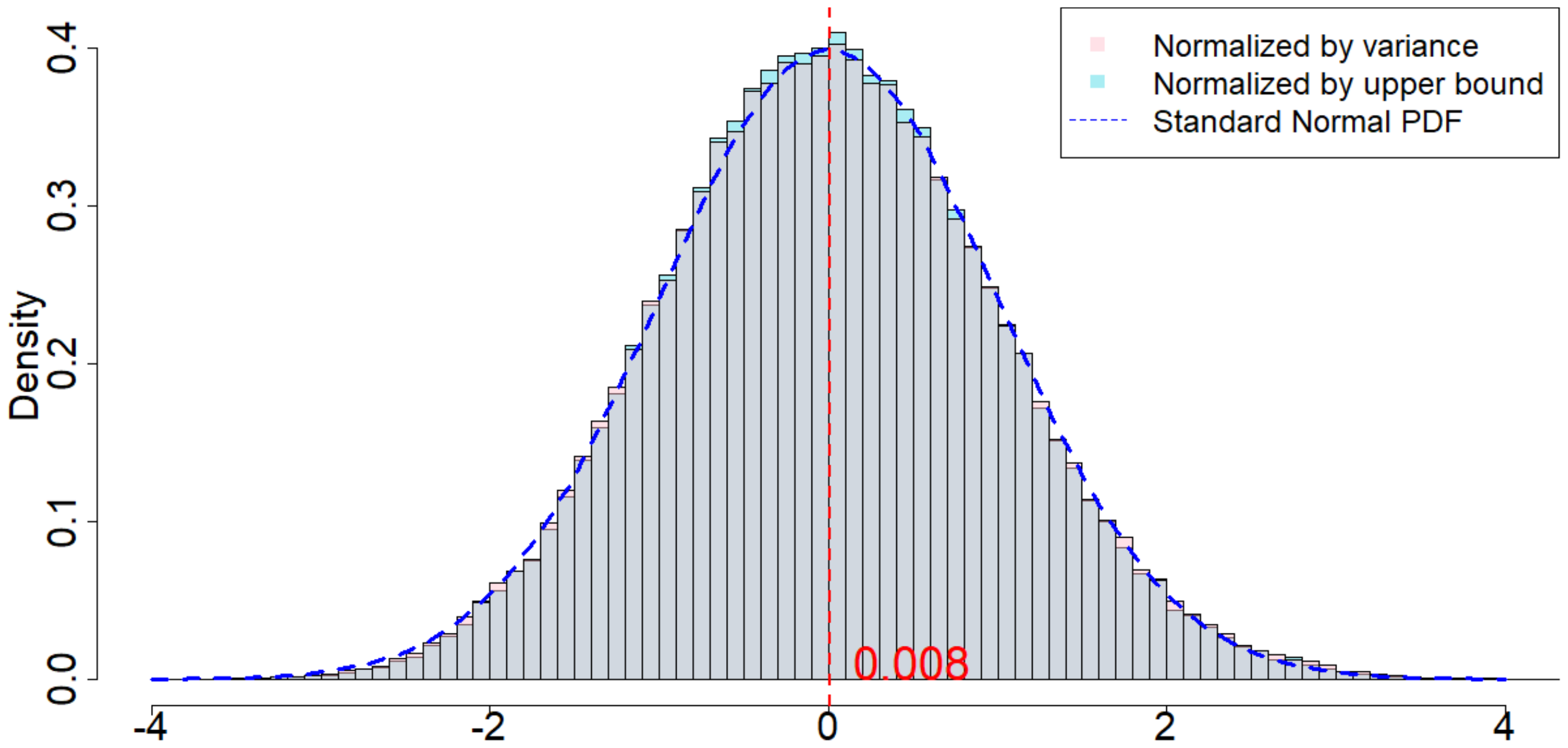
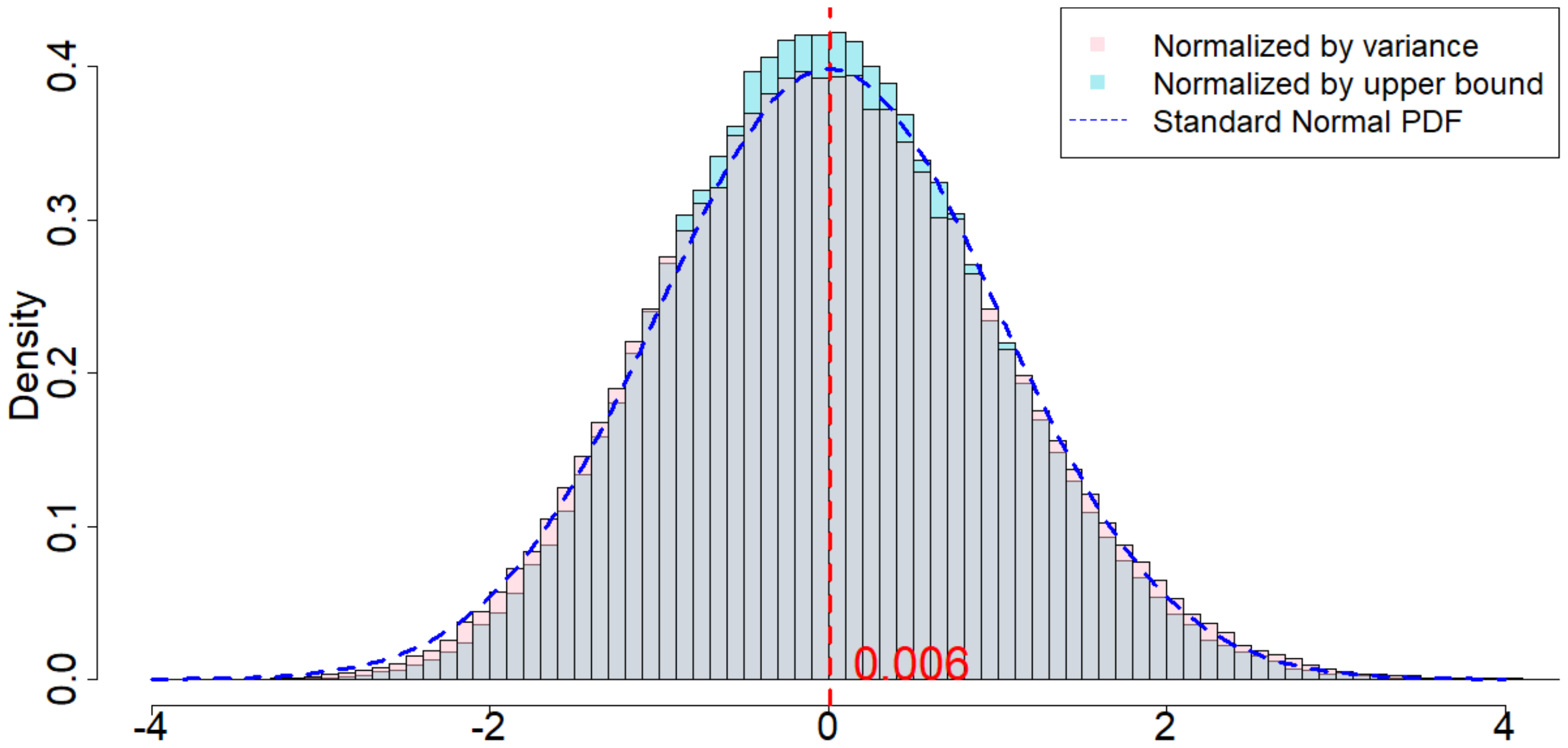
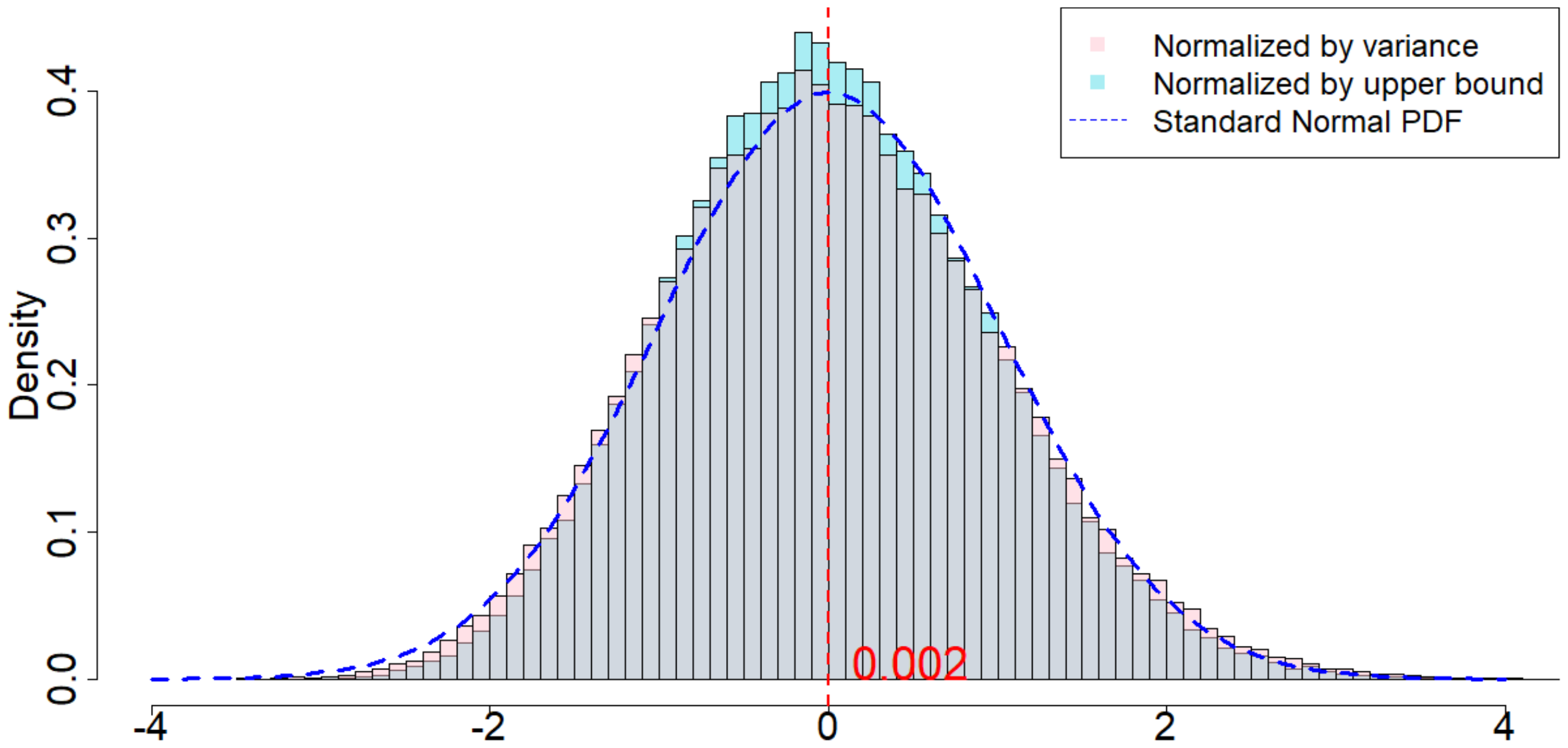
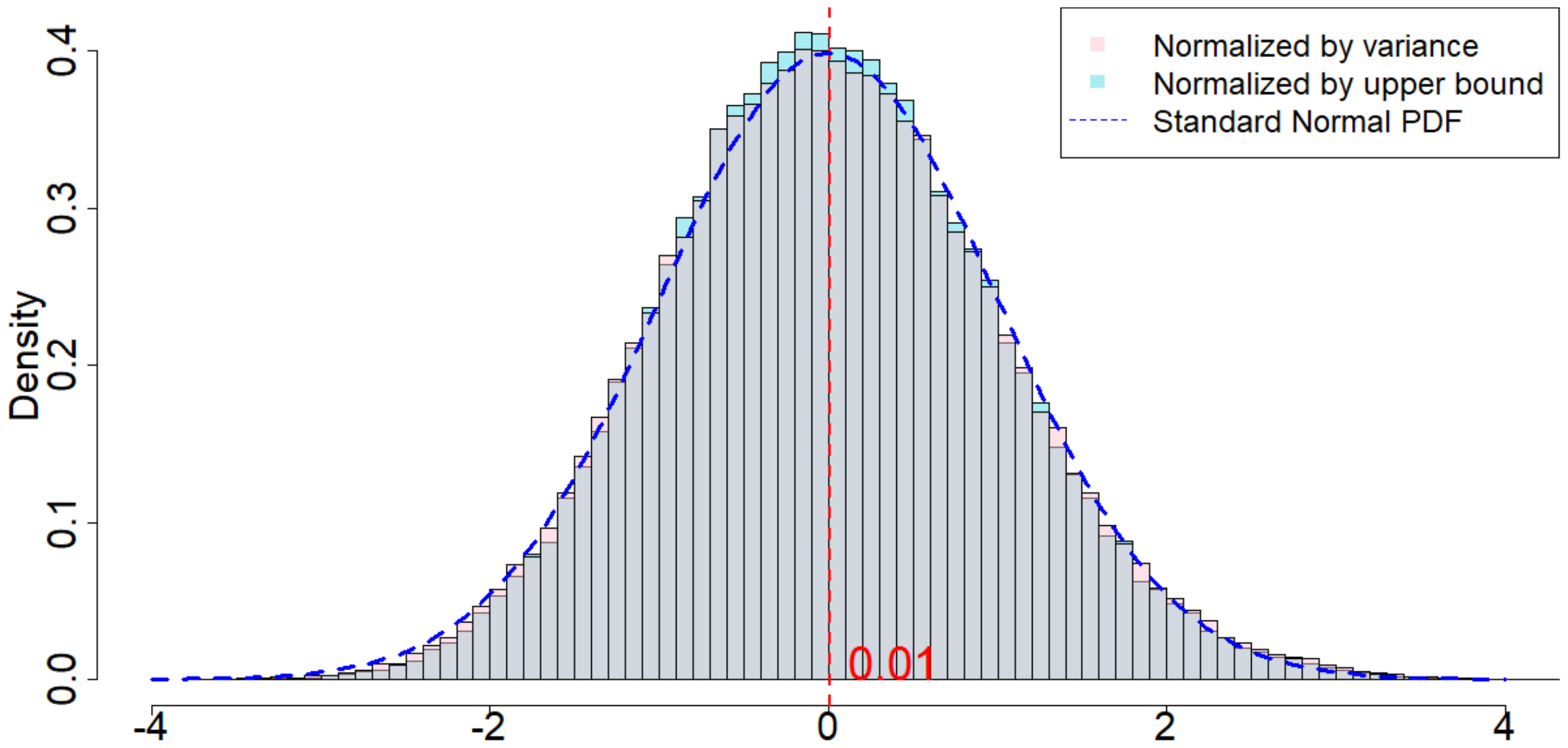
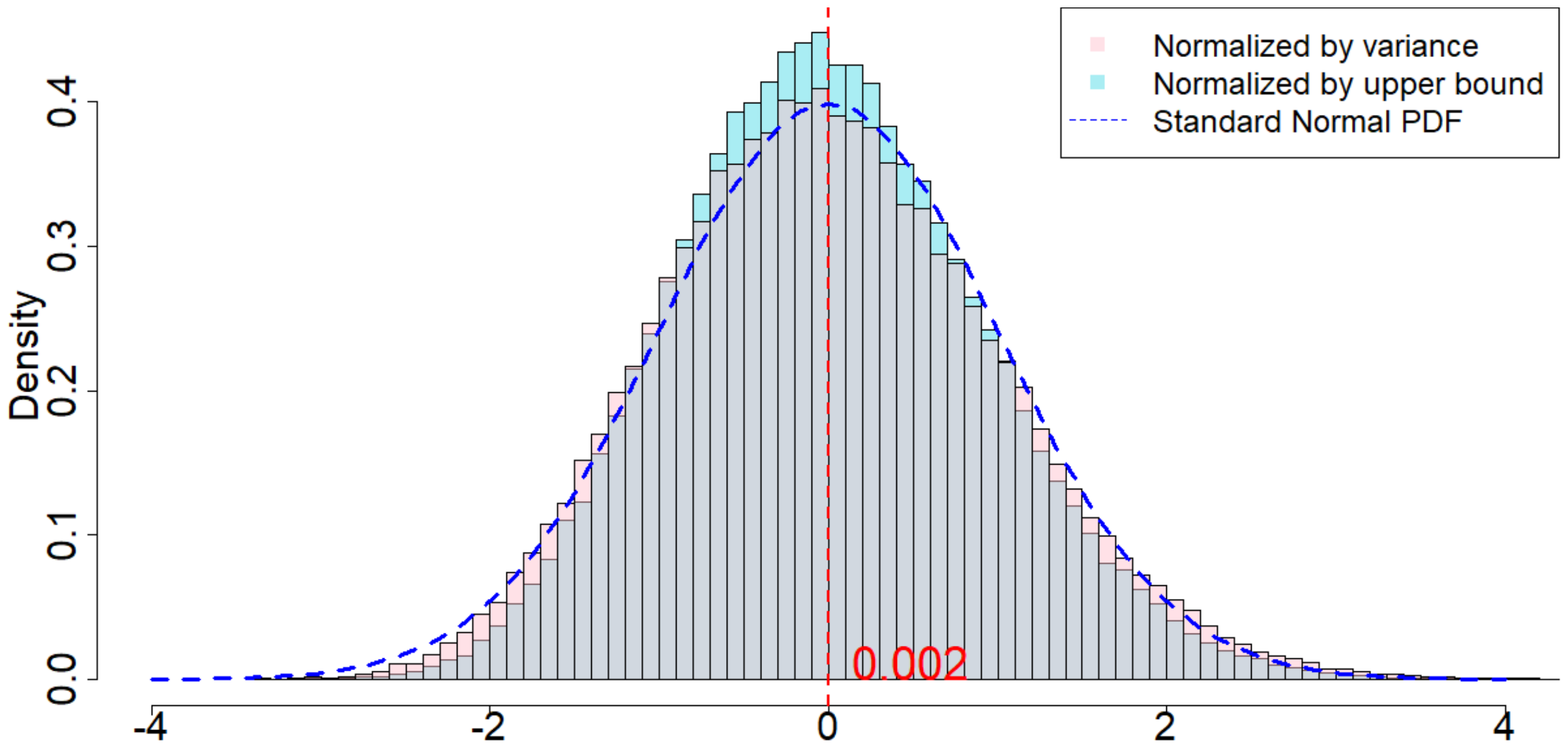
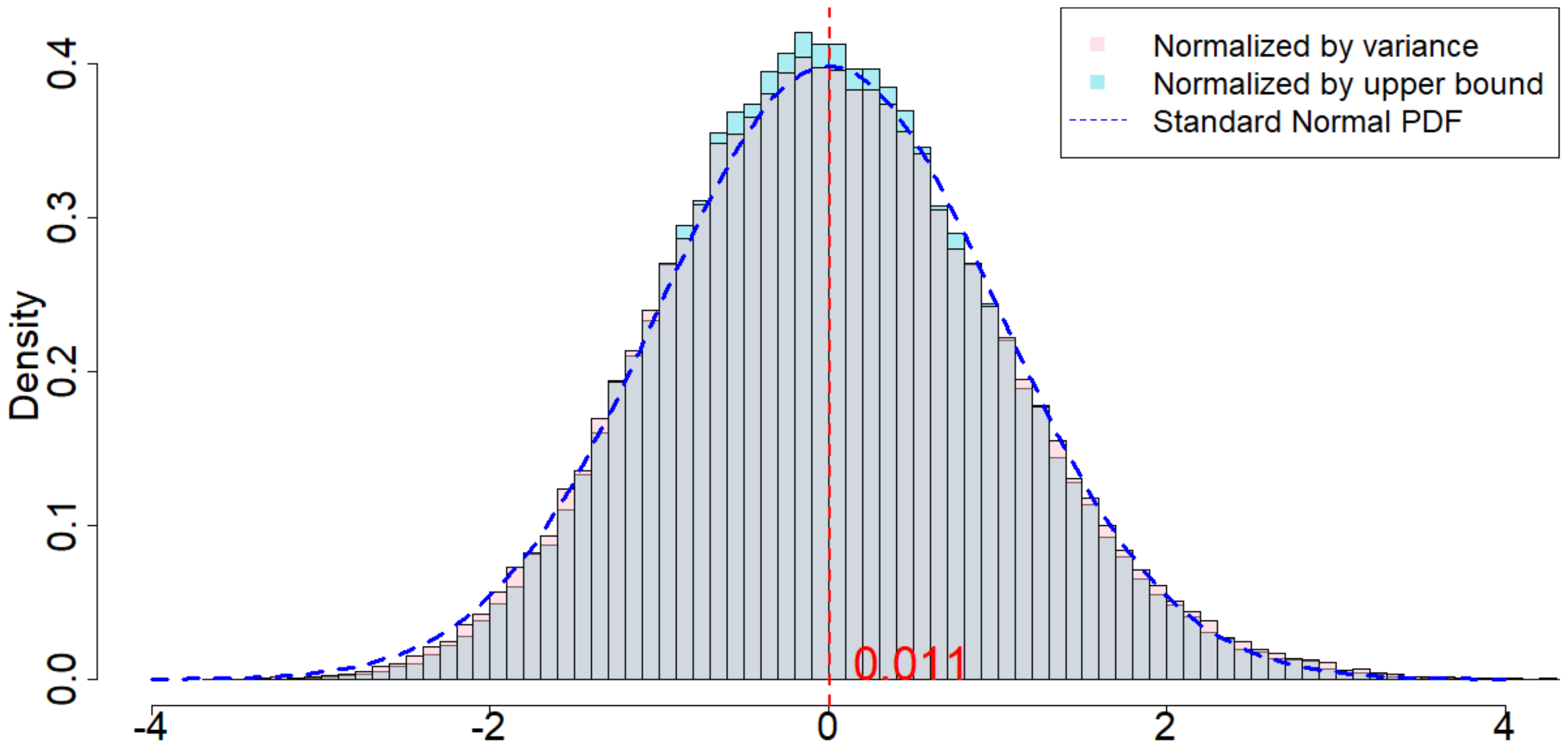
11.9.1 Robustness Check.
In Section 5.2.3 we have shown results when $m=2, p=2, \delta=1$. In this section we provide additional simulation results under other parameters. When $T=120$, the empirical distributions as shown in the histograms are significantly different from normal distributions. See Figure 5, Figure 17, Figure 19, Figure 21, Figure 23, Figure 25, Figure 27, Figure 29, Figure 31. When $T=1200$, the empirical distributions as shown in the histograms are much closer to normal distributions. See Figure 6, Figure 18, Figure 20, Figure 22, Figure 24, Figure 26, Figure 28, Figure 30, Figure 32. All the simulation results deliver the same message, that when $\epsilon_t$ noises are heavy tailed, the convergence to a standard normal distribution as we have shown in Theorem 20 requires longer horizon.
Interestingly, if we make the comparison between the pink histogram and the light blue histogram, we can see how much gap it incurs when we replace the true variance with the conservative upper bound. If we compare Figure 9 and Figure 6, then we find that the conservative upper bound is a better approximation of the true variance when the noises $\epsilon_t$ conform normal distributions, rather than heavy-tailed distributions.
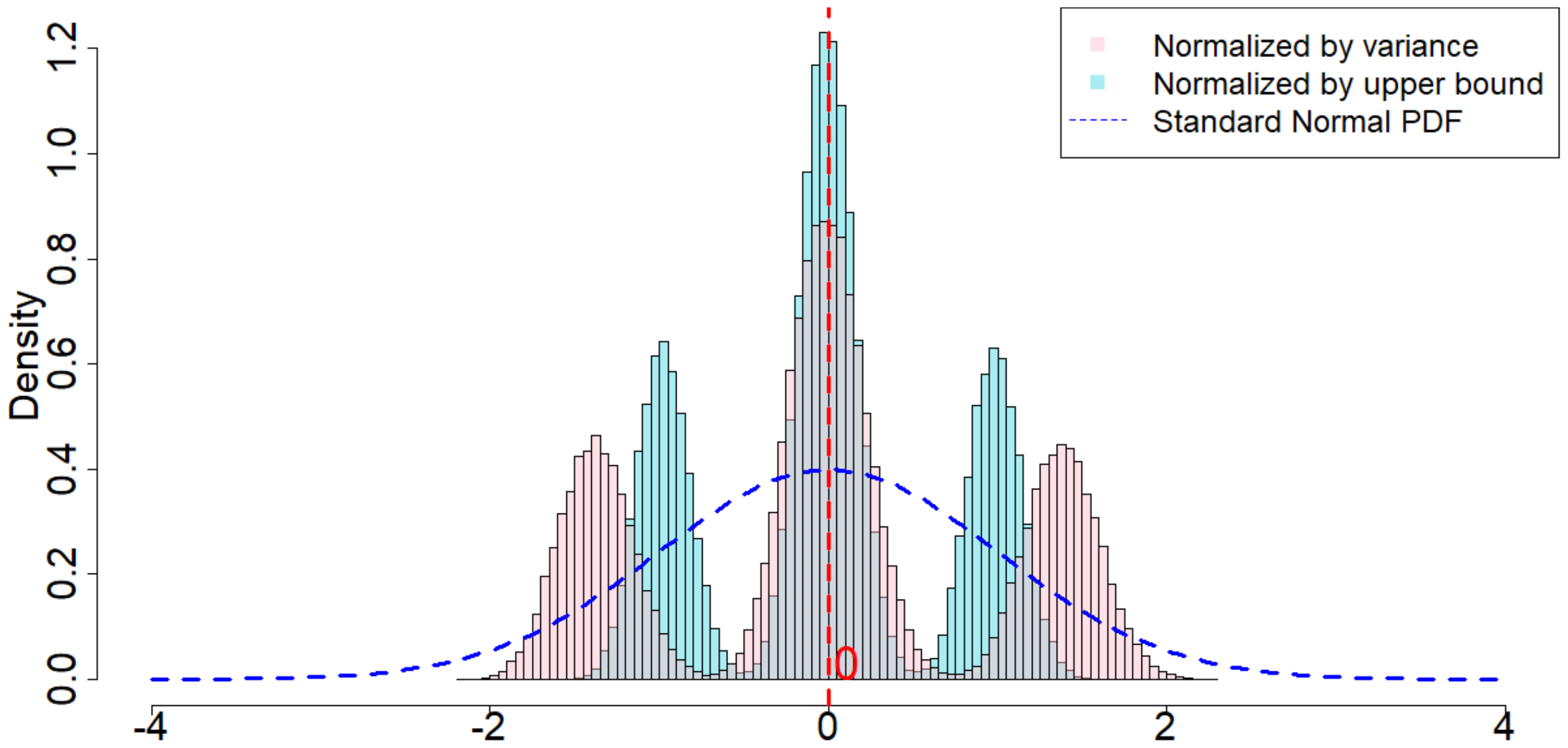
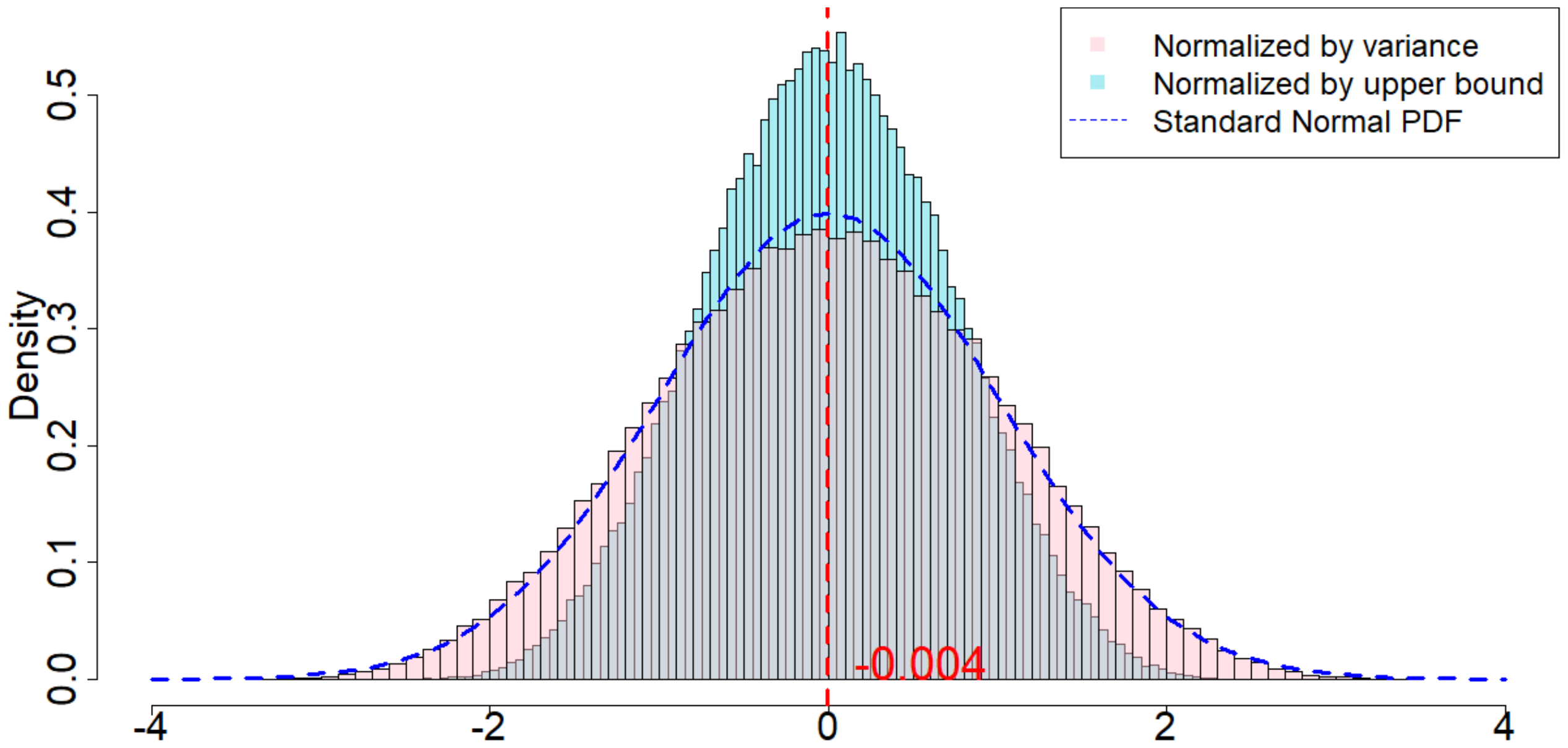
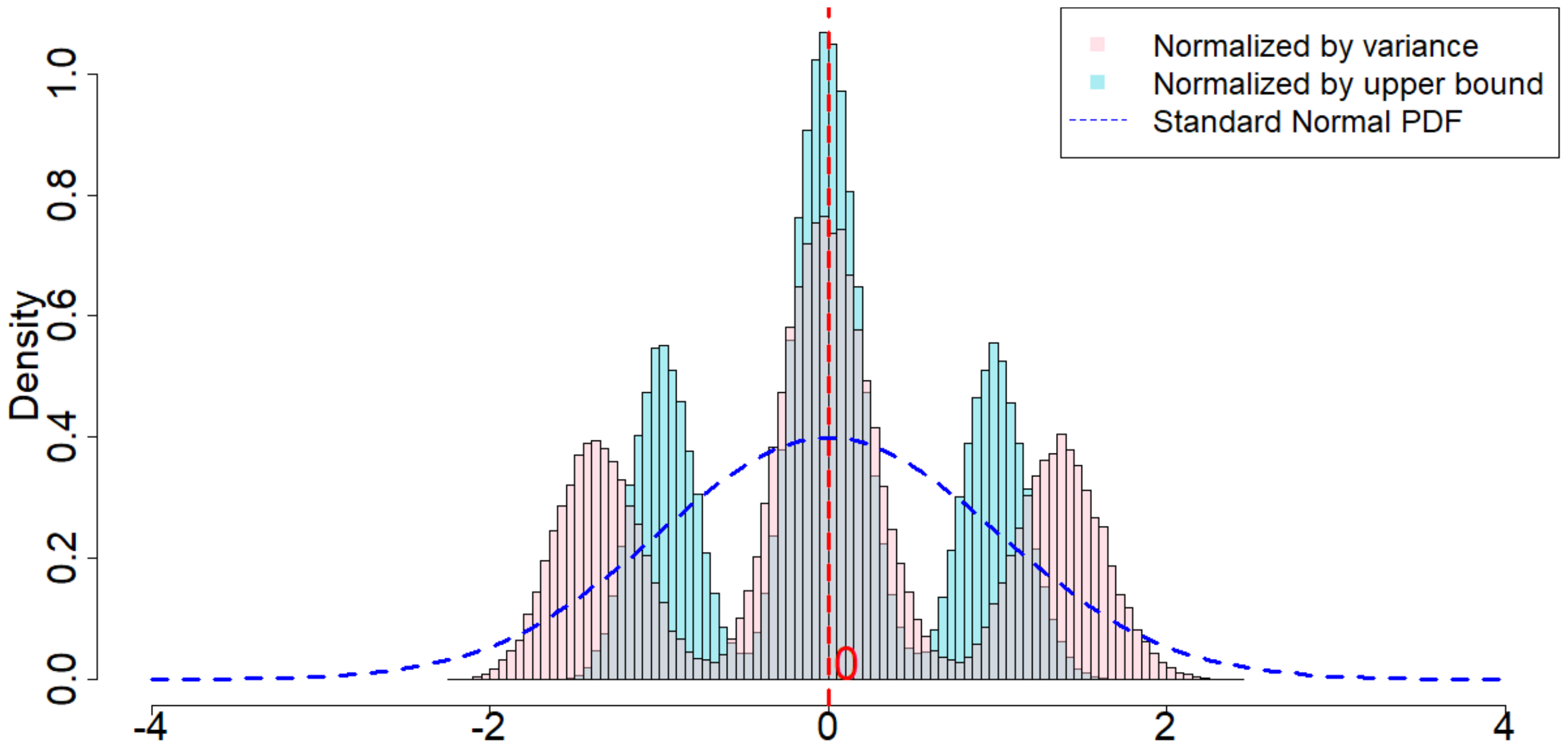
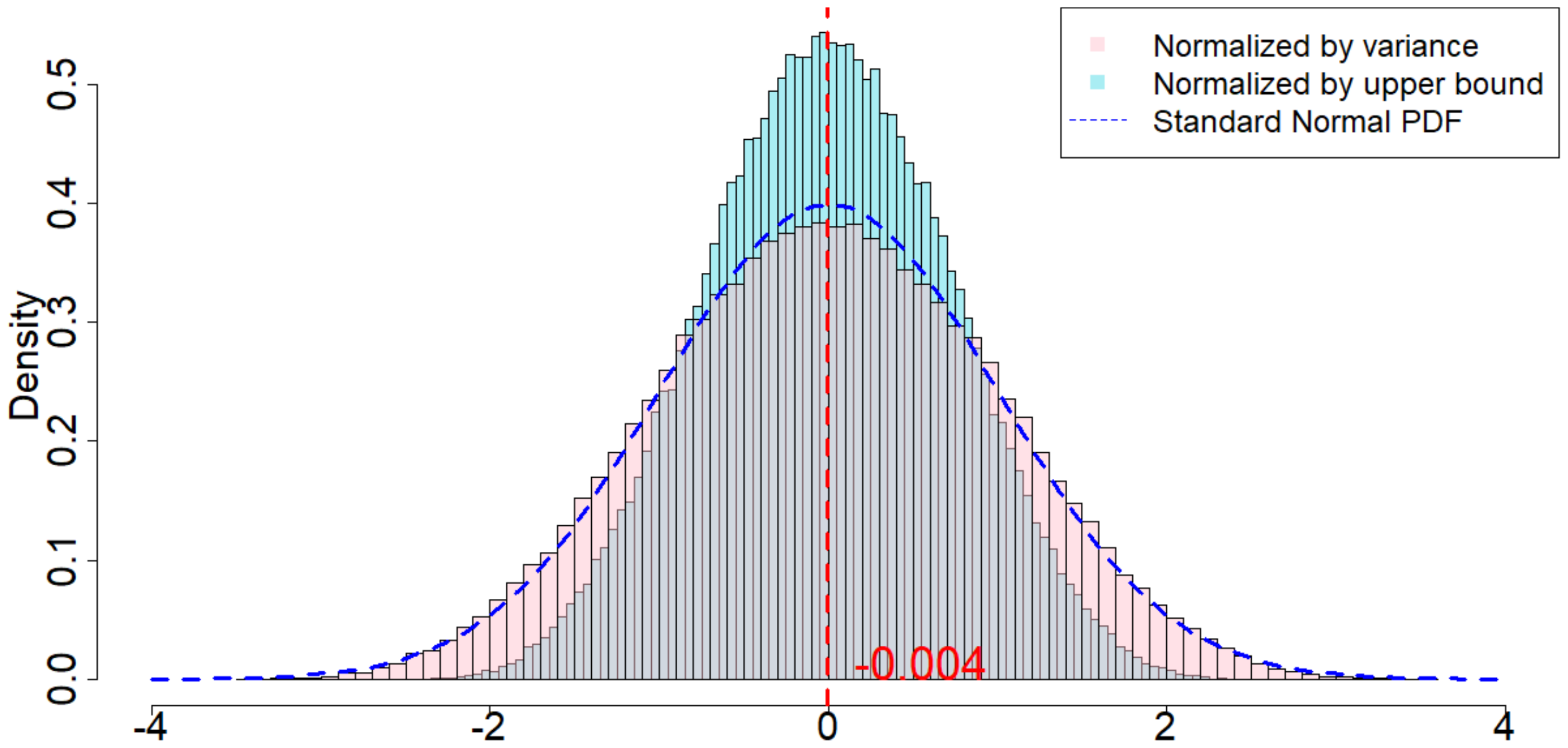
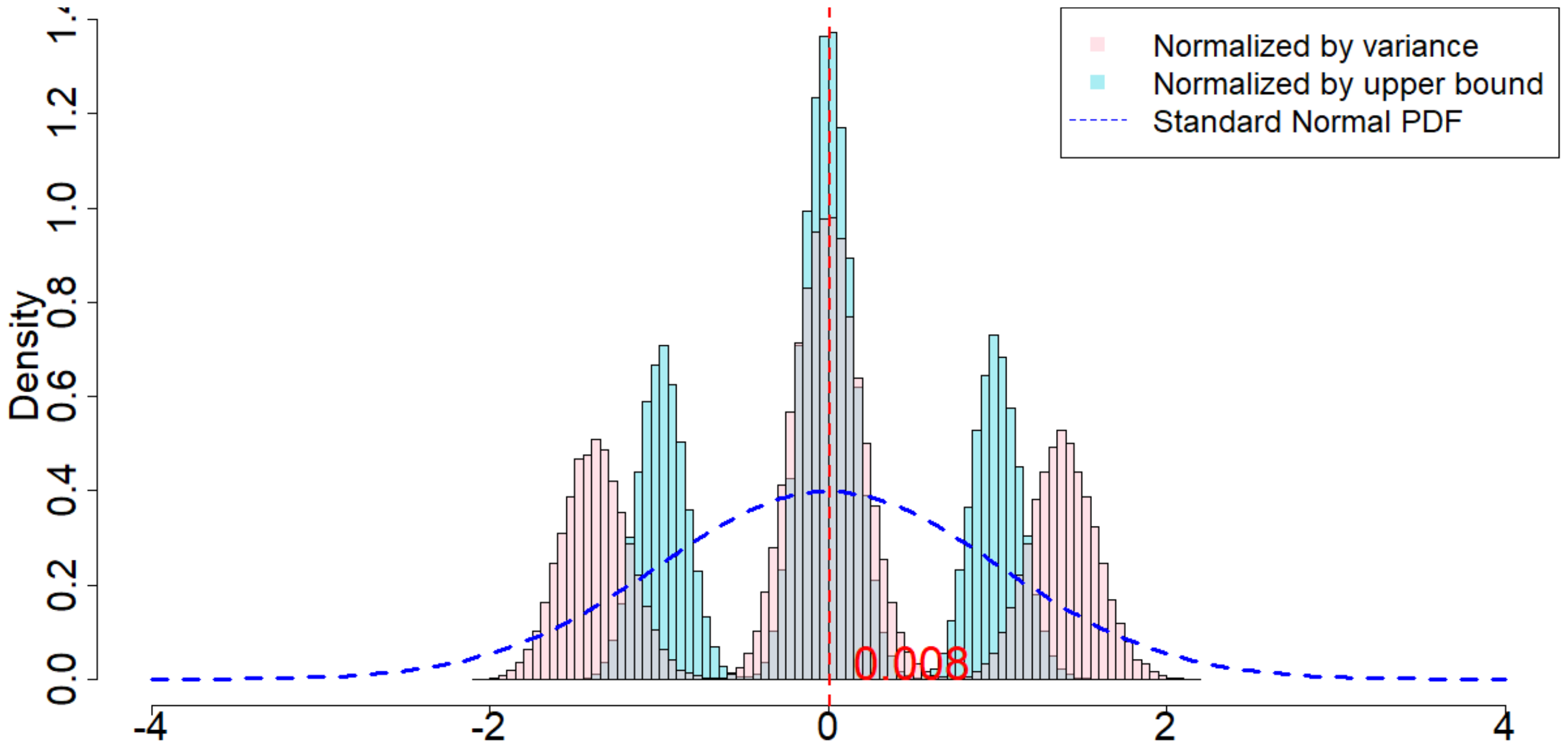
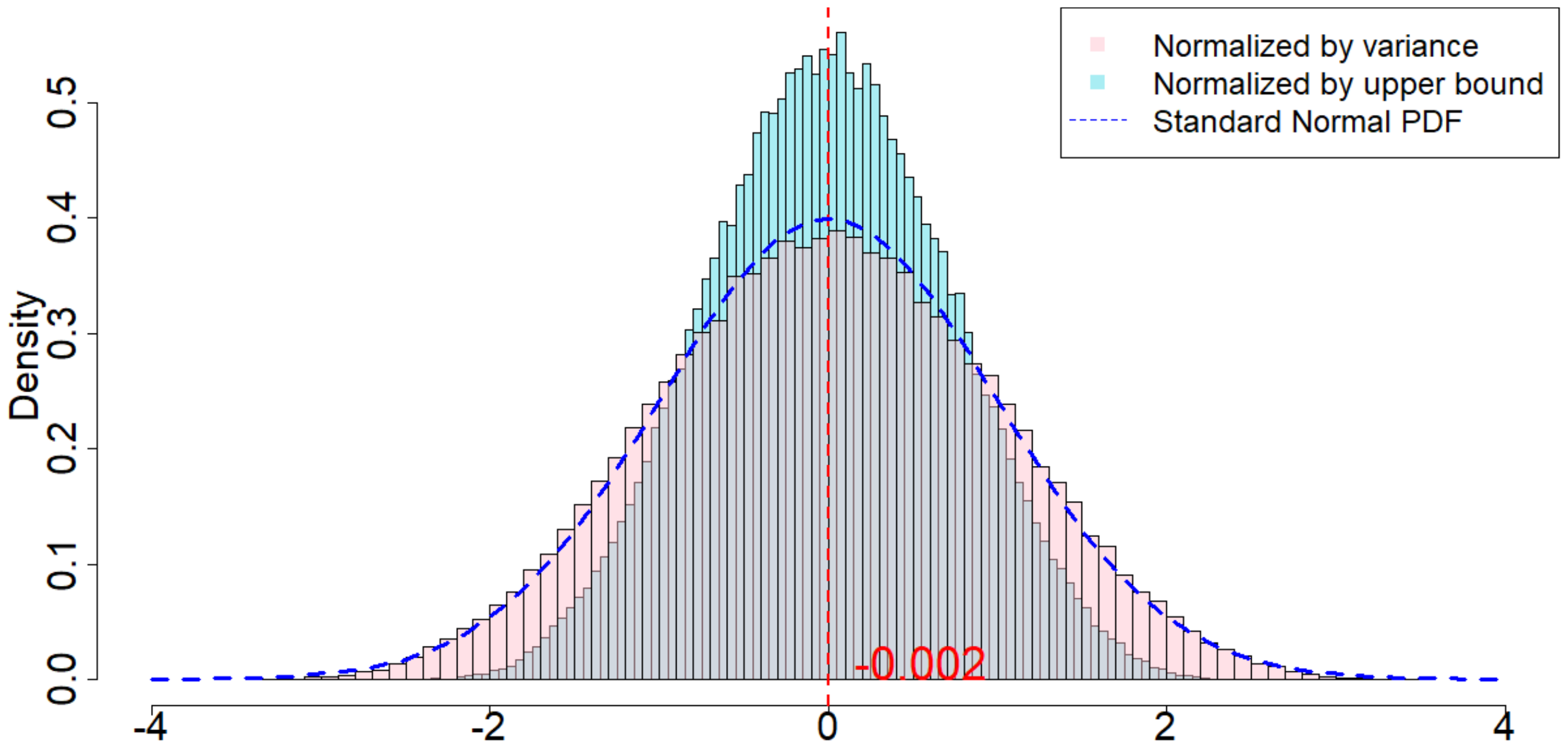
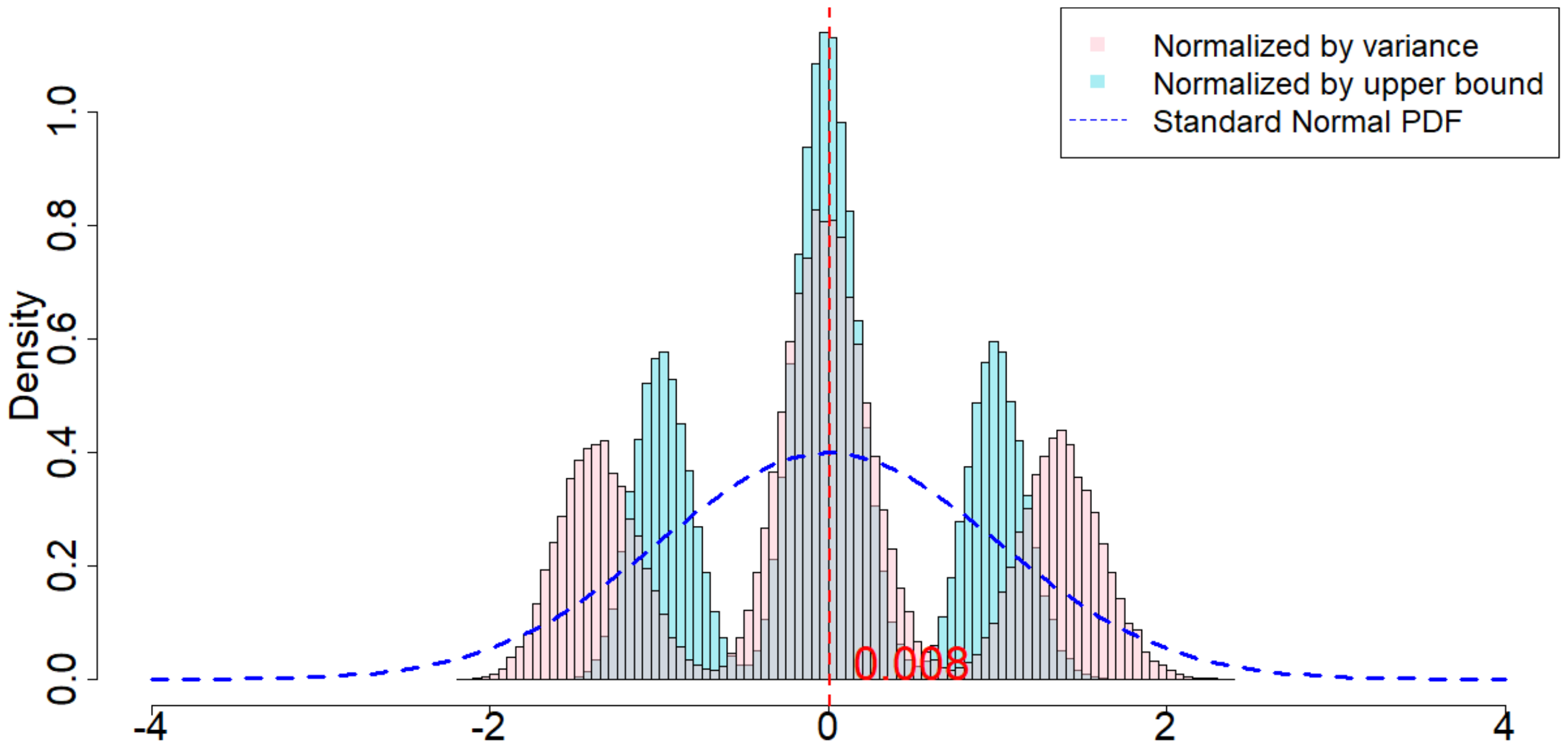
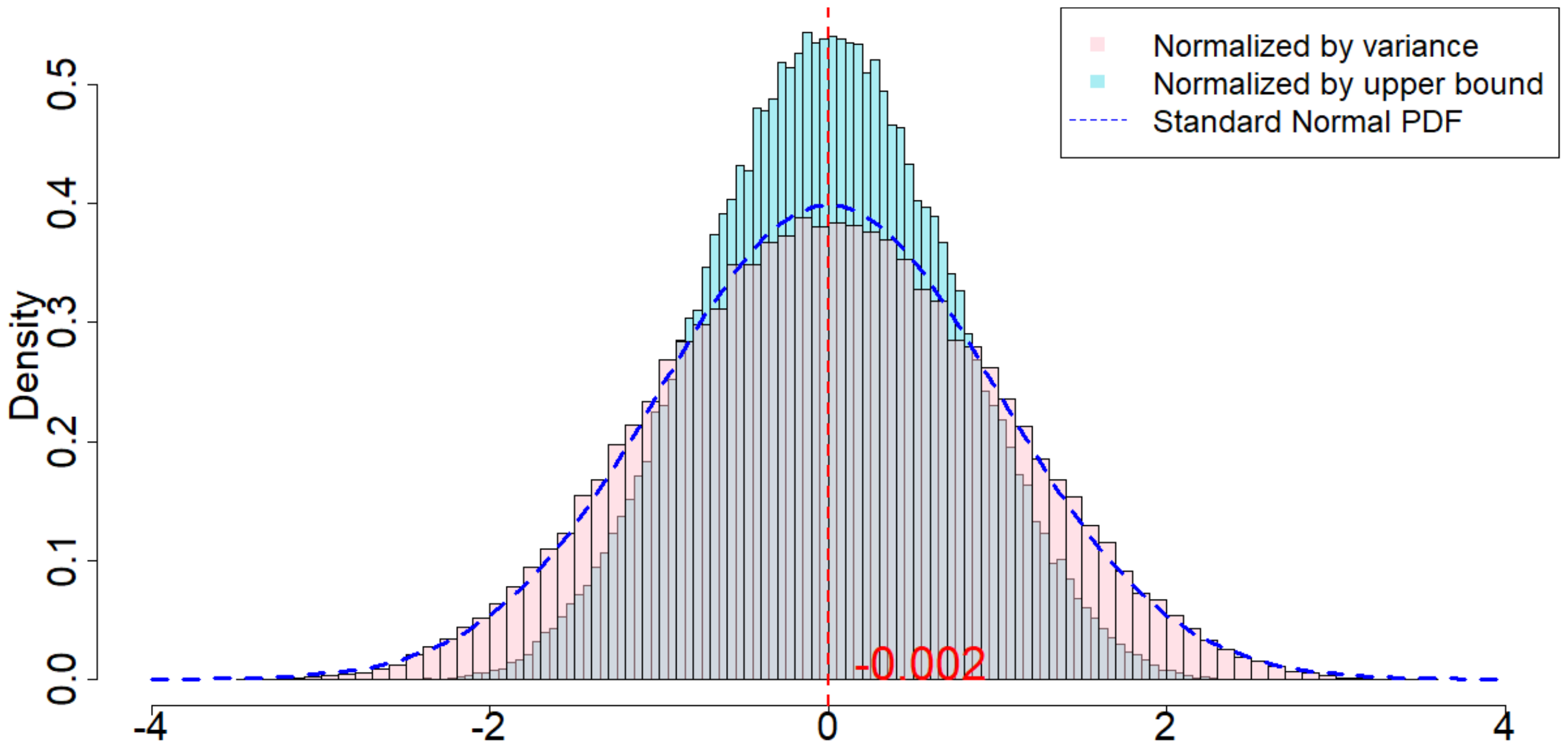
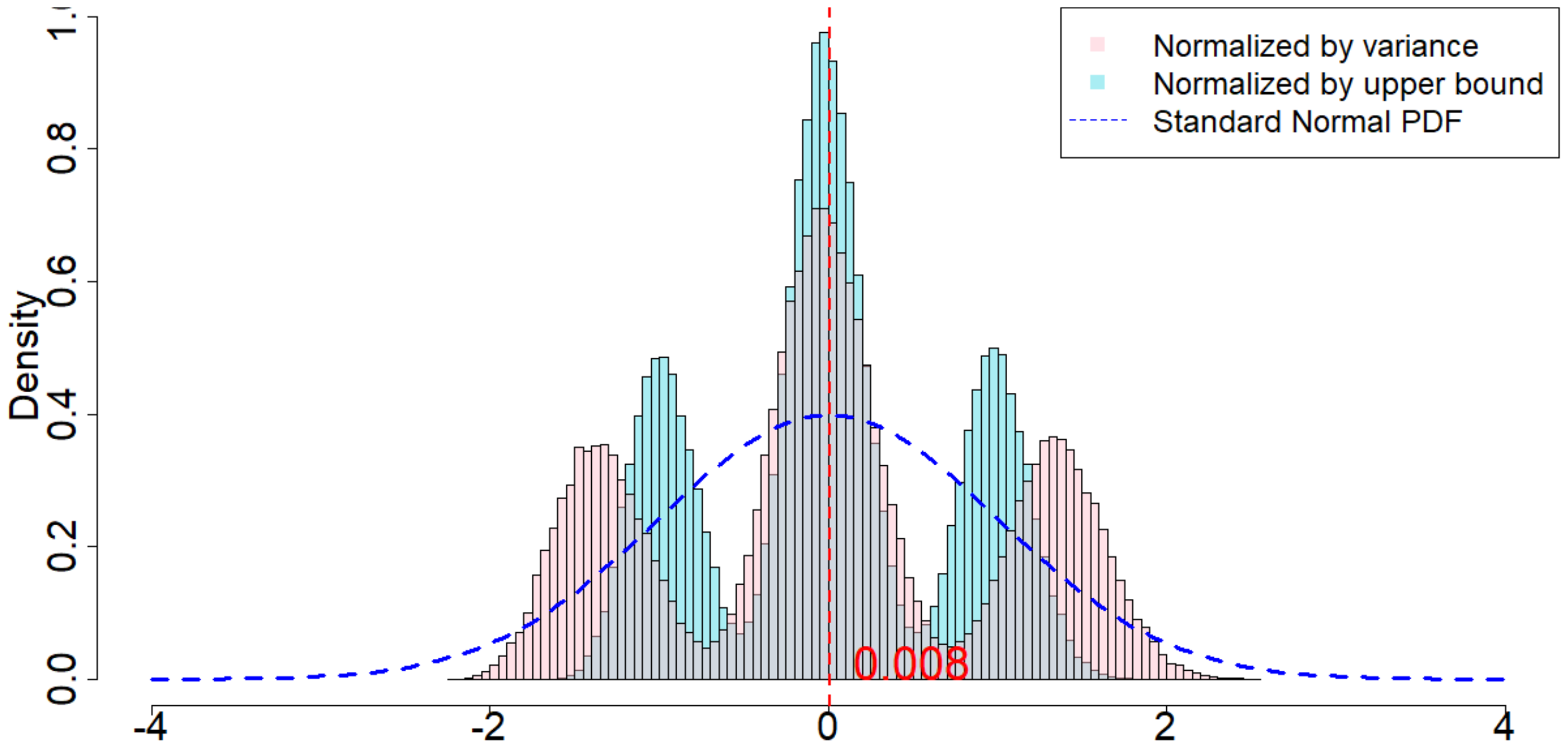
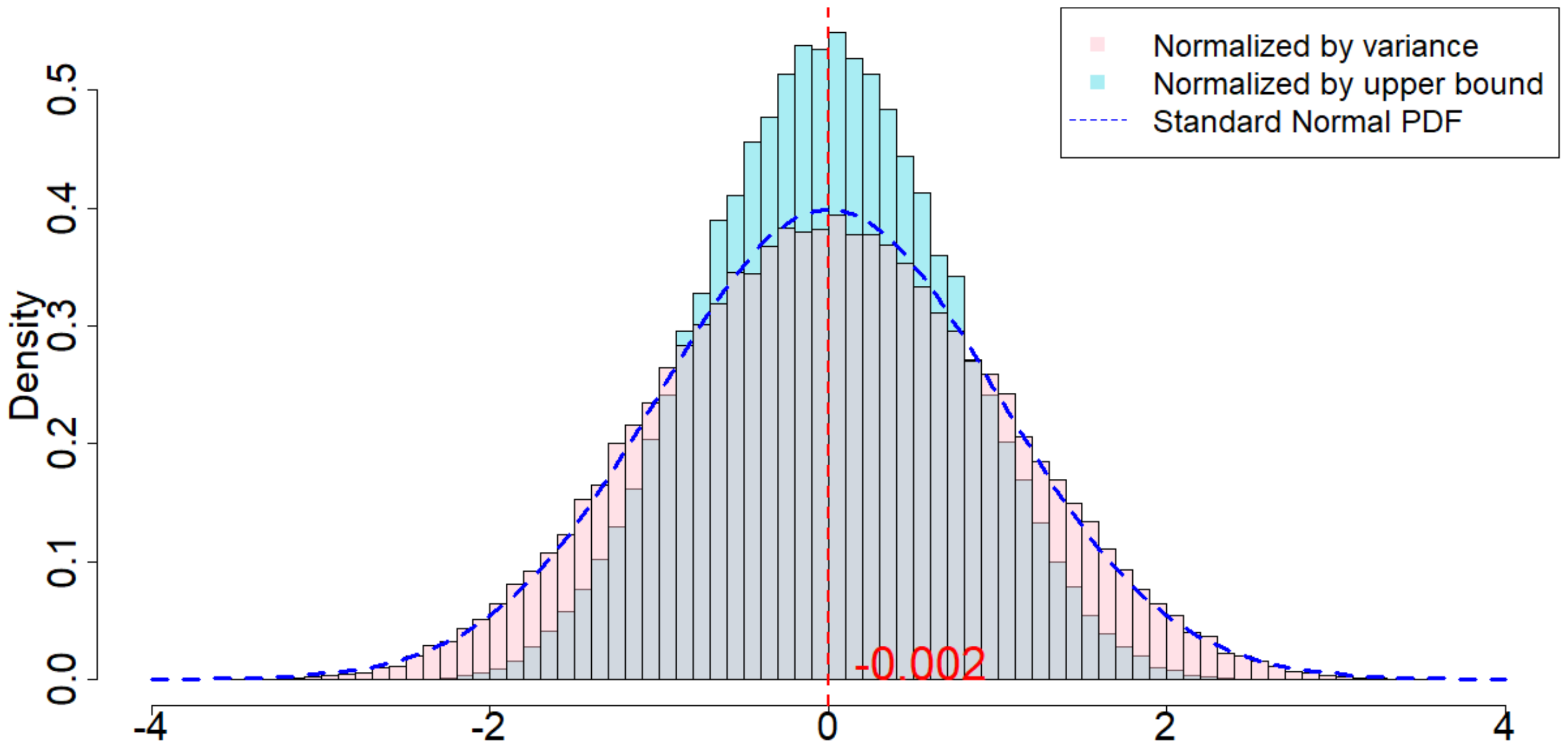
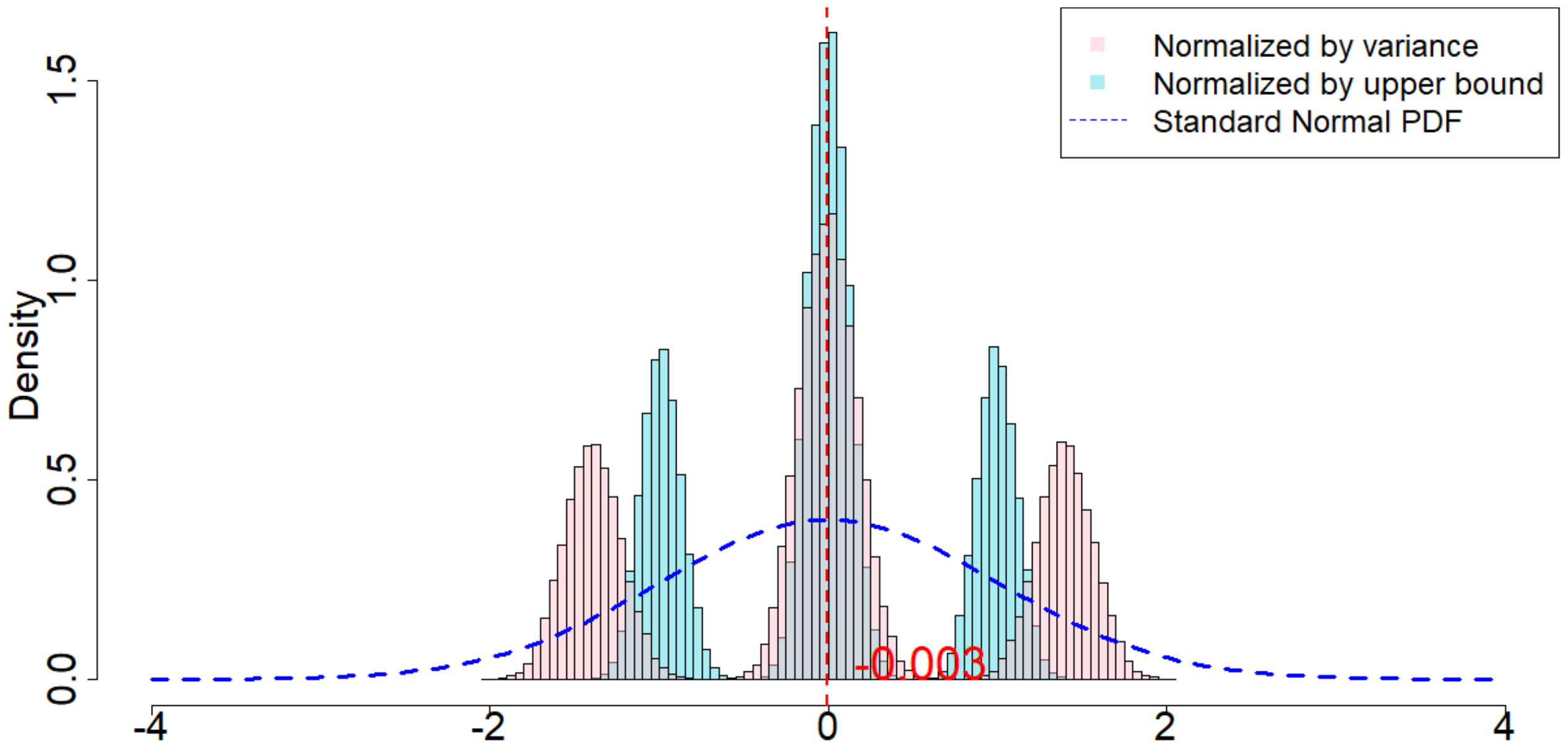
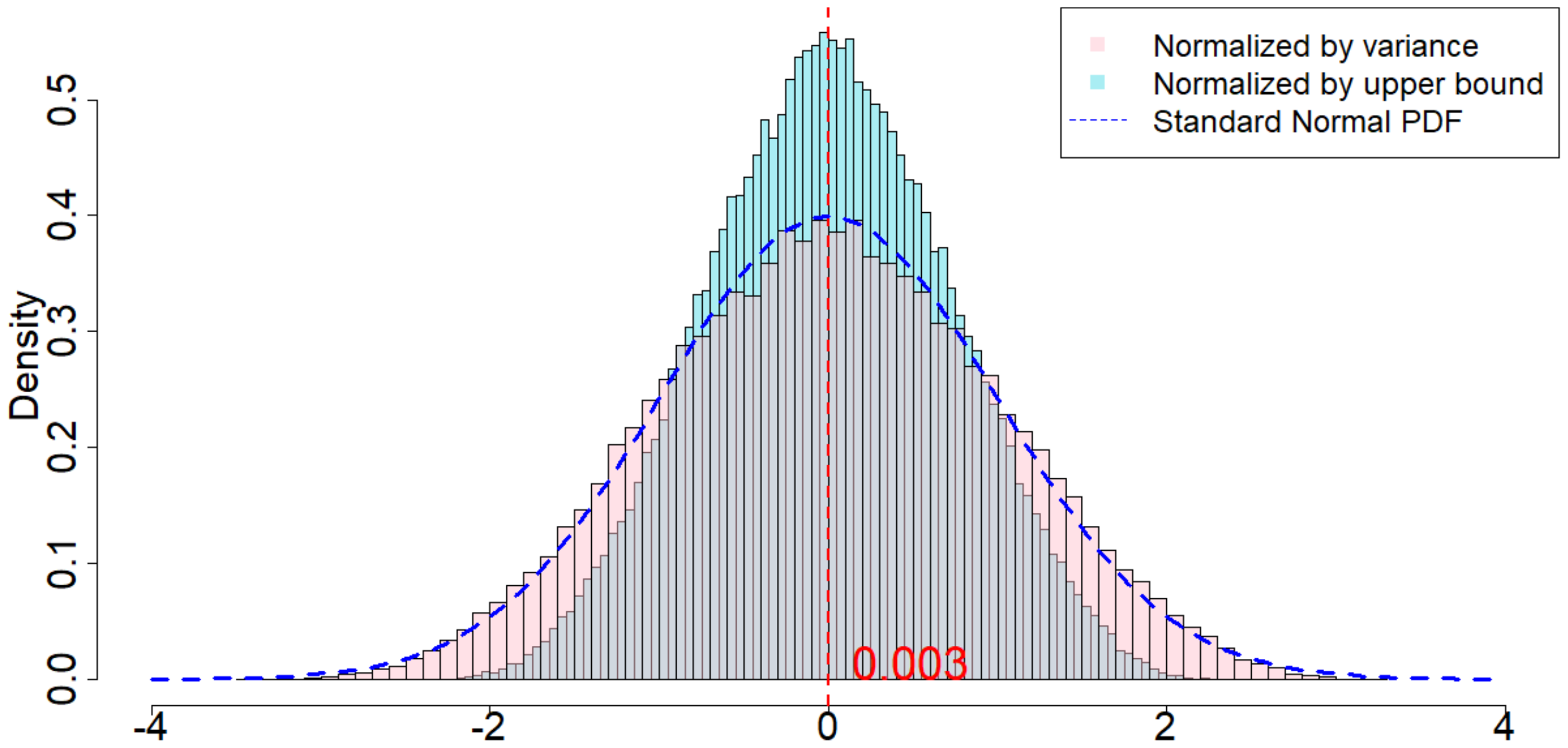
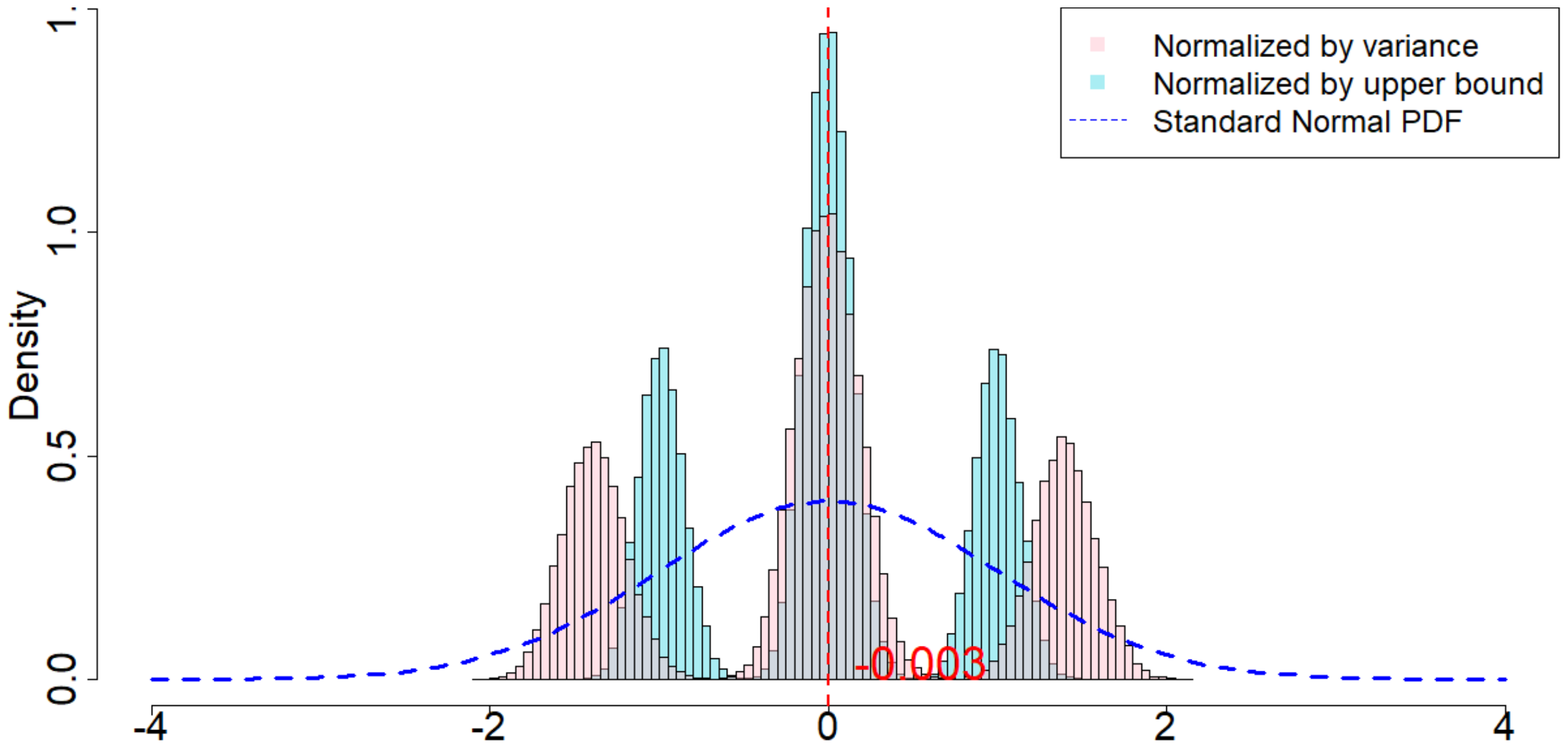
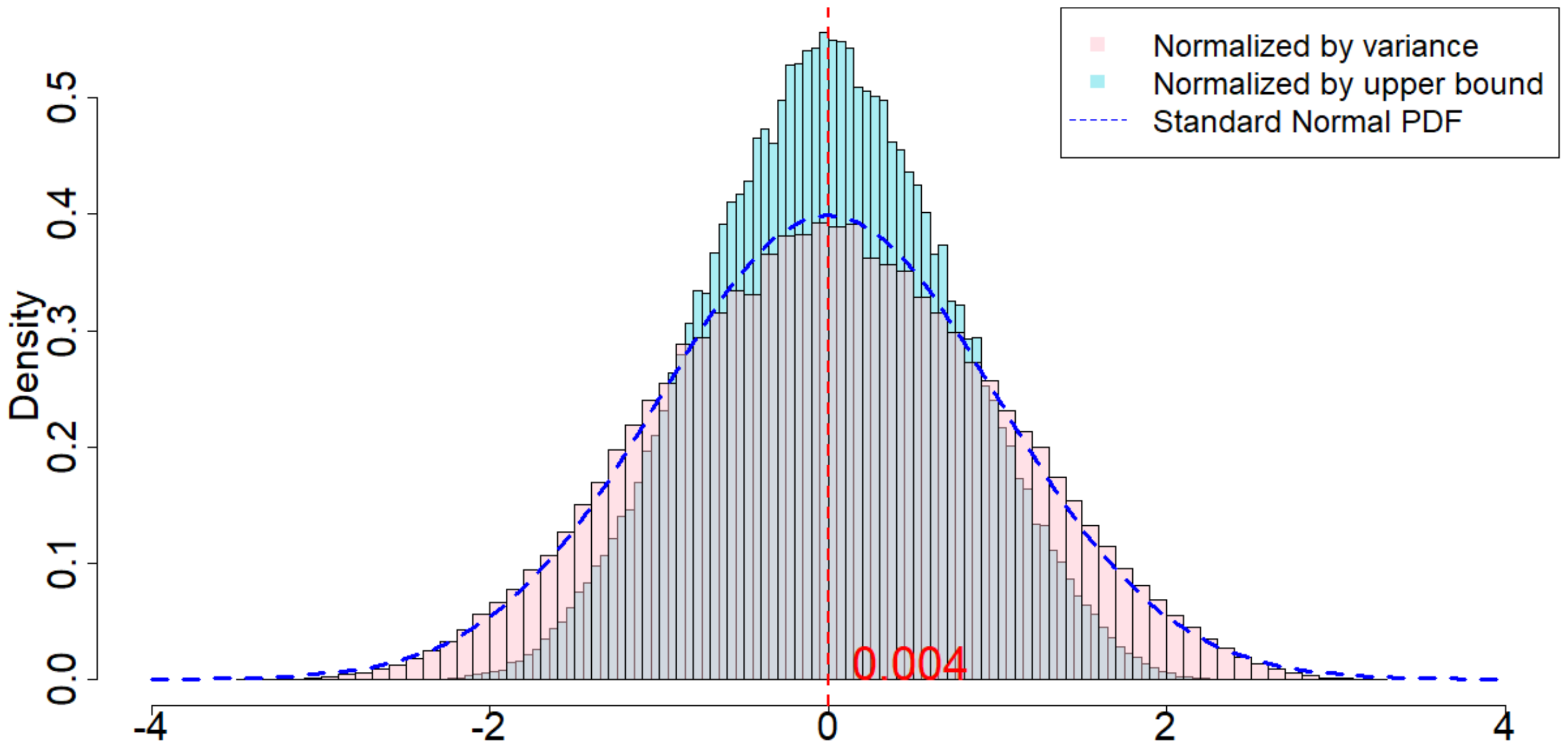
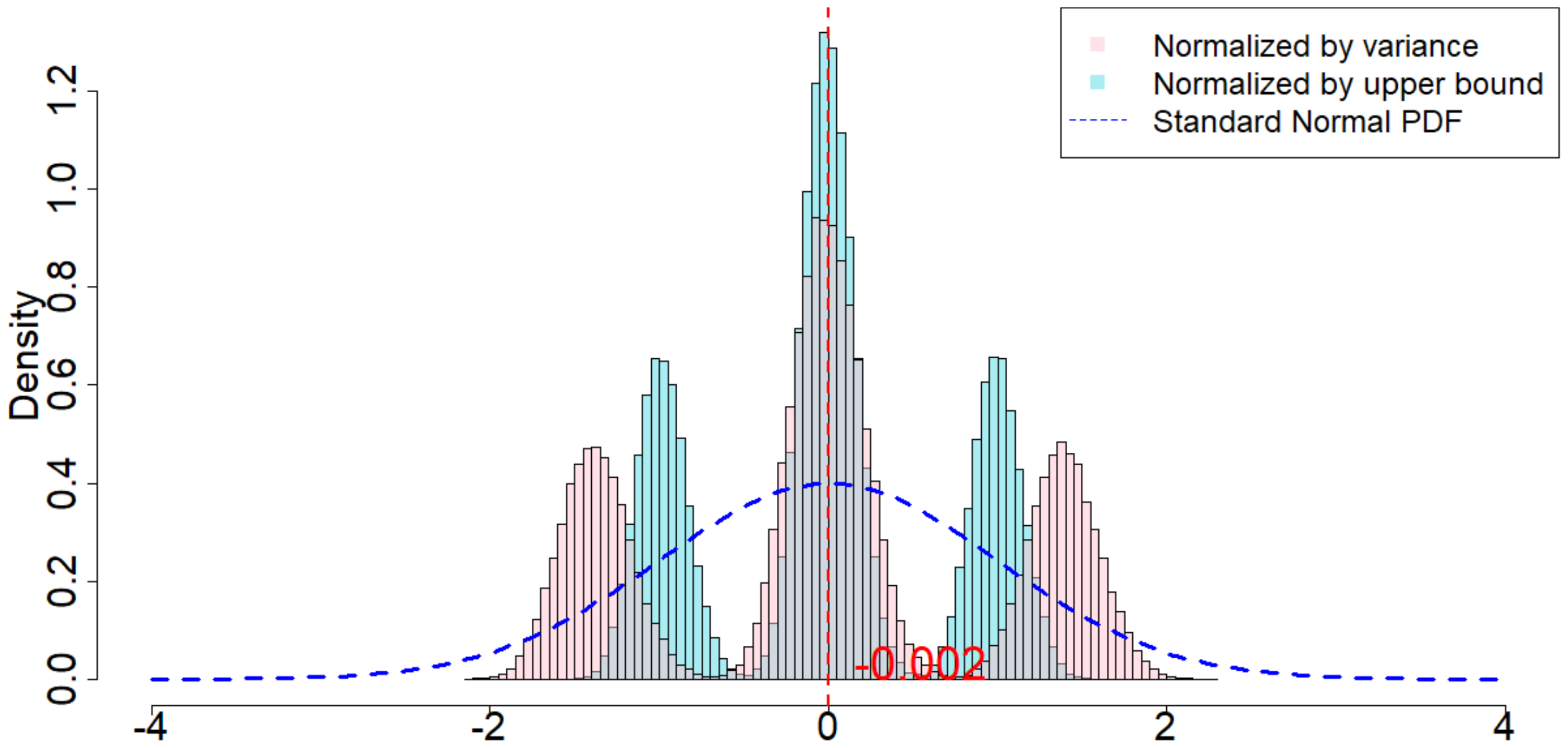
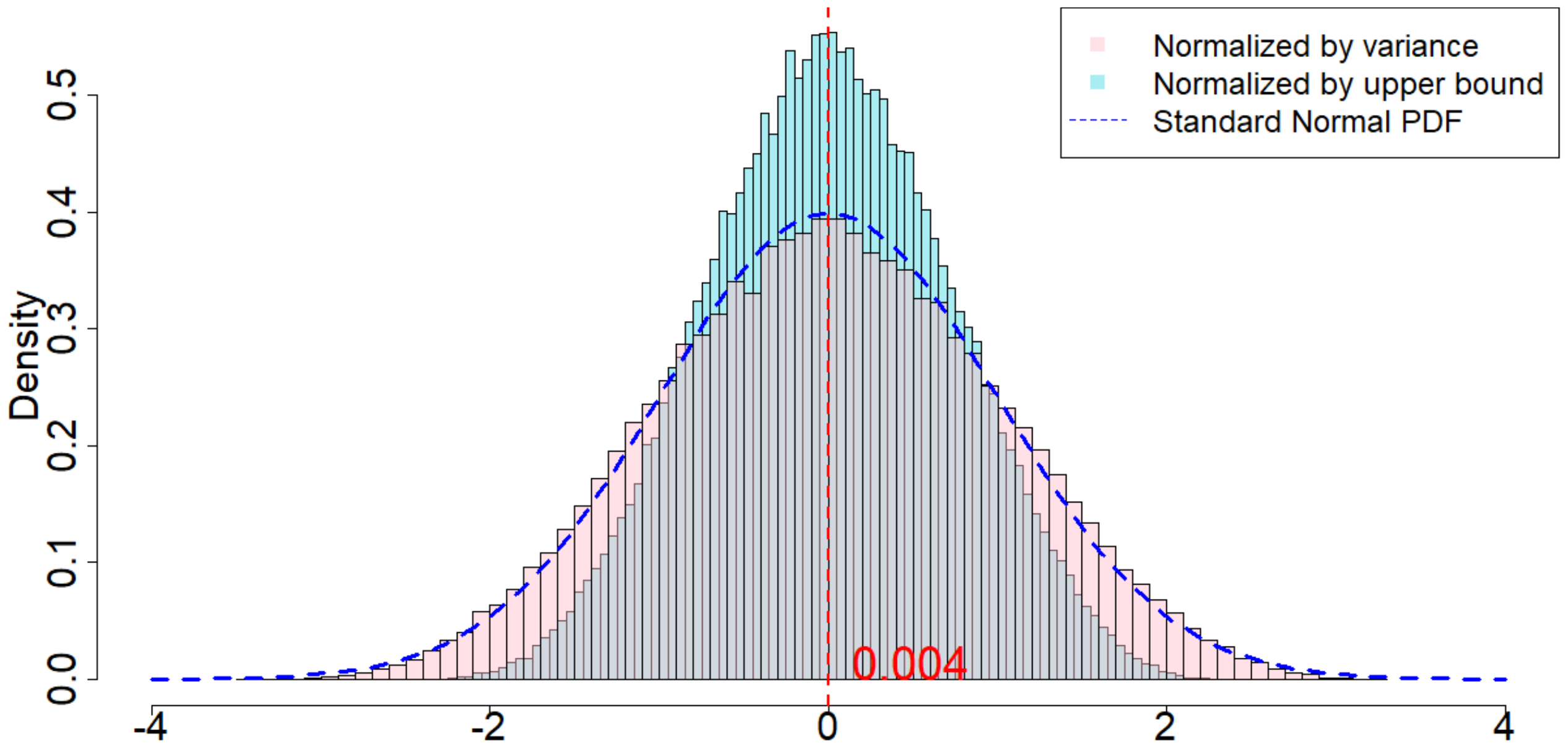
11.10 Additional Simulation Results for Section 5.3 Rejection Rates
In Section 5.3 we have provided simulation results for the rejection rates when the rejection threshold is $0.1$. In this section we provide additional simulation results for the rejection rates when the rejection threshold is replaced by $0.05$ and $0.01$. See Figure 33 and Figure 34.
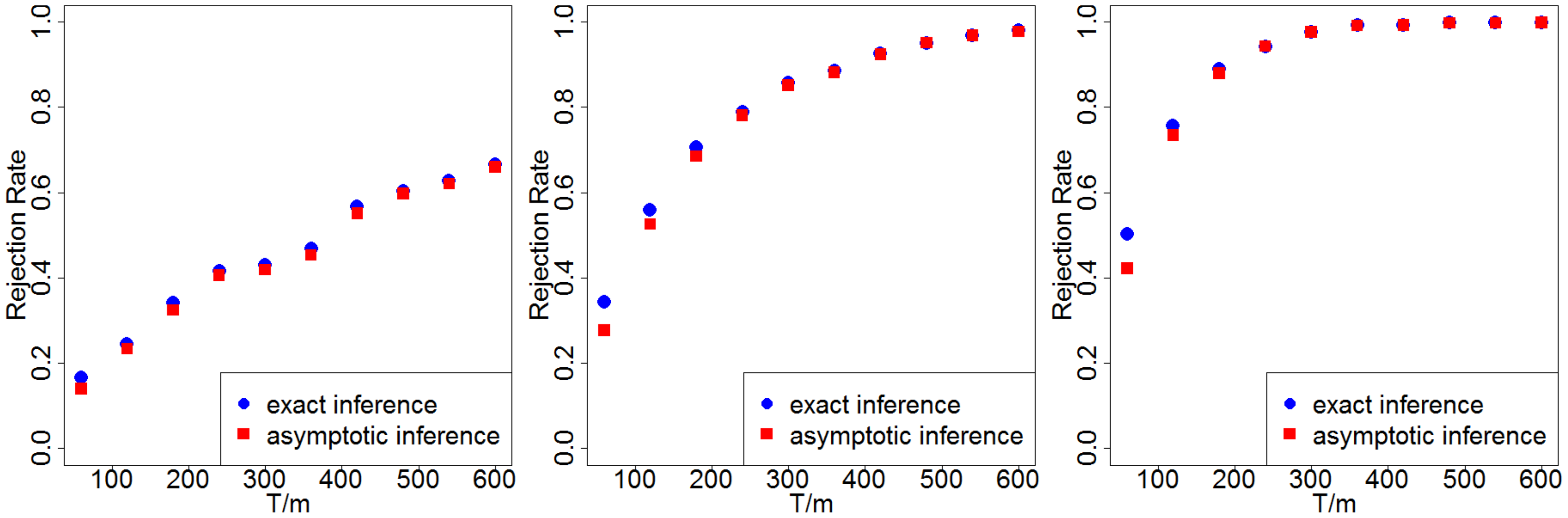
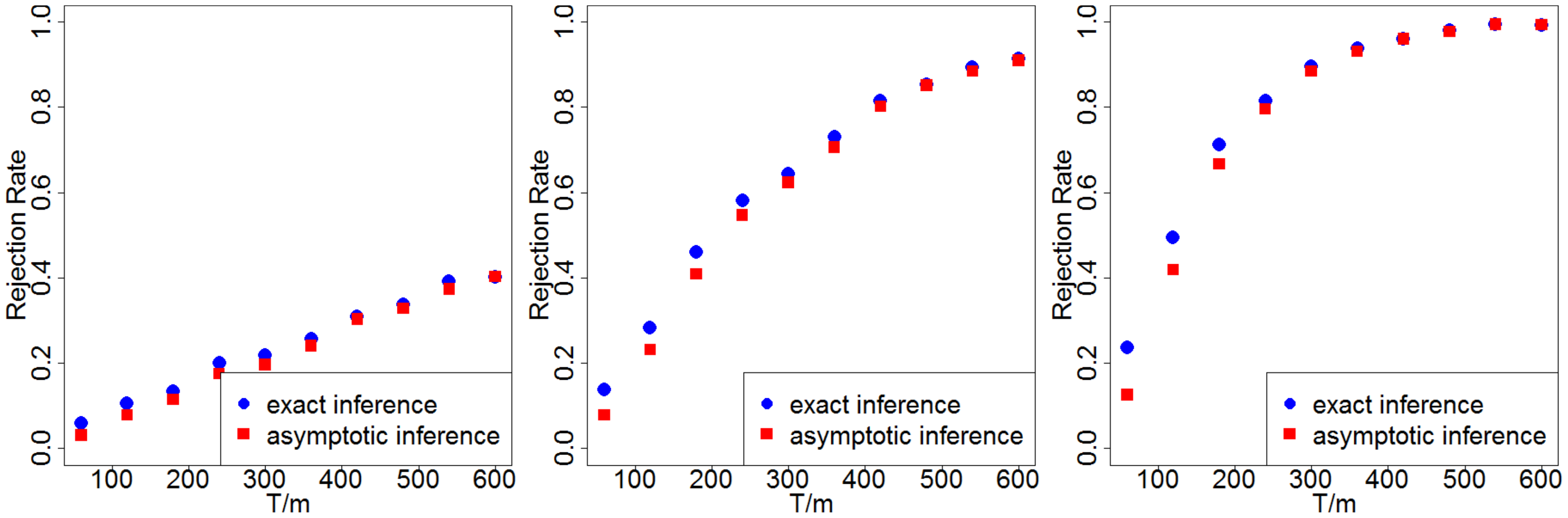
The blue dots are rejection rates under exact inference; the red dots are under asymptotic inference. Similar to the simulation results in Section 5.3, we would ideally wish to reject both the Fisher's null hypothesis Equation 8 and the Neyman's null hypothesis Equation 9. Both figures illustrate such rejection rates.
Besides the three observations we make in Section 5.3 (namely, dependence on $T/m$, between two inference methods, and dependence on the signal-to-noise ratio), we make an extra observation here. When we decrease the rejection threshold, we expect to reject the Neyman's null hypothesis under smaller $p$-values. As a result, as we decrease the rejection threshold, the rejection rates should be smaller, which is supported by our simulation results in Figure 33 and Figure 34.
References
Section Summary: This references section compiles a wide array of academic papers, books, and articles focused on experimentation as a key tool for business innovation and decision-making. It covers topics like organizational learning through exploration and failure, the design of online A/B tests to measure customer behavior, and practical applications in companies such as Microsoft, Lyft, Uber, and Airbnb, including strategies for pricing, inventory, and handling biases in marketplace experiments. The sources also delve into statistical methods for accurate inference in adaptive and sequential testing, emphasizing real-world evidence from field studies and theoretical advancements.
[1] March JG (1991) Exploration and exploitation in organizational learning. Organization science 2(1):71–87.
[2] Sitkin SB (1992) Learning through failure: The strategy of small losses. Research in organizational behavior 14:231–266.
[3] Sarasvathy SD (2001) Causation and effectuation: Toward a theoretical shift from economic inevitability to entrepreneurial contingency. Academy of management Review 26(2):243–263.
[4] Thomke S (2001) Enlightened experimentation. the new imperative for innovation. Harvard Business Review 79(2):66–75.
[5] Johari R, Pekelis L, Walsh DJ (2015) Always valid inference: Bringing sequential analysis to a/b testing. arXiv preprint arXiv:1512.04922 .
[6] Kohavi R, Thomke S (2017) The surprising power of online experiments. Harvard Business Review 95:74–82.
[7] Sun T, Viswanathan S, Huang N, Zheleva E (2018) Designing promotional incentive to embrace social sharing: Evidence from field and lab experiments. Available at SSRN 3095094 .
[8] Xiong R, Athey S, Bayati M, Imbens GW (2019) Optimal experimental design for staggered rollouts. Available at SSRN .
[9] Kohavi R, Henne RM, Sommerfield D (2007) Practical guide to controlled experiments on the web: listen to your customers not to the hippo. Proceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining, 959–967.
[10] Kohavi R, Crook T, Longbotham R, Frasca B, Henne R, Ferres JL, Melamed T (2009) Online experimentation at microsoft. Data Mining Case Studies 11(2009):39.
[11] Bakshy E, Eckles D, Bernstein MS (2014) Designing and deploying online field experiments. Proceedings of the 23rd international conference on World wide web, 283–292.
[12] Azevedo EM, Alex D, Montiel Olea J, Rao JM, Weyl EG (2019) A/b testing with fat tails. Available at SSRN 3171224 .
[13] Kohavi R, Tang D, Xu Y (2020) Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing (Cambridge University Press).
[14] Thomke SH (2020) Experimentation Works: The Surprising Power of Business Experiments (Harvard Business Press).
[15] Koning R, Hasan S, Chatterji A (2019) Experimentation and startup performance: Evidence from a/b testing. Technical report, National Bureau of Economic Research.
[16] Gupta S, Kohavi R, Tang D, Xu Y, Andersen R, Bakshy E, Cardin N, Chandran S, Chen N, Coey D, et al. (2019) Top challenges from the first practical online controlled experiments summit. ACM SIGKDD Explorations Newsletter 21(1):20–35.
[17] Bojinov I, Saint-Jacques G, Tingley M (2020) Avoid the pitfalls of a/b testing make sure your experiments recognize customers' varying needs. Harvard Business Review 98(2):48–53.
[18] Chamandy N (2016) Experimentation in a ridesharing marketplace lyft engineering. URL: https://eng.lyft.com/experimentation-in-a-ridesharing-marketplace-b39db027a66e .
[19] Cui R, Li J, Zhang D (2017) Discrimination with incomplete information in the sharing economy: Evidence from field experiments on airbnb. Harvard Business School 1–35.
[20] Kastelman D, Ramesh R (2018) Switchback tests and randomized experimentation under network effects at doordash. URL: https://medium.com/@DoorDash/switchback-tests-and-randomized-experimentation-under-network-effects-at-doordash-f1d938ab7c2a .
[21] Farronato C, MacCormack A, Mehta S (2018) Innovation at uber: The launch of express pool. Harvard Business School Case 620(062).
[22] Glynn P, Johari R, Rasouli M (2020) Adaptive experimental design with temporal interference: A maximum likelihood approach. arXiv preprint arXiv:2006.05591 .
[23] Holtz D, Lobel R, Liskovich I, Aral S (2020) Reducing interference bias in online marketplace pricing experiments. arXiv preprint arXiv:2004.12489 .
[24] Li H, Zhao G, Johari R, Weintraub GY (2021) Interference, bias, and variance in two-sided marketplace experimentation: Guidance for platforms. arXiv preprint arXiv:2104.12222 .
[25] Caro F, Gallien J (2012) Clearance pricing optimization for a fast-fashion retailer. Operations Research 60(6):1404–1422.
[26] Ferreira KJ, Lee BHA, Simchi-Levi D (2016) Analytics for an online retailer: Demand forecasting and price optimization. Manufacturing & Service Operations Management 18(1):69–88.
[27] Cui R, Zhang DJ, Bassamboo A (2019) Learning from inventory availability information: Evidence from field experiments on amazon. Management Science 65(3):1216–1235.
[28] Ma W, Simchi-Levi D, Zhao J (2020) Dynamic pricing (and assortment) under a static calendar. Management Science .
[29] Nie X, Tian X, Taylor J, Zou J (2018) Why adaptively collected data have negative bias and how to correct for it. International Conference on Artificial Intelligence and Statistics, 1261–1269.
[30] Deshpande Y, Mackey L, Syrgkanis V, Taddy M (2018) Accurate inference for adaptive linear models. International Conference on Machine Learning, 1194–1203 (PMLR).
[31] McFowland III E, Somanchi S, Neill DB (2018) Efficient discovery of heterogeneous treatment effects in randomized experiments via anomalous pattern detection. arXiv preprint arXiv:1803.09159 .
[32] Hadad V, Hirshberg DA, Zhan R, Wager S, Athey S (2019) Confidence intervals for policy evaluation in adaptive experiments. arXiv preprint arXiv:1911.02768 .
[33] Robins J (1986) A new approach to causal inference in mortality studies with a sustained exposure period—application to control of the healthy worker survivor effect. Mathematical Modelling 7(9-12):1393–1512.
[34] Bojinov I, Shephard N (2019) Time series experiments and causal estimands: exact randomization tests and trading. Journal of the American Statistical Association 114(528):1665–1682.
[35] Wager S, Xu K (2019) Experimenting in equilibrium. arXiv preprint arXiv:1903.02124 .
[36] Johari R, Li H, Weintraub G (2020) Experimental design in two-sided platforms: An analysis of bias. arXiv preprint arXiv:2002.05670 .
[37] Li JQ, Rusmevichientong P, Simester D, Tsitsiklis JN, Zoumpoulis SI (2015) The value of field experiments. Management Science 61(7):1722–1740.
[38] Athey S, Eckles D, Imbens GW (2018) Exact p-values for network interference. Journal of the American Statistical Association 113(521):230–240.
[39] Eckles D, Karrer B, Ugander J (2016) Design and analysis of experiments in networks: Reducing bias from interference. Journal of Causal Inference 5(1).
[40] Sussman DL, Airoldi EM (2017) Elements of estimation theory for causal effects in the presence of network interference. arXiv preprint arXiv:1702.03578 .
[41] Basse G, Ding P, Feller A, Toulis P (2019a) Randomization tests for peer effects in group formation experiments. arXiv preprint arXiv:1904.02308 .
[42] Puelz D, Basse G, Feller A, Toulis P (2019) A graph-theoretic approach to randomization tests of causal effects under general interference. arXiv preprint arXiv:1910.10862 .
[43] Lillie EO, Patay B, Diamant J, Issell B, Topol EJ, Schork NJ (2011) The n-of-1 clinical trial: the ultimate strategy for individualizing medicine? Personalized medicine 8(2):161–173.
[44] Boruvka A, Almirall D, Witkiewitz K, Murphy SA (2018) Assessing time-varying causal effect moderation in mobile health. Journal of the American Statistical Association 113(523):1112–1121.
[45] Chamberlain G (1982) Multivariate regression models for panel data. Journal of econometrics 18(1):5–46.
[46] Athey S, Imbens GW (2018) Design-based analysis in difference-in-differences settings with staggered adoption. Technical report, National Bureau of Economic Research.
[47] Imai K, Kim IS (2019) When Should We Use Unit Fixed Effects Regression Models for Causal Inference with Longitudinal Data? American Journal of Political Science 63(2):467–490, http://dx.doi.org/10.1111/ajps.12417.
[48] Sobel ME (2012) Does Marriage Boost Men's Wages?: Identification of Treatment Effects in Fixed Effects Regression Models for Panel Data. Journal of the American Statistical Association 107(498):521–529, http://dx.doi.org/10.1080/01621459.2011.646917.
[49] Bojinov I, Rambachan A, Shephard N (2021) Panel experiments and dynamic causal effects: A finite population perspective. Quantitative Economics (forthcoming).
[50] Fisher RA, et al. (1937) The design of experiments. The design of experiments. (2nd Ed).
[51] Kempthorne O (1955) The randomization theory of experimental inference. Journal of the American Statistical Association 50(271):946–967, ISSN 01621459, http://www.jstor.org/stable/2281178.
[52] Rubin DB (1980) Randomization analysis of experimental data: The fisher randomization test comment. Journal of the American statistical association 75(371):591–593.
[53] Abadie A, Athey S, Imbens GW, Wooldridge JM (2020) Sampling-based versus design-based uncertainty in regression analysis. Econometrica 88(1):265–296.
[54] Imbens GW, Rubin DB (2015) Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction (Cambridge University Press), http://dx.doi.org/10.1017/CBO9781139025751.
[55] Neyman J (1923) On the application of probability theory to agricultural experiments. essay on principles. section 9. masters thesis. portion translated by d. dabrowska and t. speed (1990). Statistical Science 465–472.
[56] Basse G, Ding Y, Toulis P (2019b) Minimax crossover designs. arXiv preprint arXiv:1908.03531 .
[57] Rambachan A, Shephard N (2019) Econometric analysis of potential outcomes time series: instruments, shocks, linearity and the causal response function. arXiv preprint arXiv:1903.01637 .
[58] Laird NM, Skinner J, Kenward M (1992) An analysis of two-period crossover designs with carry-over effects. Statistics in Medicine 11(14-15):1967–1979.
[59] Senn S, Lambrou D (1998) Robust and realistic approaches to carry-over. Statistics in Medicine 17(24):2849–2864.
[60] Garg N, Nazerzadeh H (2019) Driver surge pricing. arXiv preprint arXiv:1905.07544 .
[61] Wu CF (1981) On the robustness and efficiency of some randomized designs. The Annals of Statistics 1168–1177.
[62] Li KC (1983) Minimaxity for randomized designs: some general results. The Annals of Statistics 11(1):225–239.
[63] Bai Y (2019) Optimality of matched-pair designs in randomized control trials. Available at SSRN 3483834 .
[64] Harshaw C, Sävje F, Spielman D, Zhang P (2019) Balancing covariates in randomized experiments using the gram-schmidt walk. arXiv preprint arXiv:1911.03071 .
[65] Berger JO (2013) Statistical decision theory and Bayesian analysis (Springer Science & Business Media).
[66] Bickel PJ, Doksum KA (2015) Mathematical statistics: basic ideas and selected topics, volume I, volume 117 (CRC Press).
[67] Aronow PM, Samii C, et al. (2017) Estimating average causal effects under general interference, with application to a social network experiment. The Annals of Applied Statistics 11(4):1912–1947.
[68] Chin A (2018) Central limit theorems via Stein's method for randomized experiments under interference. arXiv e-prints arXiv:1804.03105.
[69] Li X, Ding P, Rubin DB, et al. (2020) Rerandomization in $2^k$ factorial experiments. The Annals of Statistics 48(1):43–63.
[70] Han KW, Bojinov I, Basse G (2021) Population interference in panel experiments .
[71] Li X, Ding P (2017) General forms of finite population central limit theorems with applications to causal inference. Journal of the American Statistical Association 112(520):1759–1769.
[72] Oman SD, Seiden E (1988) Switch-back designs. Biometrika 75(1):81–89.
[73] Hedayat A, Afsarinejad K, et al. (1978) Repeated measurements designs, ii. The Annals of Statistics 6(3):619–628.
[74] Jones B, Kenward MG (2014) Design and analysis of cross-over trials (CRC press).
[75] Hoeffding W, Robbins H (1948) The central limit theorem for dependent random variables. Duke Mathematical Journal 15(3):773–780.
[76] Romano JP, Wolf M (2000) A more general central limit theorem for m-dependent random variables with unbounded m. Statistics & probability letters 47(2):115–124.
[77] Arellano M (2003) Panel data econometrics (Oxford university press).
[78] Bojinov I, Shephard N (2018) Time series experiments and causal estimands: exact randomization tests and trading. Journal of the American Statistical Association (just-accepted).